Redisでよく使うコマンドにKEYSがあると思う。公式ドキュメントには、以下のように書いてあるんだけど、具体的にどうダメなのか見ていきたい。
Warning: consider KEYS as a command that should only be used in production environments with extreme care. It may ruin performance when it is executed against large databases. This command is intended for debugging and special operations, such as changing your keyspace layout.
警告: KEYSは十分に注意した上で本番環境で使うべき。KEYSは大きなデータセットで実行された場合はパフォーマンスに大きな影響がある。このコマンドはデバッグやキーのレイアウトを返る等の特別な場合のみに使われるべきである。
実験
- CentOS Linux release 7.4.1708 (Core)
- Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz
- DDR4 16GB RAM
- redis-server 5.0.7
の環境でそれぞれKEY、SCANを実行しながらredis-benchmarkのRPS(Request per second)を計測してみる。
準備
redis-serverをrunする
docker run --rm -it --name redis -p6379:6379 redis:5.0.7
redis-benchmarkの起動方法
redis-benchmark -t get -c 1
用意したプログラム(Rust)
Cargo.toml
[package]
name = "dont-use-redis-keys"
version = "0.1.0"
authors = ["yukinarit"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
redis = "*"
structopt = "*"
tokio = "0.1"
futures = "0.1"
main.rs
use std::time::Instant;
use futures::{
future::{loop_fn, Loop},
prelude::*,
stream,
};
use redis::{Client as Redis, Commands};
use structopt::StructOpt;
use tokio::runtime::Builder;
# [derive(StructOpt)]
enum Opt {
Setup {
/// Setup `count` K size of keys/values.
#[structopt(short = "c", long = "count", default_value = "1")]
count: usize,
},
/// Just continuously run "KEYS".
Keys,
/// Just continuously run "SCAN".
Scan,
/// Benchmarking "KEYS".
BenchKeys {
#[structopt(flatten)]
opt: BenchOpt,
},
/// Benchmarking "SCAN".
BenchScan {
#[structopt(flatten)]
opt: BenchOpt,
},
}
# [derive(StructOpt)]
struct BenchOpt {
/// Total number of requests.
#[structopt(short = "c", long = "count", default_value = "1")]
count: usize,
/// Number of parallel connections.
#[structopt(short = "p", long = "pipeline", default_value = "1")]
pipeline: usize,
}
fn main() {
let opt = Opt::from_args();
let mut redis = Redis::open("redis://localhost:6379").expect("Coundn't connect Redis");
let mut rt = Builder::new().core_threads(1).build().unwrap();
let start = Instant::now();
match opt {
Opt::Setup { count } => {
let mut conn = redis.get_connection().unwrap();
for n in 0..count {
let data: Vec<_> = (0..1000)
.map(|v| {
let v = n * 1000 + v;
vec![format!("key{}", v), format!("val{}", v)]
})
.flatten()
.collect();
let _: () = redis::cmd("MSET").arg(data).query(&mut conn).unwrap();
}
println!("Elapsed: {} msec", (Instant::now() - start).as_millis());
}
Opt::Keys => loop {
let mut conn = redis.get_connection().unwrap();
loop {
let val: Vec<String> = redis::cmd("KEYS").arg("key0").query(&mut conn).unwrap();
println!("Got {}", val[0]);
}
},
Opt::Scan => {
let mut conn = redis.get_connection().unwrap();
loop {
conn.scan_match("key0").unwrap().for_each(|s: String| {
if s == "key0" {
println!("Got {}", s);
}
});
}
}
Opt::BenchKeys { opt } => {
let count = opt.count;
let f = redis
.clone()
.get_shared_async_connection()
.map_err(|e| eprintln!("{}", e))
.and_then(move |conn| {
stream::iter_ok::<_, ()>(0..opt.count)
.map(move |n| {
redis::cmd("KEYS")
.arg(format!("key{}", n))
.query_async(conn.clone())
.map(|(_, val): (_, Vec<String>)| {
if !val.is_empty() {
println!("{}", val[0]);
}
})
.map_err(|e| eprintln!("{}", e))
})
.buffered(opt.pipeline)
.for_each(|_| Ok(()))
});
rt.block_on(f).unwrap();
println!(
"RPS: {}",
count as f64 / (Instant::now() - start).as_secs_f64()
);
}
Opt::BenchScan { opt } => {
let count = opt.count;
let f = redis
.clone()
.get_shared_async_connection()
.map_err(|e| eprintln!("{}", e))
.and_then(move |conn| {
stream::iter_ok::<_, ()>(0..opt.count)
.map(move |n| {
loop_fn((conn.clone(), 0), move |(conn, cursor)| {
redis::cmd("SCAN")
.arg(cursor)
.arg("MATCH")
.arg(format!("key{}", n))
.query_async(conn)
.and_then(|(conn, (cursor, val)): (_, (u32, Vec<String>))| {
if !val.is_empty() {
println!("{}", val[0]);
}
if cursor == 0 {
Ok(Loop::Break((conn, cursor)))
} else {
Ok(Loop::Continue((conn, cursor)))
}
})
.map_err(|e| eprintln!("{}", e))
})
})
.buffered(opt.pipeline)
.for_each(|_| Ok(()))
});
rt.block_on(f).unwrap();
println!(
"RPS: {}",
count as f64 / (Instant::now() - start).as_secs_f64()
);
}
}
}
- テストデータ作成
cargo run -- setup -c <NUM_KEYS>
- KEYSを続けて実行し続ける
cargo run -- keys
- SCANを続けて実行し続ける
cargo run -- scan
結果
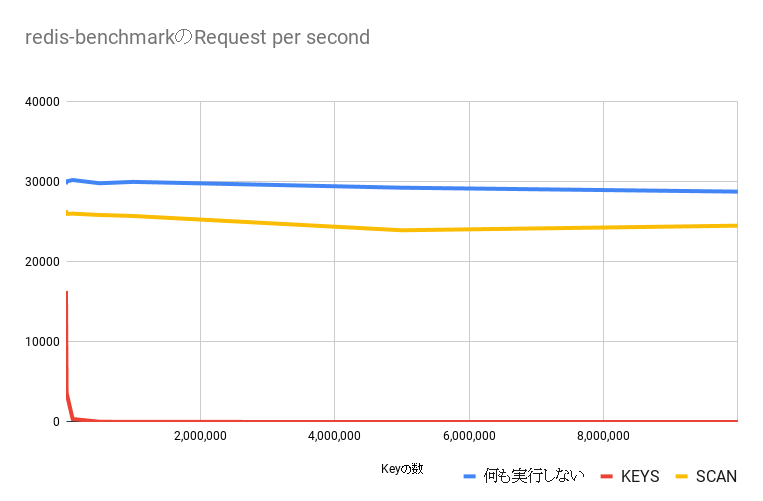
KEYSの場合、Redisのキーを増やていくとredis-benchmarkのRPSが著しく遅くなる。SCANは何もしていない場合と比べて若干遅いが、キーの数が増えてもRPSは安定している。
計測結果の生データは以下。
なにも実行してない場合の結果
| keyの数 | redis-benchmarkのRPS |
|---|---|
| 1,000 | 29638.41 |
| 10,000 | 29994.00 |
| 100,000 | 30165.91 |
| 500,000 | 29761.91 |
| 1,000,000 | 29931.16 |
| 5,000,000 | 29205.61 |
| 10,000,000 | 28719.13 |
`KEYS`を実行し続けた場合の結果
| keyの数 | redis-benchmarkのRPS |
|---|---|
| 1,000 | 16353.23 |
| 10,000 | 3630.82 |
| 100,000 | 373.79 |
| 500,000 | 31.03 |
| 1,000,000 | 14.02 |
| 5,000,000 | 2.52 |
| 10,000,000 | 1.08 |
`SCAN`を実行し続けた場合の結果
| keyの数 | redis-benchmarkのRPS |
|---|---|
| 1,000 | 26413.10 |
| 10,000 | 25940.34 |
| 100,000 | 25974.03 |
| 500,000 | 25806.45 |
| 1,000,000 | 25680.53 |
| 5,000,000 | 23900.57 |
| 10,000,000 | 24473.81 |
結論
-
KEYSはRedis全体のKeyの数に対して**O(N)** - Redisのメインの処理は**
シングスレッド**で行われる - 本番環境では
KEYSではなくSCANを使うこと - Redisのスレッドを完全にblockしてもいい場合のみだけ
KEYSを使おう - これらのことは全てドキュメントに書いてある