Ateam Group Manager & Specialist Advent Calendar 2020の5日目は 株式会社エイチームライフスタイルの @yuko1658 が担当します。最近、文章生成を使って何かできないかと企んでおり、今回は日本語の文章要約をやってみました。
Multilingual T5とは
まずT5についてですが、__T__ext-__T__o-__T__ext __T__ransfer __T__ransformerの略で、様々なタスクをText-to-Textで学習できるモデルです。
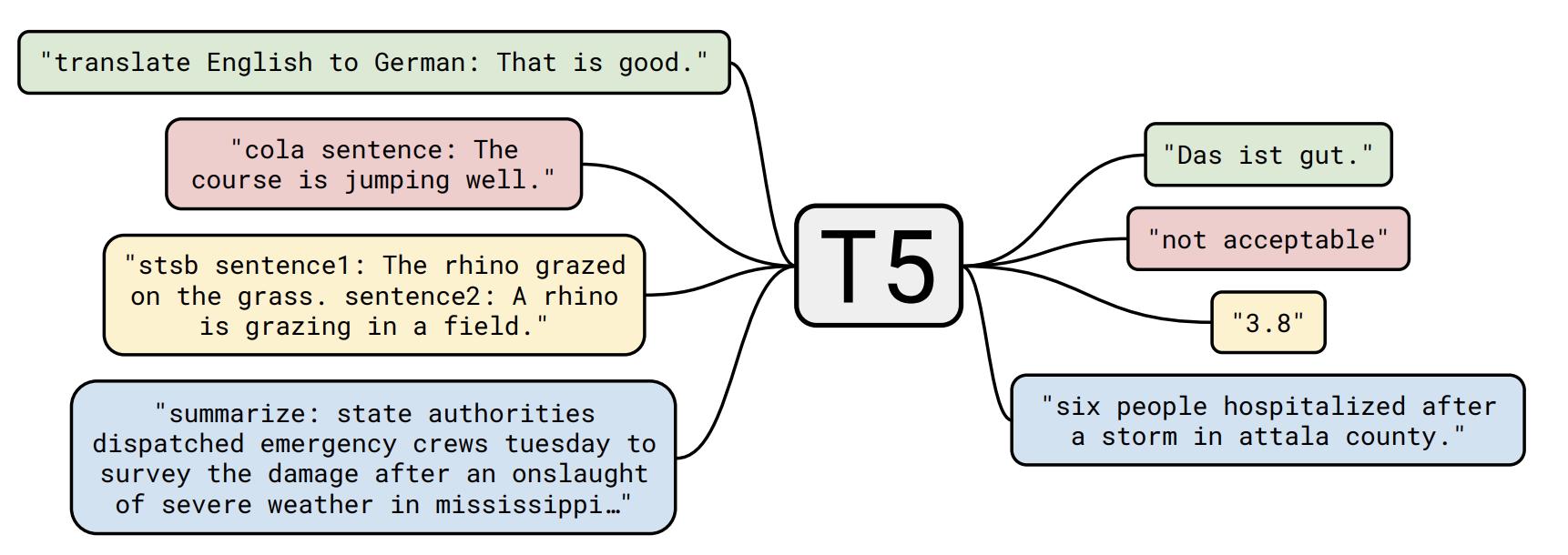
図の例では翻訳、分類、回帰、要約のタスクに一つのモデルで対応できていることがわかります。
T5にはColossal Clean Crawled Corpus(以下 C4)という大規模コーパスによる事前学習モデルが用意されています。
C4は英語のデータセットですが、日本語を含む101言語が含まれたmC4が公開されており、Multilingual T5(以下 mT5)はmC4で事前学習されています。
今回はこのmT5を利用して日本語の文章要約をやってみたいと思います。
wikiHow要約データ
文章要約のデータセットはwikihow_japaneseを利用させていただきます。
wikiHowのデータは構造化されており、見出し部分が要約文として抽出されています。
詳しくは以下の記事で解説されています。
wikiHowから日本語要約データを作成してみた
REDEMEの手順通りに記事をダウンロードした後、mT5でFine-Tuningする用に整形しておきます。
import pandas as pd
df = pd.read_json('data/output/test.jsonl', orient='records', lines=True)
df['inputs'] = df['src'].str.replace('\n', ' ').str.replace('\t', ' ')
df['targets'] = df['tgt'].str.replace('\n', ' ').str.replace('\t', ' ')
df[['inputs', 'targets']].to_csv('test.tsv', sep='\t', index=False)
元データはsrcに本文、tgtに要約文が入っているので、それぞれ改行とタブを削除してinputs, targetsというカラムでtsvに出力しています。改行とタブを削除したのは、Fine-Tuningのさいに学習がうまく進まなかったためです。
上記はtest用ですが、train用(train.tsv), validation用(dev.tsv)も同様に作成しています。
データの内容は以下のようになっています。

Fine-Tuning
データが用意できたので、mT5でFine-Tuningしていきます。
以下の2つの記事を参考にさせていただきました。
はじめての自然言語処理 第7回 T5 によるテキスト生成の検証
Multilingual T5をカスタマーサポートの対話でfine-tuning
実行環境はGoogle ColaboratoryのGPU環境を利用しています。
まず必要なライブラリをインストールします。
# T5ライブラリ
!pip install t5[gcp]==0.7.1
!pip install tensorflow-gpu
!git clone https://github.com/google-research/multilingual-t5.git
# 日本語を扱う上で必要なライブラリ
!apt-get install mecab mecab-ipadic-utf8
!pip install mecab-python3==0.996.5 sumeval
!apt-get install nkf
!pip install janome
さきほど作成したデータ(train.tsv, dev.tsv, test.tsv)をColabにアップロードしておきます。
次にFine-Tuningするためのモジュールを作成します。
%%bash
cat <<EOF > multilingual-t5/t5_wikihow.py
import t5.data
from t5.data import sentencepiece_vocabulary
from t5.evaluation import metrics
from t5.data import preprocessors
from t5.data import TaskRegistry
from t5.data import TextLineTask
import numpy as np
import functools
import tensorflow as tf
from sumeval.metrics.rouge import RougeCalculator
rouge_cal = RougeCalculator(stopwords=True, lang="ja")
DEFAULT_SPM_PATH = "gs://t5-data/vocabs/mc4.250000.100extra/sentencepiece.model"
DEFAULT_VOCAB = sentencepiece_vocabulary.SentencePieceVocabulary(
DEFAULT_SPM_PATH)
DEFAULT_OUTPUT_FEATURES = {
"inputs": t5.data.Feature(
vocabulary=DEFAULT_VOCAB, add_eos=True, required=False),
"targets": t5.data.Feature(
vocabulary=DEFAULT_VOCAB, add_eos=True)
}
# rouge-1, rouge-2, rouge-lを評価指標とします
def rouge(targets, predictions):
predictions = [tf.compat.as_text(x) for x in predictions]
if isinstance(targets[0], list):
targets = [[tf.compat.as_text(x) for x in target] for target in targets]
else:
targets = [tf.compat.as_text(x) for x in targets]
targets = [targets]
list_1, list_2, list_l = [], [], []
for i in range(len(predictions)):
list_1.append(rouge_cal.rouge_n(
summary=predictions[i],
references=targets[0][i],
n=1))
list_2.append(rouge_cal.rouge_n(
summary=predictions[i],
references=targets[0][i],
n=2))
list_l.append(rouge_cal.rouge_l(
summary=predictions[i],
references=targets[0][i]))
return {"rouge_1": np.array(list_1).mean(),
"rouge_2": np.array(list_2).mean(),
"rouge_l": np.array(list_l).mean()}
task_name = "t5_wikihow"
tsv_path = {
"train": "/content/train.tsv",
"validation": "/content/dev.tsv",
"test": "/content/test.tsv",
}
TaskRegistry.add(
task_name,
TextLineTask,
split_to_filepattern=tsv_path,
text_preprocessor=[
functools.partial(
preprocessors.parse_tsv,
field_names=["inputs", "targets"]),
],
output_features=DEFAULT_OUTPUT_FEATURES,
metric_fns=[rouge])
EOF
事前学習モデルをダウンロードします。
事前学習モデルはパラメータ数によって大小用意されているのですが、今回は色々試してColabのメモリサイズでぎりぎり動くlargeを選択しました。
!gsutil cp gs://t5-data/pretrained_models/mt5/large/checkpoint /content/large
!gsutil cp gs://t5-data/pretrained_models/mt5/large/model.ckpt-1000000* /content/large
!gsutil cp gs://t5-data/pretrained_models/mt5/large/operative_config.gin /content/large
作成したモジュールと事前学習モデルを使ってFine-Tuningを実行します。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \
\
PRE_TRAINED_MODEL_DIR='/content/large' && \
OPERATIVE_CONFIG=$PRE_TRAINED_MODEL_DIR'/operative_config.gin' && \
FINE_TUNED_MODEL_DIR='/content/large' && \
FINE_TUNING_BATCH_SIZE=1024 && \
PRE_TRAINGING_STEPS=1000000 && \
FINE_TUNING_STEPS=`expr $PRE_TRAINGING_STEPS + 1000` && \
INPUT_SEQ_LEN=512 &&\
TARGET_SEQ_LEN=64 &&\
\
echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\
echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\
echo "FINE_TUNING_BATCH_SIZE=$FINE_TUNING_BATCH_SIZE" &&\
echo "PRE_TRAINGING_STEPS=$PRE_TRAINGING_STEPS" &&\
echo "FINE_TUNING_STEPS=$FINE_TUNING_STEPS" && \
echo "INPUT_SEQ_LEN=$INPUT_SEQ_LEN" && \
echo "TARGET_SEQ_LEN=$TARGET_SEQ_LEN" && \
\
t5_mesh_transformer \
--model_dir="$FINE_TUNED_MODEL_DIR" \
--module_import="t5_wikihow" \
--gin_file="dataset.gin" \
--gin_file="$OPERATIVE_CONFIG" \
--gin_param="run.layout_rules=''" \
--gin_param="run.mesh_shape=''" \
--gin_param="utils.get_variable_dtype.activation_dtype='float32'" \
--gin_param="MIXTURE_NAME = 't5_wikihow'" \
--gin_file="learning_rate_schedules/constant_0_001.gin" \
--gin_param="run.train_steps=$FINE_TUNING_STEPS" \
--gin_param="run.sequence_length = {'inputs': $INPUT_SEQ_LEN, 'targets': $TARGET_SEQ_LEN}" \
--gin_param="run.save_checkpoints_steps=200" \
--gin_param="run.batch_size=('tokens_per_batch', $FINE_TUNING_BATCH_SIZE)"
入力のシーケンス長を512、出力を64とし、学習のステップ数は1,000に設定しています。
学習時間はColabで30分ほどで、GPUはTesla P100が割り当てられていました。
結果
wikiHow要約データをFine-Tuningしたモデルが出来上がったので、どんな文章が生成されるのかと、評価指標を見ていきます。
モデルから要約文を生成
モデルを使って要約文を生成します。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \
\
FINE_TUNED_MODEL_DIR='/content/large' && \
OPERATIVE_CONFIG=$FINE_TUNED_MODEL_DIR'/operative_config.gin' && \
\
echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\
echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\
\
t5_mesh_transformer \
--model_dir="$FINE_TUNED_MODEL_DIR" \
--module_import="t5_wikihow" \
--gin_file="$OPERATIVE_CONFIG" \
--gin_param="run.layout_rules=''" \
--gin_param="run.mesh_shape=''" \
--gin_file="infer.gin" \
--gin_file="beam_search.gin" \
--gin_param="utils.get_variable_dtype.slice_dtype='float32'" \
--gin_param="utils.get_variable_dtype.activation_dtype='float32'" \
--gin_param="MIXTURE_NAME='t5_wikihow'" \
--gin_param="run.batch_size=('tokens_per_batch', 512)" \
--gin_param="infer_checkpoint_step=1001000" \
--gin_param="input_filename='/content/inputs.txt'" \
--gin_param="output_filename='/content/outputs.txt'"
inputs.txtというファイルを用意して、test.tsvからinputsをいくつかピックアップして入力としています。
outputs.txtにモデルから生成された要約文が出力されますが、byte形式で出力されるため、以下のようにしてデコードします。
import pandas as pd
pd.read_csv('outputs.txt-1001000', header=None)[0].apply(lambda s: eval(s).decode("utf-8"))
いくつか生成された文章を見てみます。
例1
本文
正解の要約文
ガラガラヘビから離れましょう。医療処置を受けましょう。決して患部を心臓よりも高い位置に置いてはいけません。体を動かさずにじっとしましょう。
生成された要約文
噛みついた蛇に噛まれた場合は、すぐに病院へ直行しましょう。
短めでちょっと文がおかしいですが、要点を抑えた文章にはなっていそうです。
例2
本文
正解の要約文
NASAの様々な職業について学びましょう。自分が得意な学問が何かを定めましょう。興味を持って情熱を注げる分野は何かを考えてみましょう。大学や教育機関でどの学科を選択するべきか計画を立てましょう。一生懸命勉強しましょう。正しい学校を選びましょう。現在NASAに所属している人たちの経歴を調べてみましょう。先人と同じような道筋を辿れるのかどうか自問しましょう。幅広く学習しましょう。物事へのバランス感覚を養いましょう。
生成された要約文
自分の何が得意なのか掘り下げましょう。自分の何が得意なのか掘り下げましょう。
要約しすぎている感じですかね。なぜか同じ文を繰り返してしまいました。
例3
本文
正解の要約文
タラの切り身の下ごしらえ。バターとレモン果汁を混ぜます。小麦粉、塩、白胡椒を別のボウルで混ぜます。タラの切り身をバター液に付けた後、配合した粉類をまぶします。残っているバター液を魚の上からかけます。盛りつけをします。
生成された要約文
魚を洗う。バターとレモン果汁を混ぜる。バターとレモン果汁を混ぜる。バターとレモン果汁を混ぜる。
本文のはじめの方には「魚」という言葉は出てきていないのに、魚を洗っていると分かっているのはすごいと思いました。
ただ後半はまた繰り返しになってしまっています。
他にもいくつか見てみましたが、同じ文を繰り返してしまう現象が多く見られました。
入出力のシーケンス長を変えたり、学習のステップ数を増やしたりしてみましたが、改善はされなかったです。
評価指標の比較
生成された文はいまいちでしたが、一応評価指標も確認してみます。
要約の評価指標であるROUGE-1, 2, Lを用いました。ROUGEは正解の要約文と生成した要約文がどれだけ一致しているかという指標で、1に近いほどよいです。
以下で詳しく解説させています。
ROUGEを訪ねて三千里:より良い要約の評価を求めて
testデータの評価値を計算します。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \
\
FINE_TUNED_MODEL_DIR='/content/large' && \
OPERATIVE_CONFIG=$FINE_TUNED_MODEL_DIR'/operative_config.gin' && \
\
echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\
echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\
\
t5_mesh_transformer \
--model_dir="$FINE_TUNED_MODEL_DIR" \
--module_import="t5_wikihow" \
--gin_file="$OPERATIVE_CONFIG" \
--gin_param="run.layout_rules=''" \
--gin_param="run.mesh_shape=''" \
--gin_file="eval.gin" \
--gin_file="beam_search.gin" \
--gin_param="utils.get_variable_dtype.slice_dtype='float32'" \
--gin_param="utils.get_variable_dtype.activation_dtype='float32'" \
--gin_param="MIXTURE_NAME = 't5_wikihow'" \
--gin_param="run.dataset_split='test'" \
--gin_param="run.batch_size=('tokens_per_batch', 512)" \
--gin_param="eval_checkpoint_step = 1001000" 2>&1 | tee test.log
比較対象として、本文の始めの3文を要約とみなしたもの(Lead-3)を用いました。
| 手法 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Lead-3 | 0.300 | 0.084 | 0.212 |
| mT5 | 0.255 | 0.081 | 0.234 |
ROUGE-Lでは勝っているものの、良い精度とは言い難い結果になりました。
生成された文が短かったり、同じ文が続けて生成されてしまう問題が原因かと考えています。
まとめ
Multilingual T5でwikiHowの日本語要約データを用いて要約文の生成をやってみました。
うまく文が生成されず、悔しい結果となりましたが、要点をとらえた文章が生成されるのはすごいなと感じました。
引き続き原因を調べつつ、ちゃんとインスタンスを立ててより大きな事前学習モデルも試してみたいなと思います。
さいごに
Ateam Group Manager & Specialist Advent Calendar 2020の6日目は @NMura3 がお送りします。お楽しみに!