!!!この記事はもう古いので現代ではもう通用しません!新しいやり方を載せている人がいるので、そちらを参考にしてください!!!
Wikipedia のデータをお手軽に Elasticsearch に流し込む手順です。
Wikipedia 記事データのダウンロード
http://dumps.wikimedia.org/backup-index.html からリンクをたどると pages-articles.xml.bz2 というファイルをダウンロードできる。
日本語版だったら jawiki.
ここでは jawiki の 20150602 のデータを使う。
$ wget http://dumps.wikimedia.org/jawiki/20150602/jawiki-20150602-pages-articles.xml.bz2
ダウンロード完了まで時間かかるからその間に並行して elasticsearch のインストールとかするとよさそう。
elasticsearch 関係のインストール
本体
$ brew install elasticsearch
ここでは Mac 環境なので Homebrew でいれてます。
elasticsearch-head
http://mobz.github.io/elasticsearch-head/
elasticsearch の Web フロントエンド。入れると http://localhost:9200/_plugin/head/ でブラウザからいろいろできる。
$ /usr/local/Cellar/elasticsearch/*/libexec/bin/plugin install mobz/elasticsearch-head
stream2es
https://github.com/elastic/stream2es
ストリームで elasticsearch にデータを流し込むのが簡単になるもの。
$ curl -O download.elasticsearch.org/stream2es/stream2es
$ chmod +x stream2es
$ mv stream2es /usr/local/bin/
インデックスをつくる
n-gram で検索したいので analyzer と mapping をここで定義。
ここでは 1-3 gram にしてる。
curl -XPUT 'localhost:9200/wiki' -d '{
"settings": {
"analysis": {
"analyzer": {
"ngram": {
"filter": [
"cjk_width",
"lowercase"
],
"char_filter": [
"html_strip"
],
"type": "custom",
"tokenizer": "ngram"
}
},
"tokenizer": {
"ngram": {
"token_chars": [
"letter",
"digit"
],
"min_gram": "1",
"type": "nGram",
"max_gram": "3"
}
}
}
},
"mappings": {
"page": {
"properties": {
"redirect": {
"type": "boolean"
},
"special": {
"type": "boolean"
},
"disambiguation": {
"type": "boolean"
},
"link": {
"type": "string"
},
"stub": {
"type": "boolean"
},
"text": {
"analyzer": "ngram",
"type": "string"
},
"category": {
"type": "string"
},
"title": {
"analyzer": "ngram",
"type": "string"
}
}
}
}
}'
データを流しこんでみる
ためしに5件。
$ stream2es wiki --max-docs 5 --source jawiki-20150602-pages-articles.xml.bz2
ブラウザで http://localhost:9200/_plugin/head/ を開いて以下のようにでればOK
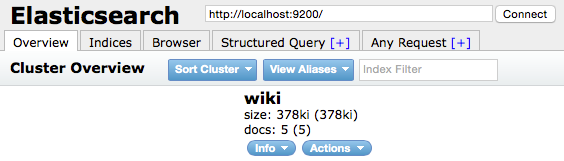
もし、Unassigned ってでたら
$ curl -XPUT localhost:9200/_settings -d'{"number_of_replicas":0}'
してからやり直し。
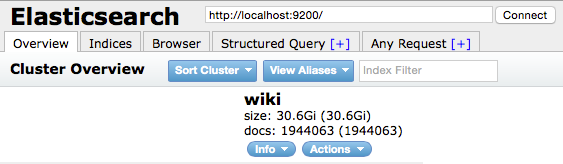
全部入れるとこのくらいになる。