Firestore の自動生成 ID がどうやって生成されているのか気になったので、分かる範囲で調査してみました
擬似乱数あたりの話は詳しくないので補足などいただけるとうれしいです
TL;DR
- 各クライアント SDK で乱数を元に alphanumeric な20文字を生成
- ただの疑似乱数生成関数を使っている SDK もある
- UUID よりは安全でないと言えそう
自動生成 ID とは?
Firestore は .add(...) と .doc().set(...) メソッドを呼び出すと自動的に ID を生成してくれます
具体的には
db.collection('cities').add({
name: 'Tokyo',
country: 'Japan'
})
または
db.collection('cities').doc().set({
name: 'Tokyo',
country: 'Japan'
})
とすると以下のような ID のドキュメントが生成されます
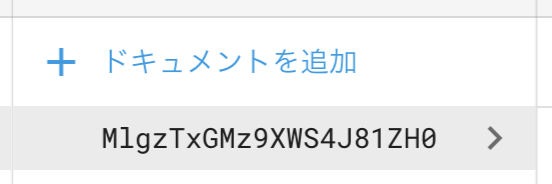
参考: https://firebase.google.com/docs/firestore/manage-data/add-data?hl=ja#add_a_document
コードを見るほうが早いと思うので載せていきます
iOS
iOS の Firebase SDK は主に Objective-C や C++ で書かれていて、ID 生成部分は C++ でした
namespace {
const int kAutoIdLength = 20;
const char kAutoIdAlphabet[] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
SecureRandom shared_random;
} // namespace |
std::string CreateAutoId() {
std::string auto_id;
auto_id.reserve(kAutoIdLength);
// -2 here because:
// * sizeof(kAutoIdAlphabet) includes the trailing null terminator
// * uniform_int_distribution is inclusive on both sizes
std::uniform_int_distribution<int> letters(0, sizeof(kAutoIdAlphabet) - 2);
for (int i = 0; i < kAutoIdLength; i++) {
int rand_index = letters(shared_random);
auto_id.append(1, kAutoIdAlphabet[rand_index]);
}
return auto_id;
}
Android
Java です
public class Util {
private static final int AUTO_ID_LENGTH = 20;
private static final String AUTO_ID_ALPHABET =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
private static final Random rand = new Random();
public static String autoId() {
StringBuilder builder = new StringBuilder();
int maxRandom = AUTO_ID_ALPHABET.length();
for (int i = 0; i < AUTO_ID_LENGTH; i++) {
builder.append(AUTO_ID_ALPHABET.charAt(rand.nextInt(maxRandom)));
}
return builder.toString();
}
}
JavaScript
Web アプリなどで使うクライアント SDK の方です
import { assert } from './assert';
export class AutoId {
static newId(): string {
// Alphanumeric characters
const chars =
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
let autoId = '';
for (let i = 0; i < 20; i++) {
autoId += chars.charAt(Math.floor(Math.random() * chars.length));
}
assert(autoId.length === 20, 'Invalid auto ID: ' + autoId);
return autoId;
}
}
Node.js
Admin SDK の方では @google-cloud/firestore という依存パッケージの中で生成していました
export function autoId(): string {
const chars =
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
let autoId = '';
for (let i = 0; i < 20; i++) {
autoId += chars.charAt(Math.floor(Math.random() * chars.length));
}
return autoId;
}
おまけ
ちなみに Realtime Database では Push ID という「タイムスタンプ+ランダムな値」を生成しているようです
参考
https://firebase.googleblog.com/2015/02/the-2120-ways-to-ensure-unique_68.html
https://gist.github.com/mikelehen/3596a30bd69384624c11
衝突しないの?
考えられる ID の総数を 122 ビットの UUID v4 と比較してみると
| UUID v4 | autoID |
|---|---|
| $$ 2^{122} = 5.3 * 10^{36} $$ | $$ 62^{20} = 7.4 * 10^{35} $$ |
ということで、
同様に確からしい (= 乱数が安全である) 場合わずかに UUID の方が衝突しにくい
という結果となりました
安全なの?
例えば Admin SDK (Node.js) で使われている Math.random() はただの疑似乱数生成関数なので偏りが生じるらしく、
乱数生成部分に暗号論的疑似乱数生成関数を使っているような ID の実装よりは衝突しやすいと言えそうです
例) node-uuid ライブラリでの実装
var crypto = require('crypto');
module.exports = function nodeRNG() {
return crypto.randomBytes(16);
};
参考:https://qiita.com/gakuri/items/27cca8f0fa28b78ddeca
まとめ
UUID と比較して衝突しやすい実装ではありますが
普通に使っている分には心配しなくていいのかなとも思いました
Firestore ではオフラインでも書き込めてしまうため RDB の auto_increment 的な戦略はとれないですが
どうしても気になるようであれば Admin SDK 経由で DocumentReference.create() を使うと良さそうです
(クライアント SDK には set しかないが Admin SDK なら set と create がある)
https://cloud.google.com/nodejs/docs/reference/firestore/1.3.x/DocumentReference#create
ちなみに
@soichisumi さんと @kahirokunn さんの tweet をきっかけに、以前調査して下書きに溜めていたものを加筆して投稿しました
大変参考になったので引用させていただきます![]()
JSのfirestoreのID生成ロジックがIDかぶりやすくてヤバいみたいな話を聞いたのですが、どこか出典があるんですかね🤔
— Soichi Sumi (@soichisumi) 2019年6月7日