2021/2/19(土)の夜間、9/2(木)の午前にAWSで障害が発生しました
ここのところ一年に1,2度のペースで障害が発生しているので
自分なりに考察していきます
2021/9/2(木)のAWS障害
-
障害時間 2021/9/2(木) 07:30~13:42
-
ダウンタイム 6時間30分
-
障害が発生したリージョン/AZ
- 東京リージョン
- ap-northeast-1
-
影響を受けたサービス
- Direct Connectを使用して通信するサービス全て
-
原因
- Direct Connectで障害が発生しデータセンターネットワークへのネットワークパスに沿ったネットワークレイヤーの 1 つでネットワークデバイスの一部に障害が発生
2021/2/19のAWS障害の詳細
-
障害時間 2021/2/19(土) 23:50~20(日) AM5:30
-
ダウンタイム 4時間40分
-
AWSの障害レポートは見つけられず
-
障害が発生したリージョン/AZ
- 東京リージョン
- ap-northeast-1(apne1-az1)
-
影響を受けたサービス
- EC2
- EBS
-
原因
- 冷却ユニットの温度上昇の影響により、冷却ユニットの電源がダウンする
過去に発生した大きな障害(東京リージョン)
-
2019/8/23 EC2、EBS、RDS、Redshift、ElastiCache 、Workspacesで障害
- ダウンタイム 約4時間
- AWSの障害レポート
-
2020/4/20 SQS、Lambda、CloudWatch、CloudFormationで障害
- ダウンタイム 約4時間
※レポート見つからず
- ダウンタイム 約4時間
-
ちなみに2013年~2019年まで東京リージョンで大きな障害は無かったのである意味凄いなという感じです
反対にユーザは「東京リージョンは落ちない」という錯覚をしていた人がほとんどだと思います(海外リージョンはそれなりに障害が起きています)
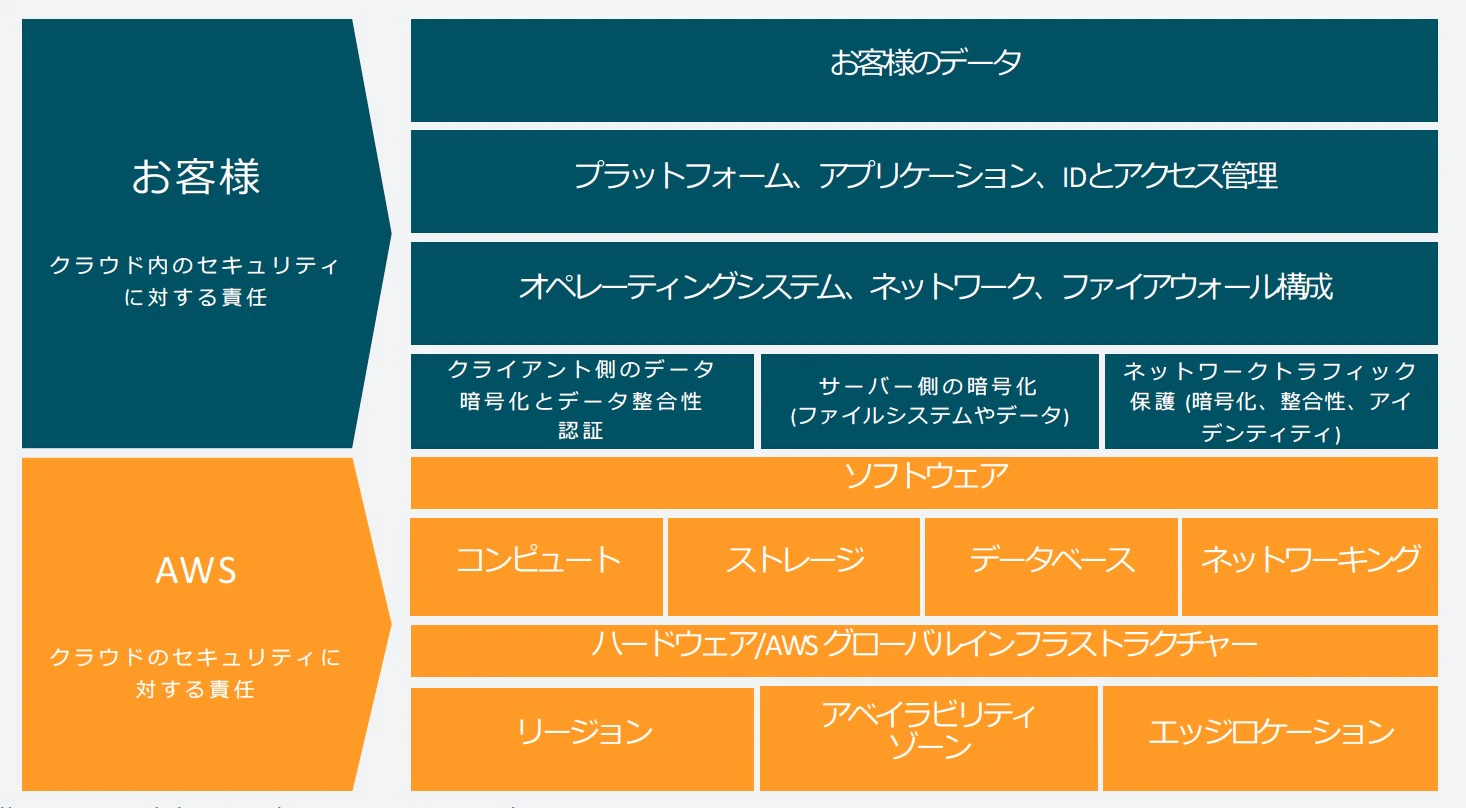
責任共有モデル
AWSには責任共有モデルがあり、AWSの責任とユーザの責任の境界線を明示的にしています
例えば、データの保護やバックアップは「ユーザ側でやってくださいね、AWSは責任を取りませんよ」というものです
Design for Failure(障害設計)
AWSは障害を見据えて設計してくださいと提唱しています
従いユーザは障害が発生することを考えての設計指針が必要です
SLAの条件
-
EC2、EBSのSLA 99.99% (月間ダウンタイム 4.32 分)
-
SLA適用条件(EC2、EBS)

- 要約すると東京リージョンの場合は2つのAZで接続不可にならないと適用されない
-
私の記憶ではAZが2つ同時に接続不可になったことは無いです
すべての障害対策は不可能
すべての障害対策をすることは不可能です
障害とは予測できない事が多いし、予期できないことが起こるから世の中でシステム障害が起きています
予測できない障害に対してユーザ側は適材適所柔軟に対応するしか無いと考えます
ただし、予測の範囲内で障害設計することが大事です
万全な準備しておけば、障害への対応時間を短くできます
完全な障害設計は不可能
完全な障害設計は不可能です
そもそも、AWSはサービスのアーキテクチャを開示していません
これが何を意味するかと言うと、アーキテクチャが分からないユーザは
分からない部分の対処をできるはずがないです(障害設計できない)
例えばですが、AというAWSのサービスがあったとします
このAサービスがEC2のアプライアンス上で動いているとしたら
Aサービスの障害設計をしたとしても、EC2がダウン→Aサービスもダウンします
故に完全な障害設計は不可能だと考えています
ユーザはできるだけの障害設計をする、障害に備えることしかできません
実際の障害対応は想像より複雑
障害テストは割と0と1で考えている事が多いです
例えば「EC2がダウン→切替える」とかです
こういう障害が起こってくれれば対応する側も助かるのですが
実際の障害は部分部分でゆっくり少しづつ死んでいくという事があります
EC2のCPUの負荷が少しづつ高くなる、EBSのパフォーマンスが低下していくなどで
結果的にサービスが不安定になるという、対応する側にとっては判断も難しく
複雑で嫌なパターンになります
AWSの障害復旧は早い
毎回数時間で障害復旧します
ダウンしたのは事実ですが、それを数時間で復旧までもっていくAWSは凄いなと思います
実際データセンタで障害が起きたら、このスピード感で対応ができるかと言うと、、、
正直難しいかなと思います
実態を歪めない
バイアスやハロー効果で実態を歪めないでください
メガクラウドで障害起きると大きなニュースになります
どうしても印象が悪くなったり、クラウドはダメだってなりがちです
例えば交通事故で言うと、飛行機の事故と、個人車の事故を比べるようなものです
実態としては、飛行機事故より個人車の事故のほうが圧倒的に多いです
さいごに障害に対する考え
2020年に東証一部のシステムでも障害はありましたが、障害を防ぐことは不可能です
人間に体調を崩すなと言っているのと一緒です
システムはダウンする事が前提です
ただ、障害に備えることは可能なので、RTO/RPOを考慮して障害設計をする、障害時のオペレーションを確立しておく事が重要です
前述に書いた「Well-Arc」を参考にするのも一つの手段です
AWSの10年以上の設計指針が積み上げられています
Well-Arcをすべて実行するのは不可能かもしれませんが参考にはなります
・ Well-Arcはこちら