RediSearchとは?
RediSearchとはRedisをベースに作られたオープンソースの全文検索・セカンダリインデックスエンジン。開発元はRedisの作者であるSalvatore Sanfilippo氏も在籍しているRedis Labs, inc. Redisをベースにしているだけあって速度を売りにしている。
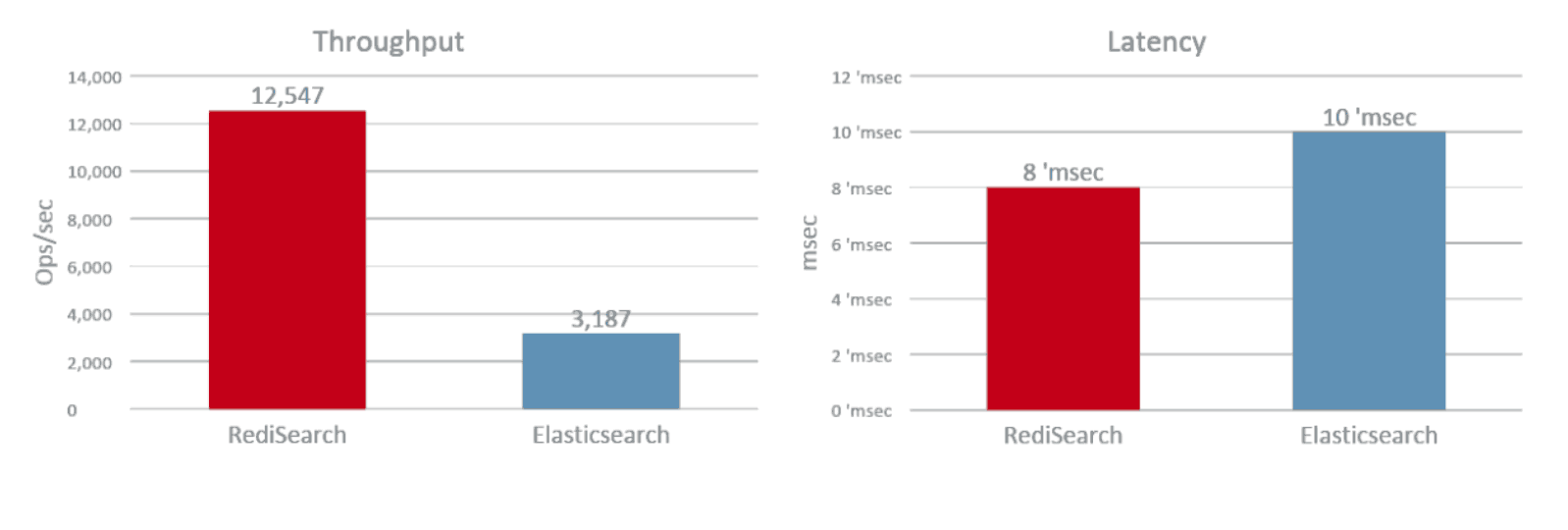
Redis Labsのホワイトペーパーによると、Elasticsearchと比べてスループットで4倍ほどの差があるようだ。なぜこれだけのパフォーマンスが出せるのかというと、もちろんRedisをベースにしているのもあるが、RediSearch自体がRedisModuleというRedisを拡張するAPIを使ってC言語で書かれているためだ。

余談だが、RedisModuleを使った他のOSSとしてrediSQLというRedisでSQLを実行するなかなか野心的なOSS(しかもRustで書かれている!)もあるので興味がある人はみてほしい。
ちなみに本記事はv1.6.14時点の情報になります。**v1.6.14時点では日本語の全文検索に対応していない**ので期待された方はそっ閉じしてください。
Installation
docker run -p 6379:6379 redislabs/redisearch:latest
ソースからインストールしたい人はこちらを参照。
スキーマ作成(FT.CREATE)
RediSearchは他のRedisのデータ構造と違ってドキュメントを追加する前にスキーマを定義しないといけない。
FT.CREATE <INDEX名> <INDEXオプション> SCHEMA <FIELD名> <FIELDの型> <FIELDオプション>...
- フィールドの数には1024の制限がある。そのうちTEXTフィールドの最大個数は128個
- フィールドの型
-
TEXT: テキスト型 -
NUMERIC: 数値型 -
GEO: 緯度経度座標
-
- よく使いそうなオプション
-
NOHL: HighlightをOffにすることでメモリを節約できる -
NOFIELDS: 各Fieldを保存しないことによってメモリを節約できる -
NOFREQS: Term frequency(頻出度)を保存しないことによってメモリを節約できる
-
- よく使いそうなフィールドオプション
-
SORTABLE: FT.SEARCHコマンドでSORTABLE指定できるようになる
-
例:ポケモンのデータのスキーマを作ってみる
FT.CREATE pokemon SCHEMA id NUMERIC name TEXT name_ja TEXT hp NUMERIC attack NUMERIC defence NUMERIC sp_attack NUMERIC sp_defence NUMERIC speed NUMERIC
ドキュメントを追加する(FT.ADD)
FD.ADD <INDEX名> <DocID> <Score> <OPTIONS> FIELDS <FIELD名> <FIELDの値>...
-
DocID: ドキュメントの識別子 - よく使いそうなオプション
-
REPLACE: SQLのUpseart的な動きをする。新規作成or既存を削除して再作成 -
PARTIAL:REPLACE指定の時だけ有効。いくつかのフィールドを省略すると既存の値がそのまま残るようになる
-
例:フシギダネのドキュメントをpokemonインデックスに追加する
FT.ADD pokemon Bulbasaur 1.0 FIELDS id 1 name Bulbasaur hp 45 attack 49 defence 49 sp_attack 65 sp_defence 65 speed 45
するとRedisには以下のようなキーが作成されます。
127.0.0.1:6379> keys *
1) "ft:pokemon/bulbasaur"
2) "nm:pokemon/defence"
3) "nm:pokemon/sp_attack"
4) "nm:pokemon/hp"
5) "idx:pokemon"
6) "nm:pokemon/attack"
7) "Bulbasaur"
8) "nm:pokemon/id"
9) "nm:pokemon/sp_defence"
10) "nm:pokemon/speed"
このうち"Bulbasaur"はHashでできていて、中を覗くとこんな感じになってます。
127.0.0.1:6379> hgetall "Bulbasaur"
1) "id"
2) "1"
3) "name"
4) "Bulbasaur"
5) "hp"
6) "45"
7) "attack"
8) "49"
9) "defence"
10) "49"
11) "sp_attack"
12) "65"
13) "sp_defence"
14) "65"
15) "speed"
16) "45"
他のキーはRediSearchが管理するインデックスデータで、普通のコマンドでは中を見ることはできません。
127.0.0.1:6379> type "ft:pokemon/bulbasaur"
ft_invidx
127.0.0.1:6379> type "nm:pokemon/defence"
numericdx
ちなみに、スキーマ定義にないフィールドを含めるとインデックスは作成されませんが、Hashにはちゃんと登録されます。なので、Redisをアプリケーションのデータベースとして使いながら、ドキュメントの特定のフィールドのみインデックス化というような使い方もOK。
検索する(FT.SEARCH)
FT.SEARCH <インデックス名> <クエリ> <オプション>
- よく使いそうなオプション
-
NOCONTENT: docidのみ検索結果に表示する -
LIMIT first num: 表示件数。デフォルトは0 10。なぜデフォルト上限が10なのか...無限であるべきなのでは... -
SORTBY field [ASC|DESC]:SORTABLEがついているフィールドでソートする -
WITHSORTKEYS:SORTABLEがついているフィールドでソートする
-
-
名前でテキスト検索する
FT.SEARCH pokemon Bulbasaur -
フィールド指定でテキスト検索する
FT.SEARCH pokemon "@name:Bulbasaur" -
ワイルドカードを使う
FT.SEARCH pokemon "@name:Bul*" -
NUMERICフィールドの範囲指定で
idが1のポケモンを検索するFT.SEARCH pokemon "@id:[1 1]" -
hpが100以上150以下のポケモンを検索するFT.SEARCH pokemon "@hp:[50 100]" -
hpが100以上150以下かつattachが100以上150以下のポケモンを検索するFT.SEARCH pokemon "@hp:[50 100] @attack:[50 100]"
性能
やはり性能は気になるところ。Redisに作られたHashから直接HGETALLするのとFT.SEARCHで検索した場合の速度を比較してみる。
条件
-
CentOS 7.4 / i7-7700 8cores 3.6GHz / DDR4 16GB RAM
-
RediSearchは以下のコマンドで実行
docker run --network host -t redislabs/redisearch:1.6.14
-
同じホスト上のredisearchコンテナに対して
redis-benchmarkを使ってスループットを検証する- オプションは
-c 64 -P 1と-c 64 -P 128の二通り
- オプションは
結果
-
GETでデータを取得する
$ redis-benchmark -c 64 -P 1 -n 1000000 get foo 151492.20 requests per second $ redis-benchmark -c 64 -P 128 -n 5000000 get foo 3259452.25 requests per second -
HGETALLでデータを取得する
$ redis-benchmark -c 64 -P 1 -n 1000000 hgetall Bulbasaur 129617.62 requests per second $ redis-benchmark -c 64 -P 128 -n 5000000 hgetall Bulbasaur 838363.50 requests per second -
完全一致検索
$ redis-benchmark -c 64 -P 1 -n 1000000 FT.SEARCH pokemon Bulbasaur 47714.48 requests per second $ redis-benchmark -c 64 -P 128 -n 1000000 FT.SEARCH pokemon Bulbasaur 58840.83 requests per second -
ワイルドカードによる前方一致検索
$ redis-benchmark -c 64 -P 1 -n 1000000 FT.SEARCH pokemon "@name:Bul*" 36892.20 requests per second $ redis-benchmark -c 64 -P 128 -n 1000000 FT.SEARCH pokemon "@name:Bul*" 39684.12 requests per second -
NUMERICフィールドの範囲検索する
$ redis-benchmark -c 64 -P 1 -n 1000000 FT.SEARCH pokemon "@id:[1 1]" 57773.41 requests per second $ redis-benchmark -c 64 -P 128 -n 1000000 FT.SEARCH pokemon "@id:[1 1]" 62410.28 requests per second
RediSearch 2ではどうなる?
RediSearch 2は2020/9/18にリリースされた最新バージョンで1系とは非互換です。一番の変更点としては、従来インデックスへの追加をFT.ADDを使わなくてHSETでできるようになったことがあります。一方、データ構造がHASHに限定されてしまう(今後HASH以外もサポートしていくとのこと)デメリットもあります。
ここでは、RediSearch2は詳しく紹介しませんが、同じくベンチマークを取ったので見ていきます。
-
インデックス作成
$ FT.CREATE idx:pokemon on hash prefix 1 pokemon: SCHEMA id NUMERIC name TEXT name_ja TEXT hp NUMERIC attack NUMERIC defence NUMERIC sp_attack NUMERIC sp_defence NUMERIC speed NUMERIC -
完全一致検索
$ redis-benchmark -c 64 -P 1 -n 1000000 FT.SEARCH pokemon Bulbasaur 43965.71 requests per second $ redis-benchmark -c 64 -P 128 -n 5000000 FT.SEARCH pokemon Bulbasaur 50563.79 requests per second -
ワイルドカードによる前方一致検索
$ redis-benchmark -c 64 -P 1 -n 1000000 FT.SEARCH pokemon "@name:Bul*" 28401.02 requests per second $ redis-benchmark -c 64 -P 128 -n 1000000 FT.SEARCH pokemon "@name:Bul*" 31661.60 requests per second -
NUMERICフィールドの範囲検索する
$ redis-benchmark -c 64 -P 1 -n 1000000 FT.SEARCH pokemon "@id:[1 1]" 43620.50 requests per second $ redis-benchmark -c 64 -P 128 -n 1000000 FT.SEARCH pokemon "@id:[1 1]" 54071.59 requests per second
RediSearchをつかうべきか
- 性能を気にしない単純なキーの検索=>
KEYSやSCANでキー文字列を検索すればよい - 複数の条件で検索したい=>
RediSearchが良いかも - SQLで検索したい=>
rediSQLが使えるかも。が、そもそも本当にRedisでやるべきかも検討したほうがいい
まとめ
RediSearchを業務で使ってみたので紹介してみました。筆者的にはRediSearchはすでにProduction readyでRedisをヘビーにつかっていて検索等が多いプロジェクトなら導入の検討の価値ありだと思います。