最近この2つについて学んだのでそのメモ書きです。もっと効率的なプログラムの書き方があったら教えてもらいたいです。。。
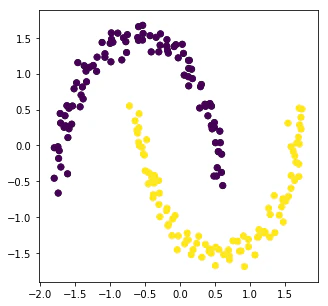
お馴染みのこちらのデータセットですが、これをk-NNなどで分類しようとするとどうしても原点付近のデータがうまいこと分離されません。そこで利用できるのが Ratio CutやNormalized Cutといった点の間のつながりに重みを持たせることでその重みからクラスタに分類しようといった考え方です。
点同士に重みを持たせる方法としては次の3つのようなものがあります。
- $\varepsilon$-neighborhood graph
- k-nearest neighbor graph
- Fully connected graph
1つ目は、ある1点からある距離$\varepsilon$内にある点の間全てに重みを持たせるものです。
2つ目は、ある1点から最も近いk点との間に重みを持たせるものです。この方法はそのままだと$v_i$からみて$v_j$には重みがあるけど、その逆は重みがないといったことがおきる場合があります。そのため、片方から見て重みがあるのならその逆にも重みを持たせることにより無向グラフを作成することができます。
3つ目は、全ての点の間に重みをもたせるものです。点同士の距離が遠くなるにつれ重みを小さくするためにガウス分布が使われることが多いです。
$$W_{ij}=\rm{exp}\left(-\frac{||v_i-v_j||^2}{2\sigma^2}\right)$$
1つ目と2つ目を実装すると次のようになります。
class Similarity_Graph:
def __init__(self,N):
self.W=np.zeros((N,N))
def epsilon_nearest(self,data,r):
W=self.W
for i in range(N):
distance2=np.sum((data-data[i])**2,axis=1)
for j in range(N):
if distance2[j]==0:
W[i][j]=0
elif distance2[j]<r:
W[i][j]=0
else:
W[i][j]=1
return W
def k_nearest(self,data,k):
W=self.W
for i in range(N):
distance2=np.sum((data-data[i])**2,axis=1)
nbrs=np.argsort(distance2)[1:k+1]
W[i,nbrs]=1
W[nbrs,i]=1
return W
Ratio Cut
Ratio Cutで最小化したい目的関数は次の式です。
$$RatioCut(A_1,A_2)=\frac{1}{2}\sum_i \frac{W\left(A_i,\bar{A_i}\right)}{|A_i|}$$
ここでLをGraph Laplacianとし、$f$を次のように定めます。
$$f=
\sqrt{\frac{|\bar{A}|}{|A|}} (v_i \in A),\
\sqrt{\frac{|A|}{|\bar{A}|}} (v_i \in \bar{A})\
$$
このように定めた上で$f^TLf$を計算すると次のようになります。
$$f^TLf=|V|RatioCut(A,\bar{A})$$
すなわち、$RatioCut(A,\bar{A})$を最小化することは$f^TLf$を最小化することに等しくなります。
結果として求めたい最小化問題は次のようになります。
$$\rm{min}_{A \subset V}\ f^TLf \ \ \ \rm{subject\ \ to}\ \ \ \ f\perp 1,||f||=\sqrt{n}$$
Rayleigh-Ritz theoremからGraph Laplacian Lの2番目に小さい固有値への固有ベクトル$f$が解を与えることになります。実際の実装では$f$の値の符号によって領域を分割します。実装は後のNormalized Cutと合わせて行います。
Normalized Cut
Normalized Cutで最小化したい目的関数は次の式です。
$$NCut(A_1,A_2)=\frac{1}{2}\sum_i \frac{W(A_i,\bar{A_i})}{vol(A_i)}$$
$vol(A_i)$は次のように定義されます。
$$vol(A_i)=\sum_{i \in A_i,j\in V} W_{ij}$$
こちらでは求めたい最小化問題は次のようなものです。
$$\rm{min}_{f \in R^n}\ f^TLf \ \ \ \rm{subject\ \ to}\ \ \ \ Df\perp 1,\ f^TDf=vol(V)$$
ここで$g=D^{1/2}f$を代入すると次のようになります。
$$\rm{min}_{g \in R^n}\ g^TD^{-1/2}LD^{-1/2}g \ \ \ \rm{subject\ \ to}\ \ \ \ g\perp D^{1/2}1,\ ||g||^2=vol(V)$$
これより$\rm{Lsym}=D^{-1/2}LD^{-1/2}$とおくとこれは$\rm{Lsym}$の2番目の固有値に対する固有ベクトルが解を与えることになります。$\rm{Lsym}$はNormalized Graph Laplacianと呼ばれるものです。
以上の2つをk-nearest neighbor graphで実装すると次のようになります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import scipy.linalg
X,z=datasets.make_moons(n_samples=200,noise=0.05,random_state=0)
X_norm=(X-np.mean(X,axis=0))/np.std(X,axis=0)
x=X_norm[:,0]
y=X_norm[:,1]
figure=plt.figure(figsize=(5,5))
plt.scatter(x,y,c=z)
N=len(X_norm)
Similarity=Similarity_Graph(N)
W=Similarity.k_nearest(data=X_norm,k=10)
D=np.zeros((N,N))
for i in range(N):
D[i][i]=np.sum(W,axis=1)[i]
L=D-W
Dsqrt=scipy.linalg.sqrtm(D)
Dsqrt_inv=np.linalg.inv(Dsqrt)
Lsym=np.dot(Dsqrt_inv,L,Dsqrt)
U,sig,VT=np.linalg.svd(Lsym) #NormalizedCut#
# U,sig,VT=np.linalg.svd(L) #RatioCut
Y=VT[N-2,:].T
for i in range(N):
if Y[i]>0:
Y[i]=1
else:
Y[i]=0
plt.scatter(x,y,c=Y)
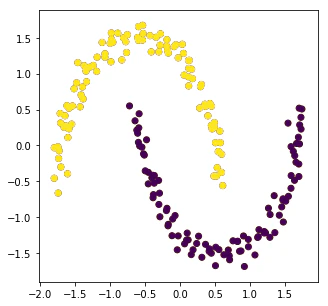
結果はどちらを用いても今回はきれいに2つに分かれました。しかし、それぞれの領域の点数が大きく異なっている場合、Ratio Cutは点数がほぼ同じになるように調整するのでうまくいきません。なのでNormalized Cutを用いるほうが良いと考えています。
参考
[1]機械学習とかコンピュータビジョンとか