この記事は Ateam Lifestyle Inc. Advent Calendar 2021 16日目の記事です。
最近、因果推論を勉強中です。今回は因果推論と機械学習を用いてユーザー毎の効果を推定し、決定木でその効果を可視化するという手法を試してみたいと思います。
理論の詳しい内容には触れていませんが、こんなことできるんだというのが伝わるとよいなと思っています。
因果推論について
因果推論はある施策を行ったときに、その効果を推定するための手法になります。
それABテストでよいのでは?と思われるかもしれませんが、ABテストが使えない場面で効果が測れるのが因果推論です。
今回扱う 岩波データサイエンス Vol.3 の中の例でいくと、アプリのテレビCMを打ったときに、CMを見た人がアプリの利用時間が増えたのかどうかを測りたいのですが、CMを見る人はABテストのようにランダムには決まっていません。
そして単純にCMを見た人と見てない人で利用時間を比べると、見てない人のほうが利用時間が長いという予想に反した結果になっていたようです。
ただ、これはCMを見た人と見ていない人で年齢やテレビ視聴時間などのユーザー属性の分布が異なっているというバイアスが存在するためであり、バイアスを取り除いて比較することで効果が推定できます。
この例ではバイアスを取り除くことで、CMを見た人のほうがアプリ利用時間が長くなるという推定結果が出ています。
EconMLについて
因果推論では、ユーザー全体に対して施策の効果があったかどうかの平均値が推定できます。CMの例だと、CMを見たことによってアプリの利用時間がどれだけ長くなったかの平均値を推定しています。
因果推論と機械学習を組み合わせることで、平均値だけでなくユーザー毎の効果を推定することができる手法があり、それが実装されているのがMicrosoftが開発している EconML というライブラリです。
ユーザー毎に効果が推定できると、効果がある人とない人に合わせて施策を変えるということができそうです。
これはABテストに対しても有効で、ABテストはAとBの平均効果の差はわかりますが、ユーザー毎の効果はわかりません。
今回は触れませんがABテストに対してもユーザ毎の効果が推定できるようです。
ユーザー毎の効果推定
前置きはここまでで、実際にCMの例のデータを使って効果を推定していきます。
効果推定の手法はいろいろとあるようですが、今回はMeta-Learnersという手法を試してみます。
Meta-Learnersの理論については、つくりながら学ぶ! Pythonによる因果分析 で勉強中です。
Meta-Learnersにはいくつか種類があるのですが、ここではX-Learnerを利用しています。
コードについてはEconMLのサンプルコードを参考にしています。
https://github.com/microsoft/EconML/blob/master/notebooks/Metalearners%20Examples.ipynb
また今回のデータでMeta-Learnersを試している方がいらしたのでそちらも参考にしています。
岩波データサイエンスvol.3のCM接触の因果効果を他の方法で推定してみた(3)
まず必要なライブラリをインポートしていきます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from econml.metalearners import XLearner
from sklearn.ensemble import RandomForestClassifier, GradientBoostingRegressor
from sklearn.model_selection import train_test_split
次にデータをダウンロードして学習データとテストデータに分けます。
filepath = "https://raw.githubusercontent.com/iwanami-datascience/vol3/master/kato%26hoshino/q_data_x.csv"
df = pd.read_csv(filepath)
X = df[['area_kanto', 'area_tokai', 'area_keihanshin', 'age', 'sex', 'marry_dummy',
'job_dummy1', 'job_dummy2', 'job_dummy3', 'job_dummy4', 'job_dummy5',
'job_dummy6', 'job_dummy7', 'inc', 'pmoney', 'fam_str_dummy1', 'fam_str_dummy2',
'fam_str_dummy3', 'fam_str_dummy4', 'child_dummy', 'TVwatch_day']]
Y = df['gamesecond']
T = df['cm_dummy']
X_train, X_test, Y_train, Y_test, T_train, T_test = train_test_split(X, Y, T, test_size=0.2, shuffle=True, random_state=42, stratify=T)
Y.describe()
count 10000.000000
mean 2846.783400
std 17973.608991
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 364814.000000
Name: gamesecond, dtype: float64
T.value_counts()
0 5856
1 4144
Name: cm_dummy, dtype: int64
今回の施策であるCMを見たかどうかが変数Tに入っており、効果を測りたいアプリの利用時間をYに入れています。
データ数は10,000件で、利用時間の大半は0秒のようです。
CMを見たかどうかは見てない人が少し多いようです。
Xがユーザーの属性になるわけですが、書籍と照らし合わせてみると
- 地域(area_xxx)
- 年齢(age)
- 性別(sex)
- 年収(inc)
- 1日あたりのテレビ視聴秒数(TVwatch_day)
などがあるようです。
次にユーザー毎の効果を推定します。
# Instantiate X learner
n = len(X_test)
models = GradientBoostingRegressor(n_estimators=100, max_depth=6, min_samples_leaf=int(n/100))
propensity_model = RandomForestClassifier(n_estimators=100, max_depth=6,
min_samples_leaf=int(n/100))
X_learner = XLearner(models=models, propensity_model=propensity_model)
# Train X_learner
X_learner.fit(Y_train, T_train, X=X_train)
# Estimate treatment effects on test data
X_te = X_learner.effect(X_test)
print("ATE of X-learner: ", round(np.mean(X_te), 2))
> ATE of X-learner: 931.54
学習データでモデルを学習し、テストデータのユーザー毎の推定値を算出しています。
平均の効果ではアプリの利用時間が931秒伸びたと推定しており、書籍と同様にプラスの効果がありそうです。
ユーザー毎の効果をヒストグラムで見てみます。
pd.Series(X_te).hist(bins=100)
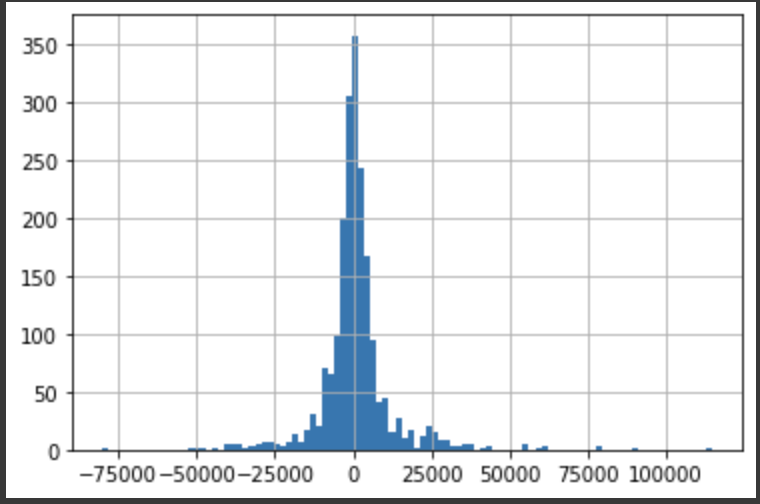
縦軸がユーザー数で横軸が効果の秒数です。
効果がマイナスの人のほうが多いようにも見えますが、平均するとプラスのようです。
決定木を使った効果の可視化
EconMLには決定木を使って効果を可視化する機能があるので試してみます。
可視化することで、どの属性を持った人にプラス/マイナス効果があるのかが見えてくる想定です。
from econml.cate_interpreter import SingleTreeCateInterpreter
intrp = SingleTreeCateInterpreter(max_depth=2, min_samples_leaf=10)
# We interpret the CATE model's behavior based on the features used for heterogeneity
intrp.interpret(X_learner, X_test)
# Plot the tree
plt.figure(figsize=(20, 5))
intrp.plot(feature_names=X_test.columns, fontsize=12)
plt.show()
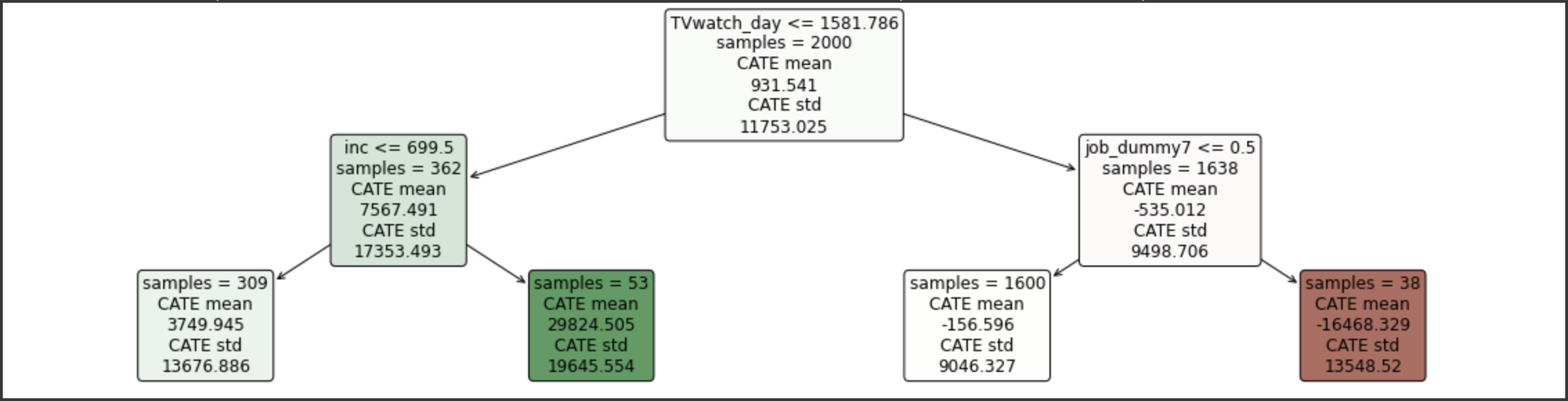
図の見方としては、各ノードの
- 1行目が振り分け条件
- 2行目がユーザー数
- 3, 4行目が効果の平均
- 5, 6行目が効果の標準偏差
になっています。
色については、プラス効果が大きいものが緑、マイナス効果が大きいものが赤くなっています。
2,000件のテストデータのうち、1日のテレビ視聴秒数が短く(TVwatch_dayが1581秒以下)、年収が高い(incが699万円以上)の人が効果が最も大きいと推定しています。
また視聴秒数が長く(TVwatch_dayが1581秒以上)、ある特定の職種(job_dummy7が1)の人が効果が最も小さいと推定しています。
(job_dummyについては書籍で詳細が書かれていませんでしたが、職業の種類だと思われます。)
仮にこの結果に基づいて意思決定をすると、効果が高い人が見るであろう番組にCM出稿をするなどの案が考えられそうですね。
おわりに
今回はサンプルコードをそのまま実行していることもあり、出した推定値は実行するたびに結果が変わっており、どれくらい信頼できる値なのかがわかりませんでした。
データ数が少ないのが原因かもしれませんが、利用する因果推論アルゴリズムや機械学習アルゴリズムの選定、ハイパーパラメータチューニングなども試していく必要がありそうです。
DoWhy というこちらも同じくMicrosoftが開発しているライブラリを併用することで、信頼度が測れるようなのでこちらも見ていきたいと思います。
実務で使うにはまだハードルがありそうですが、ユーザー毎に施策効果の有無が測れることは、様々な場面で役立ちそうな可能性を感じているため、引き続き調査を進めていきたいと思います。
明日は @pyonsomi さんの記事です!お楽しみに!