こんにちは。僕です。
ここしばらくは、相変わらずインテル®PACカードとインテル® アクセラレーション・スタック(以下IAS)を触っています。どうしてどのお客様も、自分たちのFPGAカードでもIASを使わせろと言ってこないんだろうと憤る日々です。使い勝手良いのに。
ちなみに、既に次のバージョンであるインテル® オープン FPGA スタック(以下OFS)もリリースされています。IASと似たような感じで使えます。
Streaming DMA AFUとは
さて、PACカードを使ってFPGA開発をすすめる際は、色々あるデザインサンプルのうち一番近そうなもの・使えそうなものをベースにすることが多いです。その中でも特に使われることが多いものの一つが、下のStreaming DMA AFU(Accelerator Functional Unit)と呼ばれるサンプルです。
なぜ良く使われるかというと、文字通りStreaming的にデータを流して処理できるので、レイテンシー的に有利な結果が出ることが多いためです。詳細は上のドキュメントを読んで頂くと良いのですが、構造としては以下の図のようになっています(上記のドキュメントからの抜粋です)。
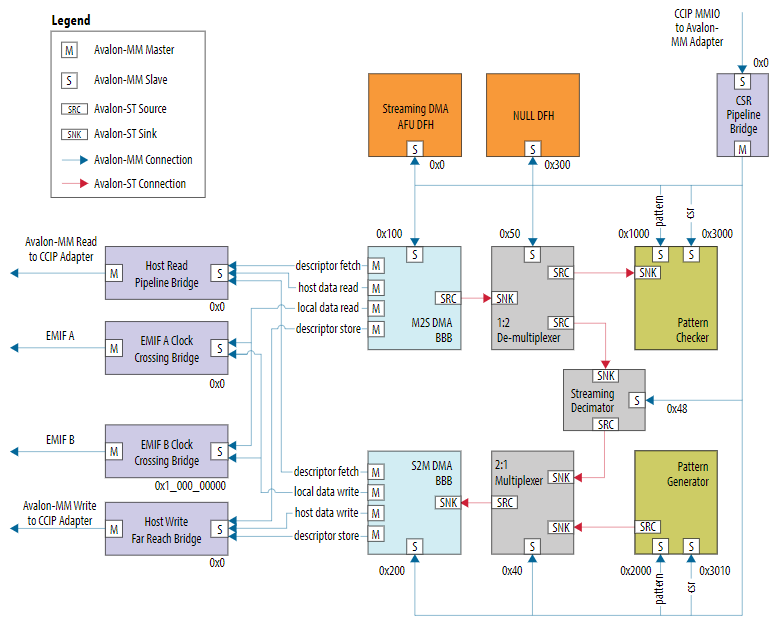
見ていただくと分かる通り、主要なモジュールは水色のハコで書いてある2つのDMAコントローラーです。
M2S DMA BBBとあるのが、Avalon® Memory Mapped Interface(以下AVMM)
でデータを読み込んで、Avalon® Streaming Interface(以下AVST)で読み込んだデータを出力するBBB(Basic Building Block。まあIPだと思っていただければ)です。
S2M DMA BBBとあるのが、逆にAVST I/FからデータをStreamingで読み込んでAVMM I/Fから出力する、というものになります。
ですので、M2S DMA BBBとS2M DMA BBBの間にAVST I/Fの入出力を持ったアクセラレータを挟めば、一旦FPGAボード上のDDRメモリにデータをコピーして云々等やる必要なく、直接ホスト側から流れてきたデータを処理できて、レイテンシー的に嬉しいということになります。
ちなみに、AVMMとAVSTのスペックは以下です。
本サンプルはもう少し工夫がしてあって、処理データの入出力はホストI/FだけでなくFPGAボード上のメモリーも選択可能になっていますし(EMIF A/B)、M2S DMA BBBで読み込んだデータをループバック的にS2M側に戻すだけでなくPattern Checkerで期待値比較を出来るようになっていたり、Streaming Decimatorというモジュールでデータの量を減らして(アクセラレーター実装を模擬するイメージ)、S2M側に返すことも出来るようになっています。
また、図上でDFHというオレンジ色のモジュールが2つありますが、これはIAS対応のAccelerator Functional Unit(以下AFU)を開発する際に実装が必須になるものです。詳しくは以下を参照ください。
今回の目的
FPGAといえば低レイテンシー処理向けと言われることが多いですが、最近筆者はとある案件で、NICカードではなくFPGAカードを介してUDP通信したときのレイテンシーを知りたいということになりました。
そこで、ちょうど私が作ったUDP Offload Engineがあったこともあり、Streaming DMA AFUサンプルを使って測定しようと思います。
使うFPGAボードは、手軽に使えるところでArria10を搭載したPACカードにしました。
修正したところ
既存の機能はデバッグ用にそのまま残したかったので、今回は1:2 De-multiplexerと2:1 Muiltiplexerをそれぞれ1:3、3:1版に修正し、増やしたポートにネットワーク系を接続することにしました。
申し訳ありません…
ソースコード掲載の許可取りが間に合わず、とりあえず今の時点では載せられるものだけ載せます。
実コードがほしい、という方はインテルの担当者にお問い合わせください。
図としてはこんな感じです。
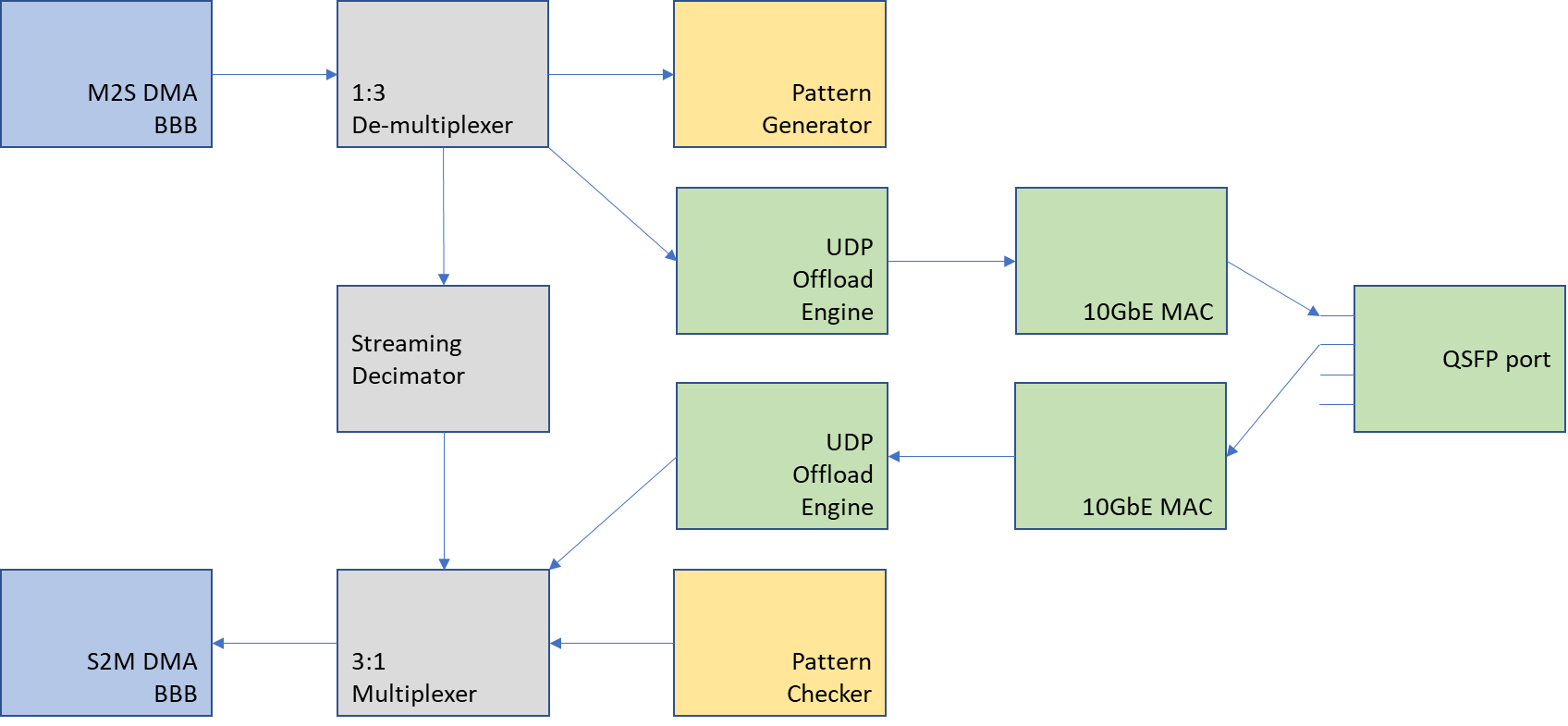
今回使うPACカードは、10GbE x4として使えるQSFPポートが1つついています。ここに、以下のようなブレークアウトケーブル(今回はこれを使いましたが、特にこれを推奨しているわけではありません)を接続して10GbEを4系統とし、4つのうち今回使う2つに関して10GbE対応のスイッチに接続しました。
修正するファイルは以下になります。
two_to_one_streaming_mux.v
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu/hw/rtl/QSYS_IPs/two_to_one_streaming_multiplexer/two_to_one_streaming_mux.v
大した変更ではないですが、一応変更点を載せておきます。
module one_to_two_streaming_demux (
//snip
src_C_data,
src_C_sop,
src_C_eop,
src_C_empty,
src_C_valid,
src_C_ready
);
//snip
reg [1:0] select; // when 0 source A is selected, and when 1 source B is selected
always @ (posedge clk)
begin
if (reset)
begin
select <= 2'b00; // coming out of reset sink A will be selected
end
else if ((csr_write == 1'b1) & (csr_byteenable[0] == 1'b1)) // lowest byte lane being written
begin
select <= csr_writedata[1:0];
end
end
//snip
assign csr_readdata = {62'h00000000, select};
assign src_C_data = snk_data;
assign src_C_sop = snk_sop;
assign src_C_eop = snk_eop;
assign src_C_empty = snk_empty;
assign src_C_valid = (select == 2'd2) & snk_valid; // if source B is selected then forward the sink valid to source B's valid
// src A & B to sink wiring
assign snk_ready = (select == 2'd0) ? src_A_ready:
(select == 2'd1) ? src_B_ready:
src_C_ready;
// snip
one_to_two_streaming_demux.v
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu/hw/rtl/QSYS_IPs/one_to_two_streaming_demultiplexer/one_to_two_streaming_demux.v
上とほぼ似たような修正です。
ccip_std_afu.sv
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu_udp/hw/rtl/ccip_std_afu.sv
HSSIのI/Fを追加する必要があります。
//snip
`include "platform_if.vh"
`include "pr_hssi_if.vh" // added
module ccip_std_afu
#(
parameter DDR_ADDR_WIDTH = 26
)
(
// CCI-P Clocks and Resets
pClk, // 400MHz - CCI-P clock domain. Primary interface clock
pClkDiv2, // 200MHz - CCI-P clock domain.
pClkDiv4, // 100MHz - CCI-P clock domain.
uClk_usr, // User clock domain. Refer to clock programming guide ** Currently provides fixed 300MHz clock **
uClk_usrDiv2, // User clock domain. Half the programmed frequency ** Currently provides fixed 150MHz clock **
pck_cp2af_softReset, // CCI-P ACTIVE HIGH Soft Reset
pck_cp2af_pwrState, // CCI-P AFU Power State
pck_cp2af_error, // CCI-P Protocol Error Detected
hssi, // added
//snip
);
//snip
pr_hssi_if.to_fiu hssi;
//snip
afu afu_inst(
.afu_clk(afu_clk),
//snip
.hssi(hssi),
.cp2af_sRxPort ( mpf2af_sRxPort ) ,
.cp2af_mmio_c0rx ( pck_cp2af_mmio_sRx.c0 ) ,
.af2cp_sTxPort ( af2mpf_sTxPort )
);
endmodule
~
afu.sv
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu_udp/hw/rtl/afu.sv
筆者はこのモジュールにMAC IPやUDP Offload Engine IPを追加しました。
streaming_dma_afu.json
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu_udp/hw/rtl/streaming_dma_afu.json
hssiのところを追加します。
{
"version": 1,
"afu-image": {
"power": 0,
"afu-top-interface":
{
"class": "ccip_std_afu_avalon_mm_legacy_wires",
"module-ports" :
[
{
"class": "cci-p",
"params":
{
"clock": "hssi.f2a_prmgmt_ctrl_clk"
}
},
{
"class": "hssi",
"interface": "raw_pr"
}
]
},
"accelerator-clusters":
[
{
"name": "streaming_dma_test_afu",
"total-contexts": 1,
"accelerator-type-uuid": "eb59bf9d-b211-4a4e-b3e3-753ce68634ba"
}
]
}
}
s
fileslist.txt
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu_udp/hw/rtl/filelist.txt
追加したファイルはここに登録します。
MAC IP類
10Gbps Ethernet Accelerator Functional Unit (AFU) design exampleというのが用意されていますので、ここからMAC関係ファイルをコピーして持ってくるのが良いと思います。
a10_gx_pac_ias_1_2_1_pv/hw/samples/eth_e2e_e10/hw/rtl/e10/A10/altera_eth_10g_mac_base_r.v
a10_gx_pac_ias_1_2_1_pv/hw/samples/eth_e2e_e10/hw/rtl/e10/A10/mac
a10_gx_pac_ias_1_2_1_pv/hw/samples/eth_e2e_e10/hw/rtl/e10/A10/pll_mpll
a10_gx_pac_ias_1_2_1_pv/hw/samples/eth_e2e_e10/hw/rtl/e10/A10/xcvr_reset_controller
UDP Offload Engine IP
これに関しても、追ってgithub.com上で公開したいと思っています。
お急ぎの方はインテルの担当者まで…
fpga_dma_st_test.cpp
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu_udp/sw/fpga_dma_st_test.cpp
case 'l': /* loopback mode */
if (NULL == tmp_optarg)
break;
if (!STR_CONST_CMP(tmp_optarg, "on")) {
config->loopback = STDMA_LOOPBACK_ON;
debug_print("loopback = on\n");
}
else if (!STR_CONST_CMP(tmp_optarg, "off")) {
config->loopback = STDMA_LOOPBACK_OFF;
debug_print("loopback = off\n");
}
else if (!STR_CONST_CMP(tmp_optarg, "eth")) { // added
config->loopback = STDMA_LOOPBACK_ON_ETH;
debug_print("loopback = eth\n");
}
else {
config->loopback = STDMA_INVAL_LOOPBACK;
fprintf(stderr, "Invalid loopback mode\n");
printUsage();
}
break;
fpga_dma_st_test_utils.cpp
a10_gx_pac_ias_1_2_1_pv/hw/samples/streaming_dma_afu_udp/sw/fpga_dma_st_testutils.cpp
//snip
static fpga_result loopback_test(fpga_handle afc_h, fpga_dma_handle_t tx_dma_h, fpga_dma_handle_t rx_dma_h, s
truct config *config) {
fpga_result res = FPGA_OK;
// configure loopback on
uint64_t loopback_en;
if (config->loopback == STDMA_LOOPBACK_ON)
loopback_en = (uint64_t)0x1;
else
loopback_en = (uint64_t)0x2; // loopback via Ethernet
コンパイル&事前準備
今回のテーマとは直接関係ないですが、コンパイルの仕方等も紹介しておきます。ちょっと強調しておきたいことがあるからです。
AFUのコンパイル
このあたりはいつもと同じです。
$ afu_synth_setup -s hw/rtl/filelist.txt build_synth
$ cd build_synth
$ run.sh
PACSignによるサイン追加
IAS1.2.1またはIAS2.0.1から、run.shで出来上がったGreen bit streamファイル(gbsファイル)に対してPACSignというツールをかけて、セキュリティのためのサインをしなければいけないことになっています。以下は、とりあえず空のサインを入れるためのフローです。
$ PACSign PR -t UPDATE -H openssl_manager -i streaming_dma_afu.gbs -o streaming_dma_afu_unsigned.gbs
Output file streaming_dma_afu_unsigned.gbs exists. Overwrite? Y = yes, N = no: y
No root key specified. Generate unsigned bitstream? Y = yes, N = no: y
No CSK specified. Generate unsigned bitstream? Y = yes, N = no: y
ネットワーク設定
私が強調したいのはここです。
もう長いことPACカードでネットワークをいじったりしていますが、ちょっと間があくとすぐここを忘れて、なぜ動かないんだ…と悩むんですよね。ここが抜けてるとネットワーク周りが動きませんのでご注意を!
ちなみに、環境によってパス名がちょっと変わる可能性はあります。
$ sudo sh -c "echo 10 > /sys/class/fpga/intel-fpga-dev.0/intel-fpga-fme.0/intel-pac-hssi.0.auto/hssi_mgmt/config"
$ sudo sh -c "echo 1 > /sys/class/fpga/intel-fpga-dev.0/intel-fpga-fme.0/intel-pac-hssi.0.auto/hssi_mgmt/dfe_kickstart"
設定が2つありますが、最初のものが10GbEの設定(40GbEも対応出来るため)、2番目がDecision feedback equalizerの起動です。
結果
とりあえず8MBのデータで試してみました。最初に通常のループバック、2度めにネットワーク経由のループバックを。今回は諸事情で512byte単位にパケットで区切って送信させています。
$ fpgaconf ../build_synth/streaming_dma_afu_unsigned.gbs
$ cd ../sw
$ ./fpga_dma_st_test -l on -s 8388608 -p 8388608 -t fixed -f 0
Memory to Stream BW = 5401 MBps, Stream to Memory BW = 4044 MBps
Time: 0.001545
$ ./fpga_dma_st_test -l eth -s 8388608 -p 8388608 -t fixed -f 0
Memory to Stream BW = 1078 MBps, Stream to Memory BW = 1010 MBps
Time: 0.007815
通常ループバックが往復約1.5ms、ネットワーク経由で約7.8msという結果になりました。まあそんなに悪くない結果でしょうか。
ちなみに、Ethernetパケット送り側の波形(Low Latency Ethernet 10G MAC Intel® FPGA IP入出力)を見てみると、こんな感じです。
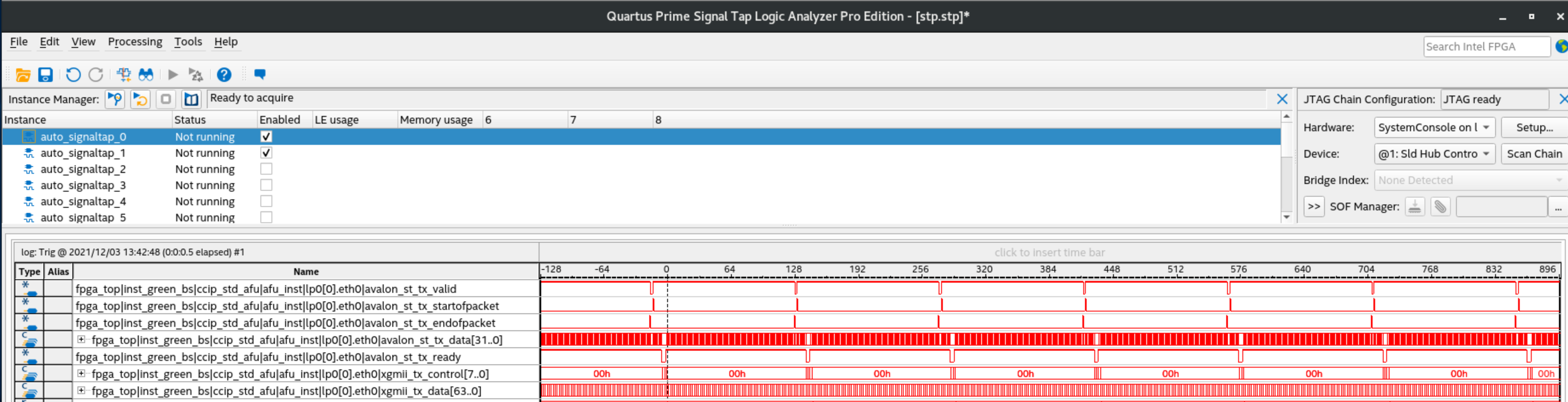
無駄なくパケットを送れていそうです。
今後、諸々最適化を進めて、どこまで高速化出来るか見ていきたいと思ってます。
Notices & Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.