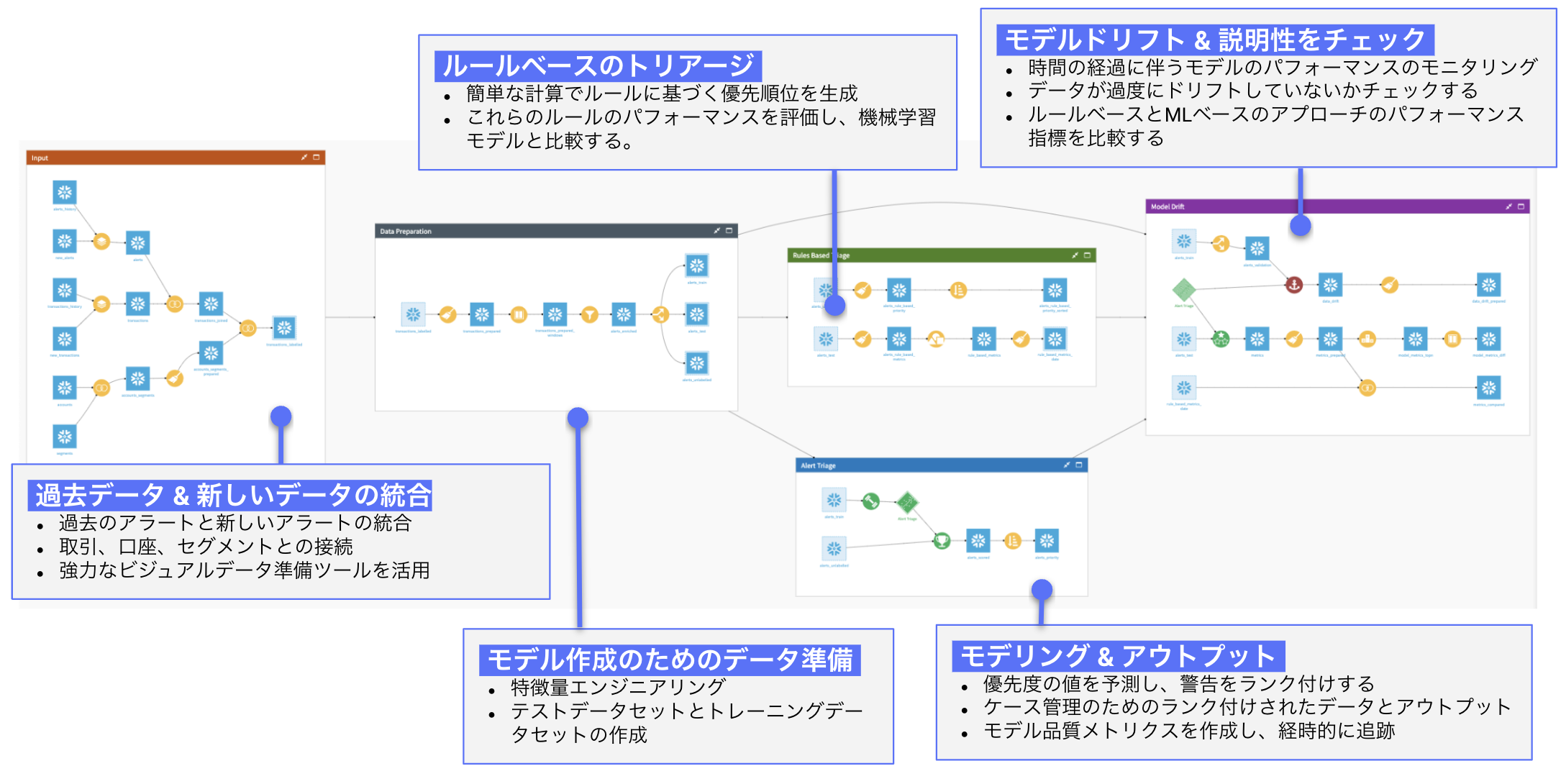
実際のフロー
トップページ
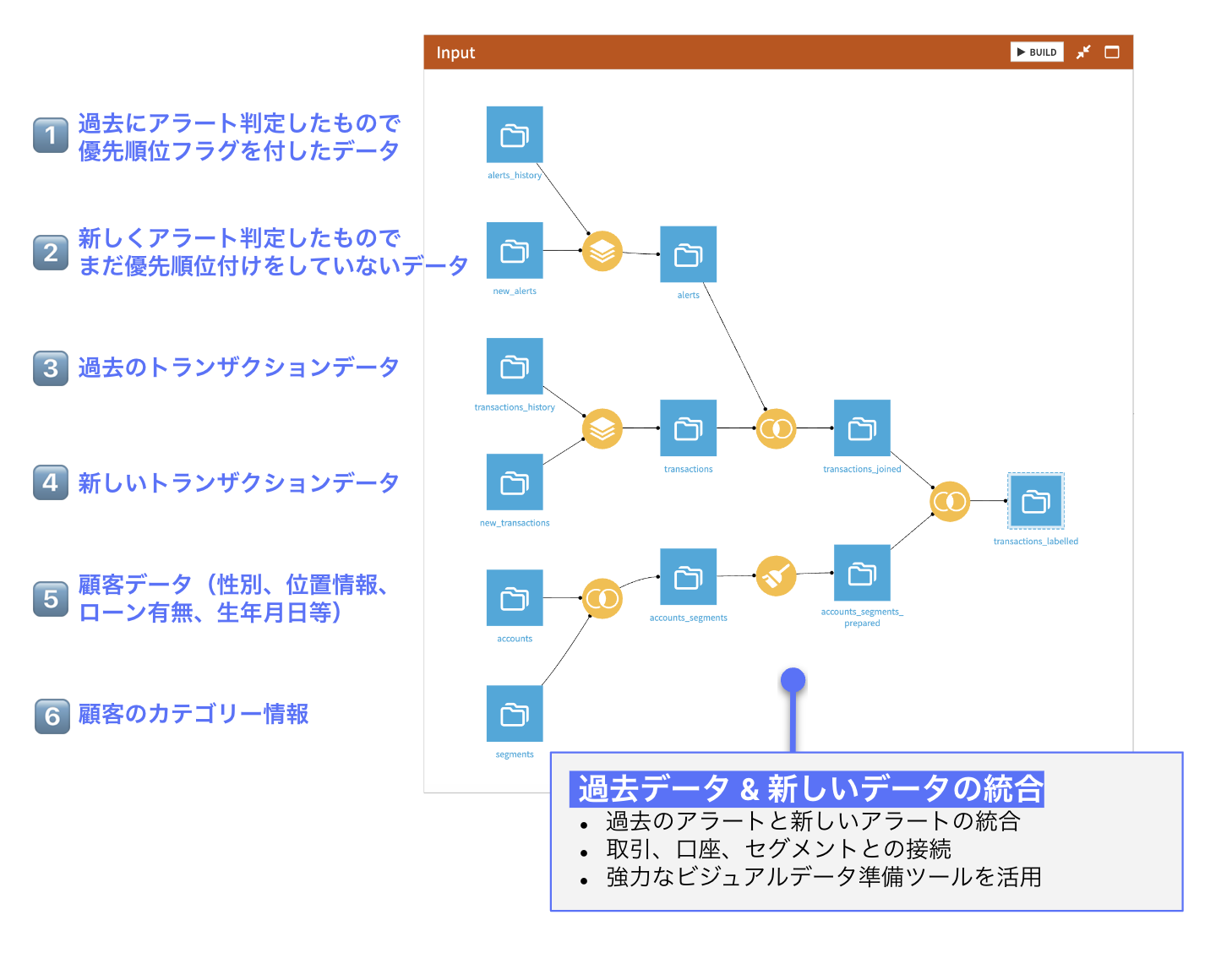
インプットデータ
概要
このテンプレートの目的は、金融犯罪のアナリストに、Dataikuを使用して、リスクの可能性の優先順位付けと、使用したビジネスルールの有効性のレビューを通じて、初期評価をサポートする方法を示すことです。 このソリューションの詳細については、ナレッジベースをご覧ください。
このテンプレートは、ラベル付きの履歴(つまり、調査後に真か偽であることがわかっている)アラートを使用して、「真陽性」アラートの機械学習予測モデルを作成します。このモデルは、新しい (ラベルのない) アラートの優先度スコアを生成し、ケース管理システムへの入力の準備が整ったランク付けされたテーブルを出力します。
対象とするユーザー
- 業界: 金融
- 部門: AML, オペレーション, リスクマネジメント
- ペルソナ: AML Case Manager, Model Reviewer, AML Team Lead, AML Data Scientist
テンプレートの詳細
コンテクスト
マネーロンダリング対策 (AML) プロセスは通常、 KYC 、アラート生成、調査、ケース管理などのいくつかの一連のコンポーネントを組み立てます。このプロセスにおける重要な問題点の 1 つは、アラート生成によって出力される誤検知がかなりの割合で発生することにあります。規制により、すべてのアラートを処理する必要があり、ルールによって生成されたアラートの変更は複雑な作業となる場合があります。したがって、アラートに優先順位を付ける方法を見つけることで、コンプライアンス担当者の効率を大幅に向上させることができます。これがこのプロジェクトの目的です。
アラートの生成
AML セットアップの主要部分の 1 つは、アラートをトリガーするトランザクション監視です。顧客情報は、KYC とエンティティ解決を使用して収集および整理されます。特に、この最初のステップにより、同じルールを適用できる同様の行動を持つ顧客のセグメントを作成できます。次に、コンプライアンス担当者は専門知識を活用して、合法的な取引と違法な取引を区別し、アラートをトリガーするしきい値を設定するのに役立つ重要な機能を作成します。異常検出を可能にする教師なし学習手法を使用して一部の機械学習ルールも設定されている場合、インテリジェンスの層を追加することもできます。このプロセスは定期的にバッチで実行され、調査員が規制当局に報告することを意味するエスカレーションを行うか、調査を終了する必要があることを示すアラートが生成されます。
アラートの優先順位付け
アラートがトリガーされると、コンプライアンス チームはアラートをすべて処理する法的義務があります。残念ながら、アラートのほとんど (約 95%) は誤ったアラートであるため、無関係なアラートを閉じるのに不釣り合いな時間が費やされます。したがって、これらの調査済みアラートは、調査者の結論を知った上で、時間の経過とともにラベルを付けることができます。ラベル付きアラートを使用すると、本物のアラートと誤ったアラートを区別するための 2 クラス分類予測モデルを構築できます。このモデルは、2 クラス分類を生成するためにしきい値と比較される確率も提供します。アラートがエスカレーションされる確率は優先度スコアとして解釈でき、1 に近い値を持つものが最初に調査され、0 に近いものはバックログに残される可能性があります。
モデルの説明可能性
金融機関における AML は規制対象領域であり、モデルを広範に説明、理解、文書化することが求められます。AML のモデルの説明可能性については、このドキュメントで説明されています。モデルが必ずしもホワイト ボックスである必要があるという意味ではありません。より複雑なモデルも検討できますが、モデルがどのように機能するかを正確に理解するには分析する必要があります。したがって、パフォーマンスだけが管理される指標ではありません。モデルは全体像のグローバルな説明を通じて記述され、その後、ローカルな説明によってさらに調査されます。モデルのドリフトも時間の経過とともに監視され、パフォーマンスが許容範囲内に保たれていることを確認します。
モデルの説明可能性は、AML プロセスの重要なコンポーネントです。コンプライアンス チームは、使用しているモデルがどのように動作するかを正確に理解し、特定の条件下でモデルが壊れないことを確認する必要があります。の中にダッシュボード では、これらの説明を調査できる主要コンポーネントについて説明します。
モデルの説明可能性
全体的な説明
モデルがどのように機能するかを理解する最初の方法は、変数重要度グラフを確認することです。

このグラフは、モデル内の各変数の寄与を表します。したがって、モデルがどの変数に最も依存しているのか、またどの変数がモデルの予測にあまり役に立たないかを理解することができます。ここで、orig_is_escalated_avg 変数が最も重要です。これは、トランザクションの開始者に対するエスカレーションされたトランザクションの頻度です。ビジネスの観点から見ても当然のことでしょう。その他の重要な変数には、金額、orig_is_alert_avg (発信者のトランザクション間のアラートの頻度)、および顧客がセグメント 4 に属しているかどうかが含まれます。
もう 1 つの興味深いビューは、部分依存プロットです。
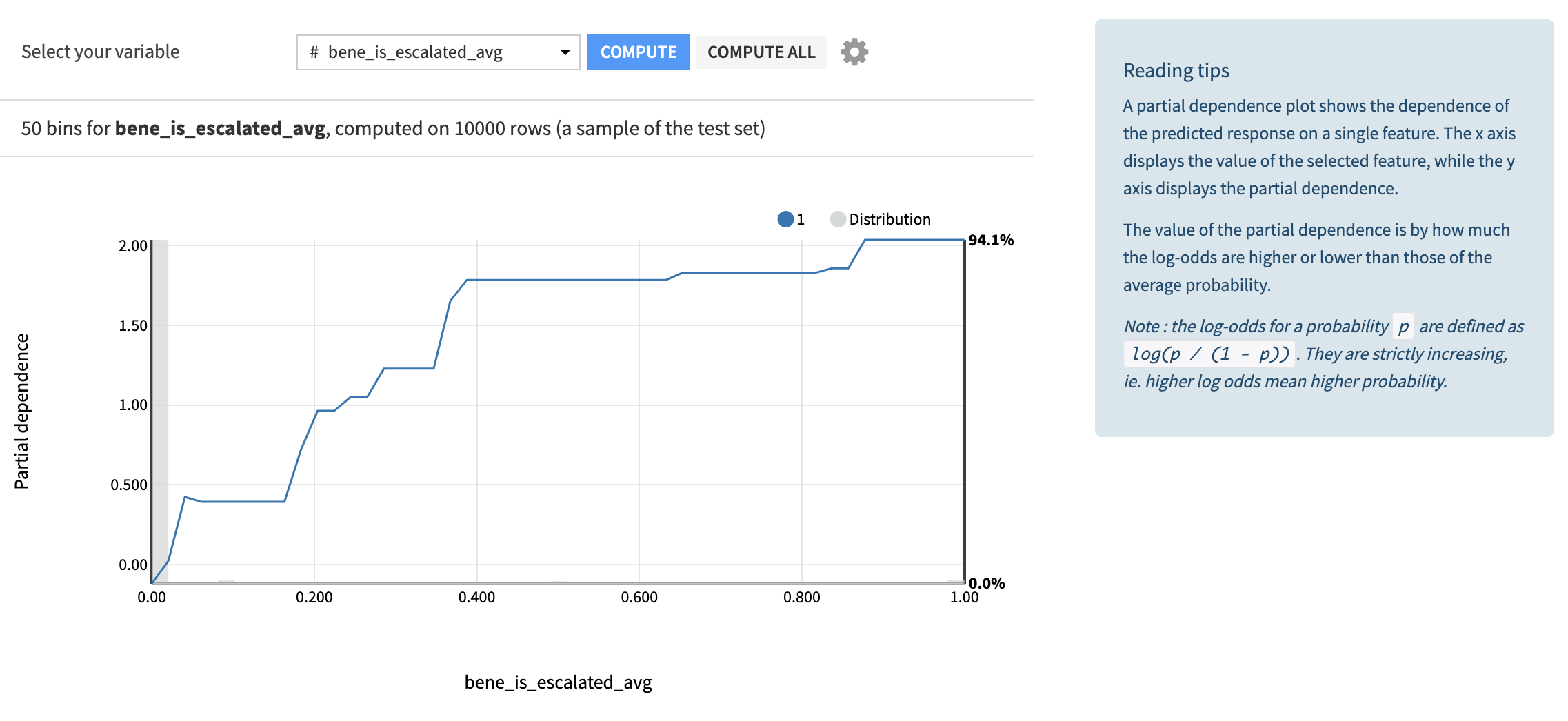
このグラフは、データセット内の各変数について、この指定された変数に対するターゲットの依存関係をプロットします。最も重要な変数の依存関係を観察して、曲線の形状が直感と一致しているかどうかを確認するのは興味深いことです。たとえば、is_escalated_avg 変数とターゲット確率との間の関係が増大することが予想され、実際にそれが観察されています。他の関係は少し驚くべきものである可能性があり、is_alert_avg とターゲットの量の間の減少関係のように、さらに調査できる可能性があります。
個別説明
個別の説明は、もう少し深く掘り下げて、モデルがどのように動作するかをはるかに小さい粒度で調査することを目的としています。これを行うための非常にインタラクティブな方法は、インタラクティブなスコアリング ビューを探索することです。
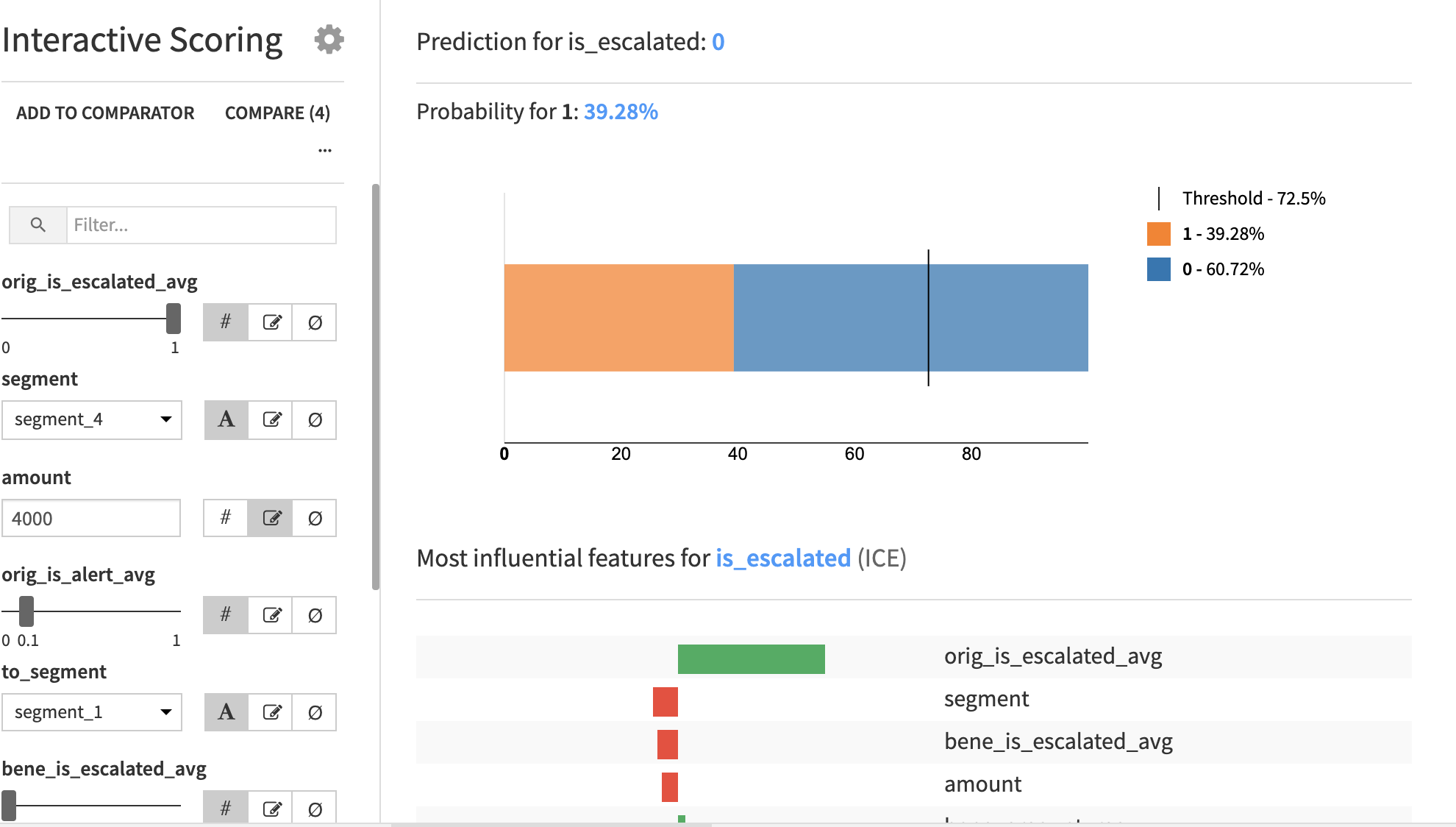
ユーザーは各機能の値を変更し、モデルからの出力を観察できます。モデルは確率を計算し、この確率がしきい値を超えている場合、予測は 1、それ以外の場合は 0 になります。予測とともに最も影響力のある特徴は、これらの特徴は特徴の値に応じて変化する可能性があります。興味深いデータ ポイントをコンパレータに追加して並べて比較できます。

特徴の 1 つを変更するだけで、確率が大きく変動し、最も影響力のある特徴も同様に変化します。
個別の説明と呼ばれるもう 1 つのウィンドウは、極端な確率に焦点を当てています。
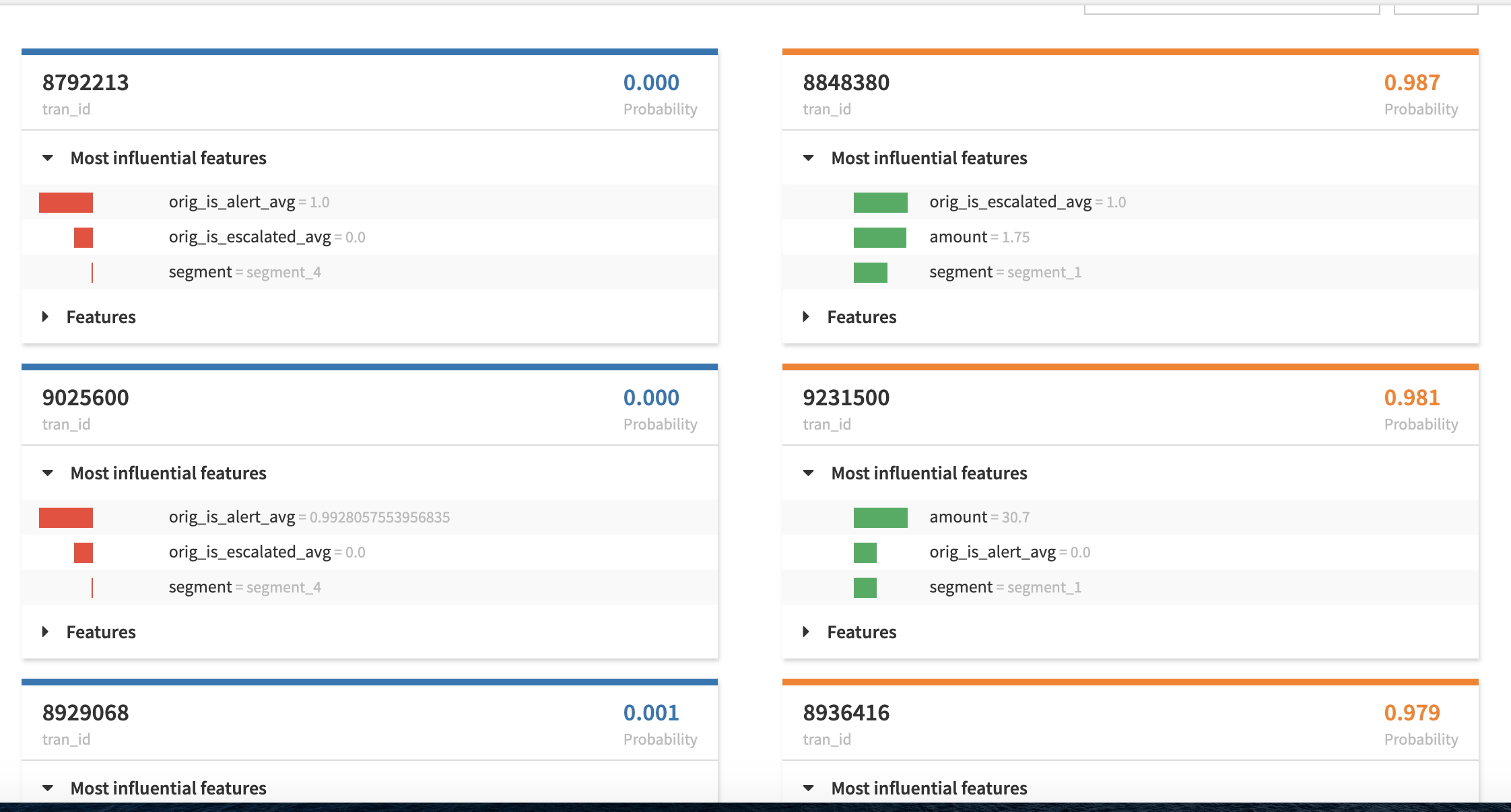
そこでは、インタラクティブなスコアリングと同様に、これらの予測を推進した最も影響力のある機能が提供されます。このビューにより、上位および下位の予測がどのように行われたか、およびどの変数が最も大きな影響を及ぼしたかに関するパターンを検出できます。
ドリフト
たとえば、新しいデータが毎日または毎週の間隔で入力されるような動的な設定では、時間が経過してもモデルが十分に良好であることを保証するには、静的な説明があるだけでは十分ではありません。これが、ドリフトを注意深く監視する必要がある理由です。それはすでに行われていますここでは、パフォーマンス指標に従ってください。以内に達成することもできます。評価ストアビュー:
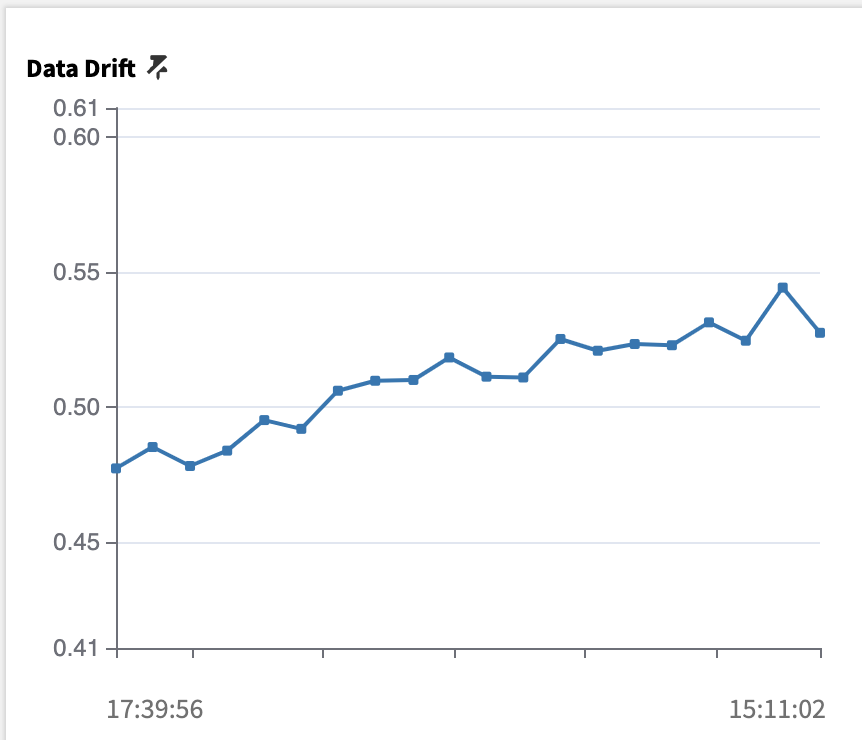
評価ストアを開くと、モデルの経時的なパフォーマンスを確認するための履歴メトリックが表示されます。特に、データが元の状態からどの程度変化したかを確認するために、データ ドリフト メトリックを固定しました。計算は、2 つのデータセットを区別するためにランダム フォレスト分類器をトレーニングすることで構成されます。モデルが正確であればあるほど、2 つのデータセットはより区別しやすくなります。0.5 を超えると、データセットは区別可能であるとみなされ、より新しいデータでモデルを再トレーニングするなどの何らかのアクションを実行する必要があります。
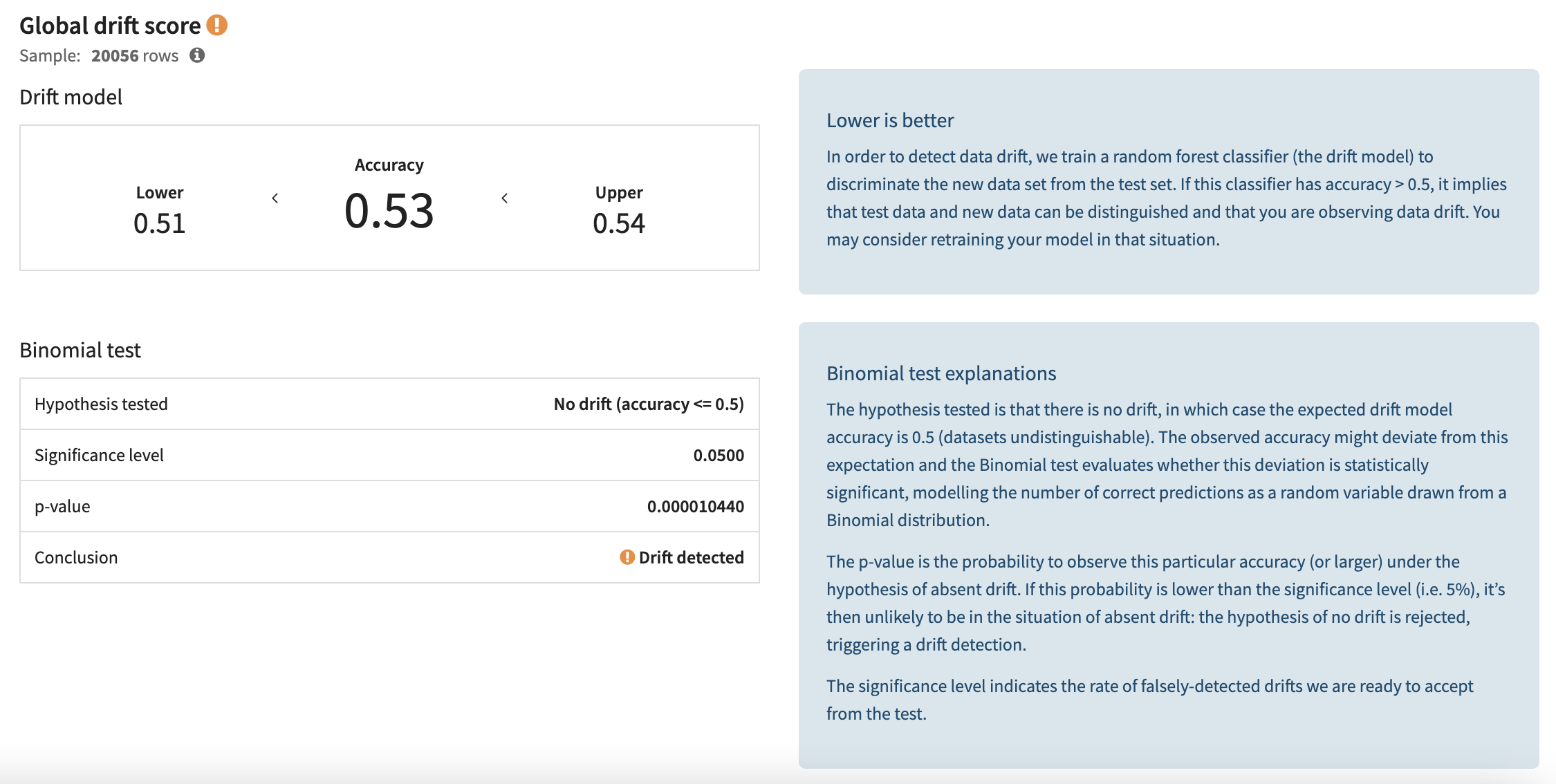
次に、最新の評価を選択し、ドリフト分析セクション内の入力データ ドリフト メニューに移動します。データ ドリフト スコアは、データがドリフトしたかどうかを確認するための二項テストとともに表示されます。ここで、テストの結論としては、何らかのドリフトが検出されたため、ユーザーはさらに調査し、より新しいデータを使用してモデルを再トレーニングすることを検討する必要があります。
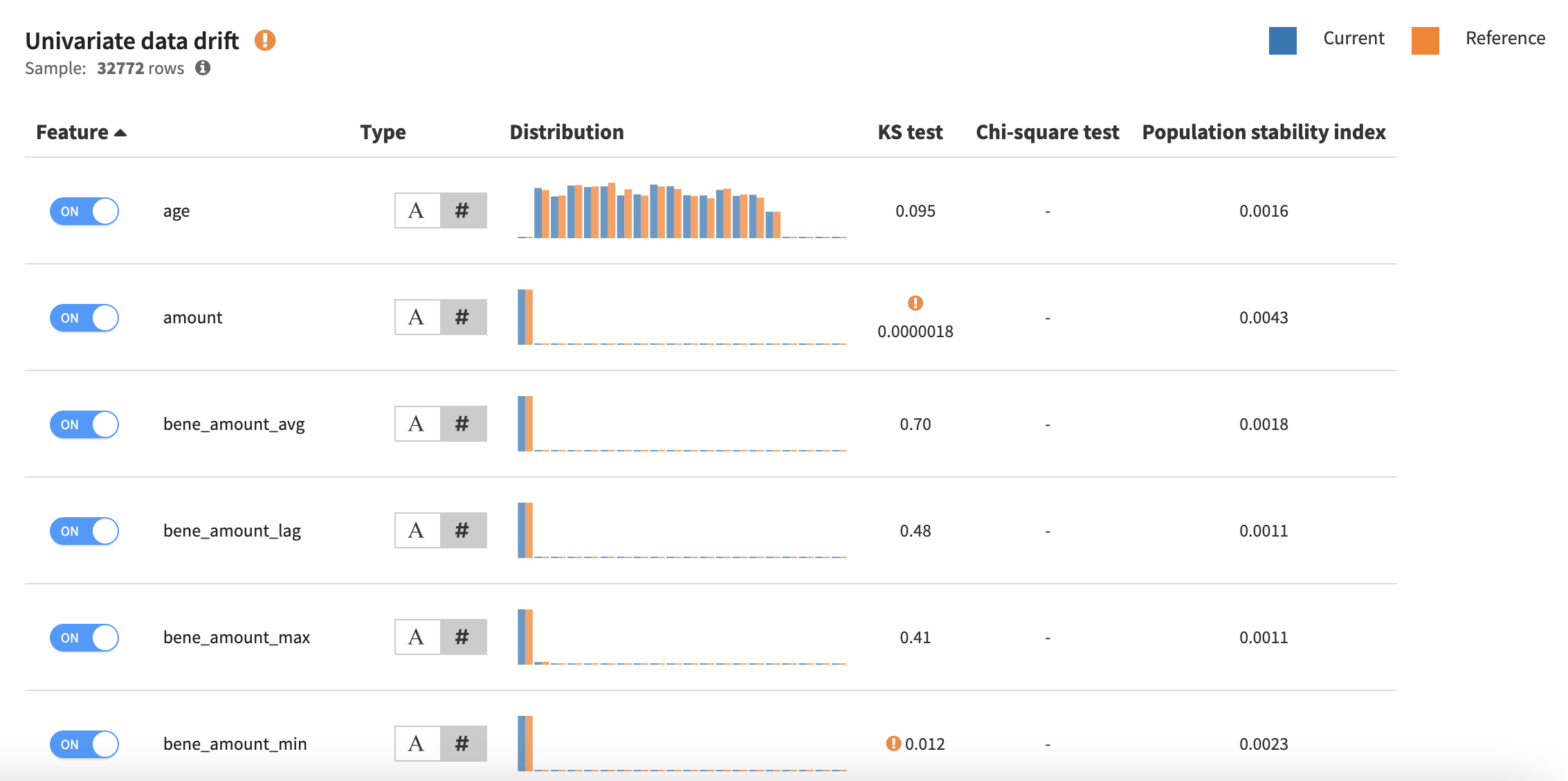
グローバル ビューの下で、各変数のドリフトが個別にチェックされます。ほとんどの変数は大幅に変動していませんが、amount や bene_amount_min などのいくつかの変数は感嘆符で強調表示されており、元の検証セットと新しい検証セットの間で分布が大きく変化していることを示しています。
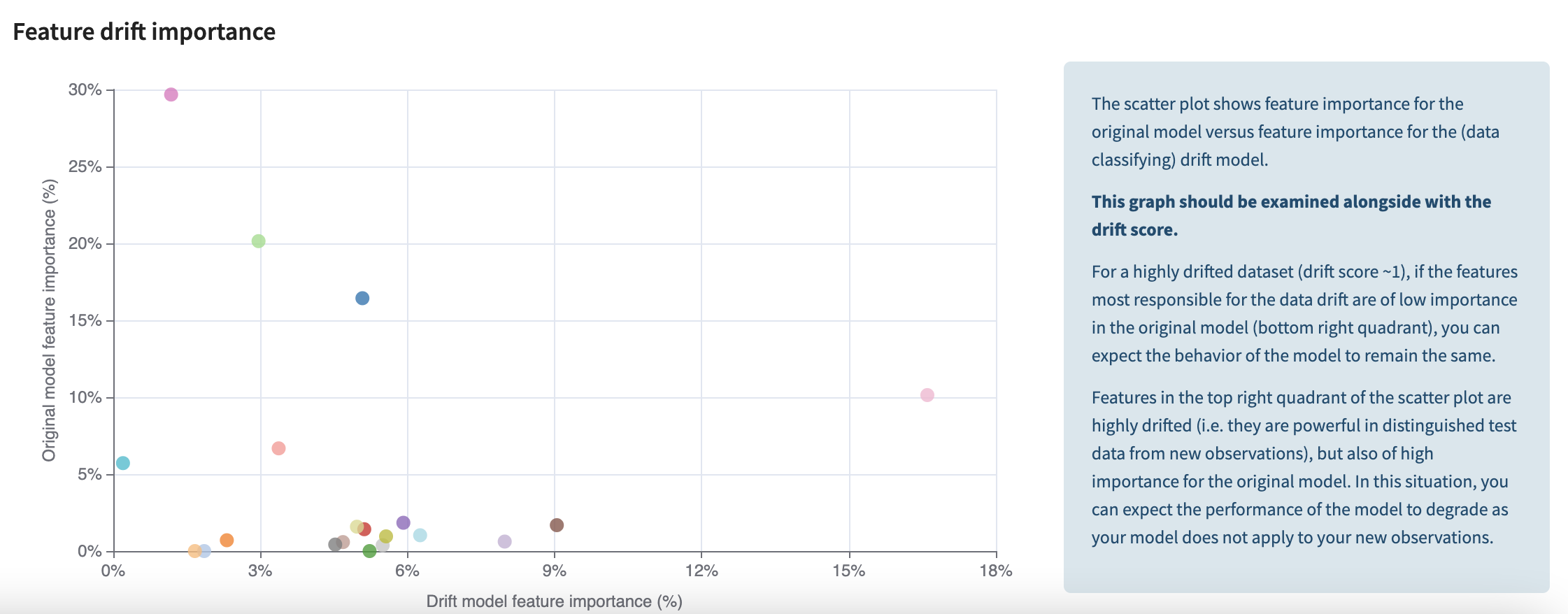
最後に、この非常に興味深いグラフは、変数の重要性と各変数のドリフト重要度をクロス分析します。y 軸は元のモデルの特徴の重要度を表し、x 軸は元のデータセットとドリフトされたデータセットを区別するドリフト モデルの特徴の重要度を表します。精査すべき変数は、右上の象限に位置する変数です。これらの変数は両方とも大幅に変動しており、モデルに大きな影響を与えています。右下にある変数は大きく変動していますが、モデル内ではそれほど重要ではないため、心配する必要はありません。同様に、左上の変数も重要なので注意深く監視する必要がありますが、ドリフトしていないようです。
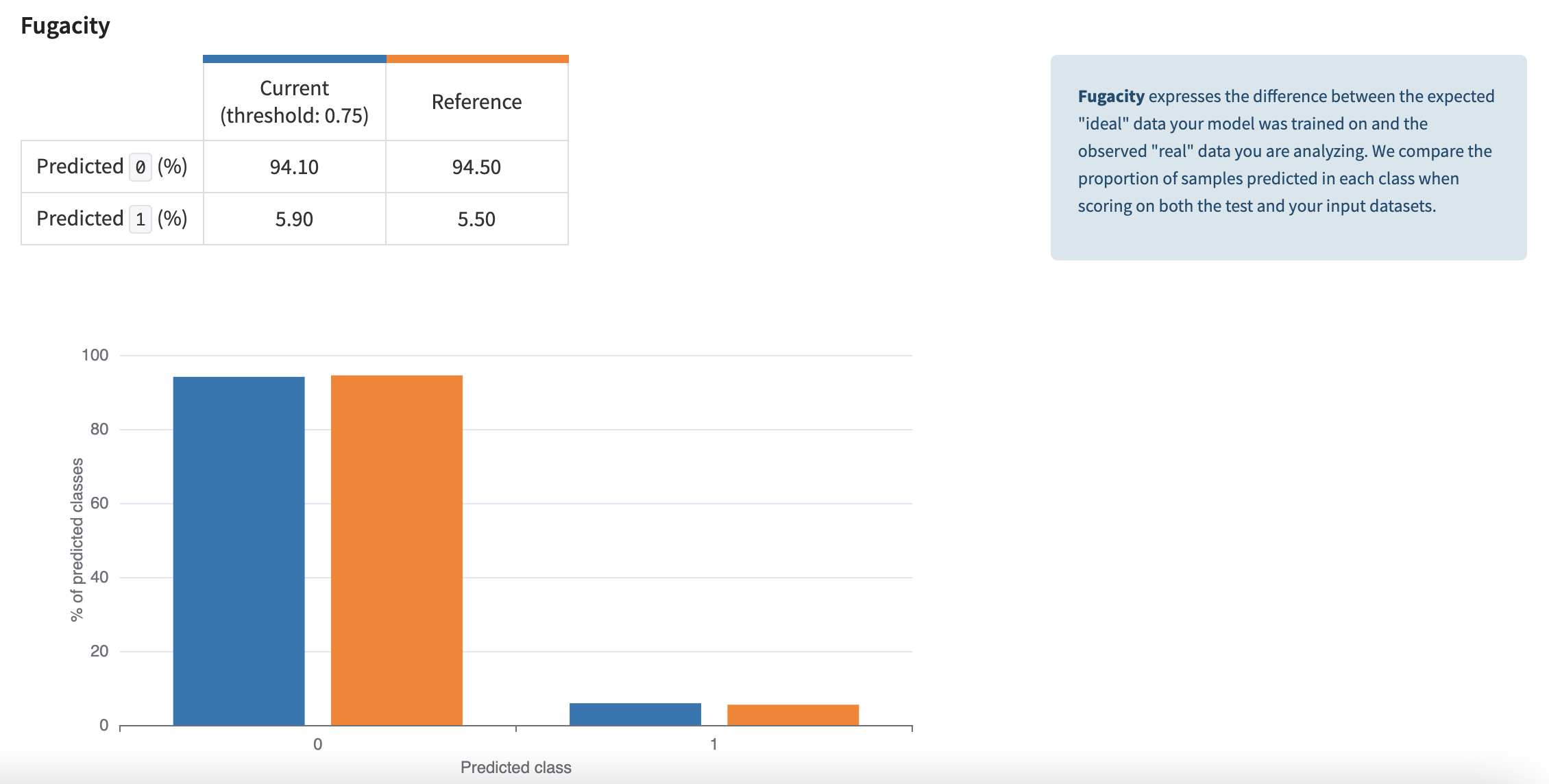
データが時間の経過とともにどのようにドリフトしたかを観察するもう 1 つの方法は、メニュー予測ドリフトのフガシティを調べることです。Fugacity は、2 つのデータセットの予測された各クラスの割合を比較します。これらの比率が大きく逸脱している場合は、ユーザーに警告を発する必要があります。
モデルの更新
パフォーマンス分析とデータドリフト分析の組み合わせからモデル更新の必要性が判明した場合、モデルを再トレーニングできます。フローでは、新しいデータが入力されるたびに更新されるため、トレーニング データセットは最新の状態になります。そのため、ユーザーはモデルを再トレーニングするだけで同じ構成を維持できます。その結果、上記のすべての説明が自動的に作成されます。この新しいモデルのデプロイを検証するために、デプロイされたモデルと新しくトレーニングされたモデルの間で説明と調査を並べて比較できます。両者に大きな違いがない場合は、追加の検証を行わずにモデルをデプロイできます。たとえば、以前は非常に重要だった変数が上位の変数から落ちた場合、アナリストは、なぜこれが起こったのか、そしてそれが正当化されるのかどうかを理解するために、より深く調査する必要があります。
自動化
このプロジェクトは、データが受信されるたびに時間の経過とともに更新されます。運用環境では、セットのトリガーが起動したときにプロセスのいくつかのステップが自動的に実行されるようにしたいと考えています。
スコアアラート
アラートのスコアリングは、自動化したい最も自然なプロセスです。トリガーは、最大日付を取得する SQL クエリです。new_alertsデータセット。データセットがより新しいデータで更新されると、シナリオが始まります。までの流れを再構築します。alerts_priorityデータセット。これは、アラートのバッチに優先順位を付けるために調査者によって使用される出力です。
このシナリオにはレポーターも追加され、新しいアラートがスコア付けされたことを自動的に警告し、受信者が直接閲覧できる優先順位付けされたアラートを含む電子メールを送信します。
モデルの評価
新しいラベル付きデータが入ってきたときは、この新しいデータに対してモデルを評価する自動プロセスを実行したいと考えています。特に、ドリフト。トリガーするには評価、SQL クエリも設定されていますが、アラート_ヒストリーデータセット。起動すると、ホールドアウト データセットを設定するための分割日 (alerts_test ) が変数内で変更され、データセットが複数の種類のドリフトを監視するまでフローが再構築されます。
モデルを再トレーニングする
これシナリオは例としてここにありますが、トリガーは関連付けられていません。起動すると、最新のデータを使用してモデルが再トレーニングされ、再デプロイされます。次に、ドリフトを監視するデータセットをクリアして、監視を最初から再開します。最後に、評価シナリオが呼び出されてメトリクスが初期化されます。
Dataiku : AML Alert Triage
Dataiku : Knowledge Base
Dataiku : 金融機関における AI: ワンストップのユースケース一覧