はじめに
ここでは、機械学習用ライブラリscikit-learnの基本的な使い方について解説します。
機械学習アルゴリズムについては、別の記事で取り上げる予定です。
Python3系の使用を想定しています。
ライブラリの読み込み
他のライブラリと同様に、importで読み込めますが、下にも書いている通り実際に使う時はimportとfromで読み込むことが多くなります。
scikit-learn_1.py
import sklearn
データセット
scikit-learnには、機械学習に使えるデータセットが色々用意されています。
どんなデータセットがあるかは以下のコードを実行すれば分かります。
scikit-learn_2.py
import sklearn.datasets
[s for s in dir(sklearn.datasets) if s.startswith('load_')]
データセットの準備
ここでは、上記のデータセットの中でiris(アヤメ)のデータセットを使うこととします。
ガクの長さからガクの幅を線形回帰を使って予測することを考えます。
まずはデータの下準備です。
scikit-learn_3.py
from sklearn.datasets import load_iris
import pandas as pd
data_iris = load_iris()
X = pd.DataFrame(data_iris.data, columns=data_iris.feature_names)
x = X.iloc[:, 0] # アヤメのガクの長さ
y = X.iloc[:, 1] # アヤメのガクの幅
機械学習(ここでは線形回帰)
データの準備が終わったら、線形回帰を実行します。
scikit-learn_4.py
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
%matplotlib inline
X_train = [[5.1], [4.9], [4.7], [4.6], [5.0], [5.4], [4.6], [5.0], [4.4], [4.9]]
y_train = [3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1]
model = LinearRegression()
model.fit(X_train, y_train) # 線形回帰モデルを作成
print(model.coef_) # 傾き
print(model.intercept_) # 切片
X_test = [[5.4], [4.8], [4.8], [4.3], [5.8]]
y_test = [3.7, 3.4, 3.0, 3.0, 4.0]
y_pred = model.predict(X_test) # 予測
print(y_pred)
fig, ax = plt.subplots()
ax.scatter(X_test, y_test, label='Test set') # 実測値の散布図
ax.plot(X_test, y_pred, label = 'Regression curve') # 回帰直線
ax.legend()
plt.show() # 予測に使ったデータを図示
plt.savefig('scikit-learn_4.png')
print(r2_score(y_test, y_pred)) # R^2値
テスト用のデータと回帰直線を図示すると以下のようになります。
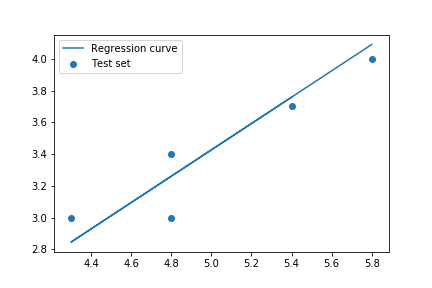
最後のR^2値は、モデルのあてはまり具合を示すものですが、回帰なのか分類なのか、その他目的によって見るパラメータは変わってきます。
まとめ
ここでは、scikit-learnの基本的な部分について解説してきました。
データセットの準備、データの前処理、予測モデルの作成、モデルの検証という流れをざっくりとでも押さえておくと良いでしょう。