この記事はJubatus Advent Calenderの23日目の記事です。
この記事ではJubatusのバースト検知機能(jubaburst)を実際に使ってみたいと思います。
バースト検知とは
バースト検知とは時系列データの中で特定のキーワードに関するデータが急激に増加(=バースト)したことを検知するアルゴリズムです。以下の図では個々のデータをドキュメントと呼称しています。
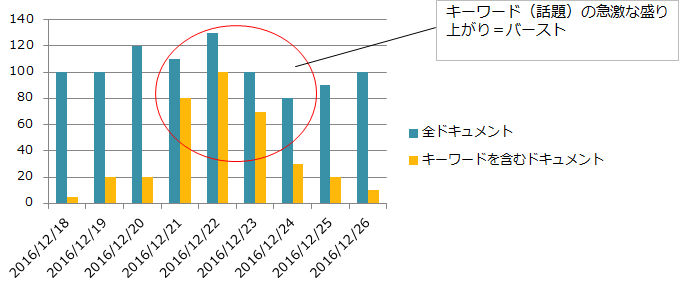
TwitterやFacebookのようなSNSで発信された投稿データ(時系列テキストデータ)を対象に、商品名やサービス名をキーワードとしてバースト検知を利用することで流行の発生などを素早くキャッチするなど、広告戦略などのビジネスに利用することができそうです。
Kleinbergのバースト検知
JubatusではKleinbergがBursty and Hierarchical Structure in Streamsで示したバースト検知アルゴリズムのうち、離散データに対する手法を実装しています。
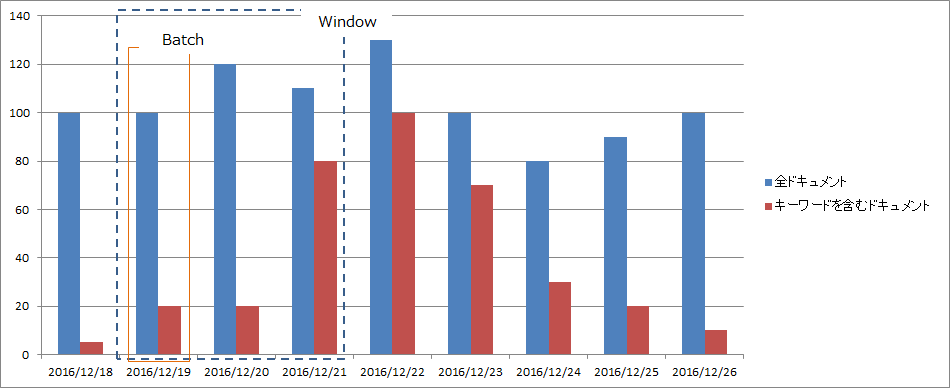
本アルゴリズムでは時系列データを計算するためにWindowという形で切り出します(上図の青点線枠)。このWindowの期間内で登録された全ドキュメント数を$d$とし、キーワードを含むドキュメント(関連ドキュメントと呼称)数を$r$とすると、このWindow内では平均として確率$p_{0}$で関連ドキュメントが発生します。
p_{0} = r/d
この$P_{0}$より高い確率で関連ドキュメントが発生するときは関連文書が局所的に増加していることを意味し、それをバースト状態にあるとします。本アルゴリズムでは$p_{0}$に基づいてバースト状態の関連ドキュメントの発生確率$p_{1}$を以下のように定義します。
p_{1} = p_{0} \times s
$s$はスケーリングパラメータと呼び、$p_{0} < p_{1} < 1.0$となるように任意の値を指定します。
これらの$P_{0},P_{1}$を使ってバーストスコア(burst_weight)を以下のように計算します。
バーストスコアの計算はWindowを分割した領域であるBatch毎に計算します。Windowが2016/12/19~21までの3日間を含んでいるので、1日=1Batchとして3Batchに分割すると想定しています。Batchごとの全ドキュメントと関連ドキュメントをそれぞれ$d_{t}, r_{t}$とします。
burst\_weight = \sigma(0,d_{t},r_{t}) - \sigma(1,d_{t},r_{t}) - \gamma \times ln(w) \\
\sigma (i,d_{t},r_{t}) = -1 \times ln{\left( \begin{array}{c} d_{t} \\ r_{t} \end{array} \right) p_{i}^{r_{t}} (1-p_{i})^{d_{t}-r_{t}}}
$\sigma$はBatchの関連ドキュメントの発生確率が定常状態とバースト状態のどちらに近いかをコストという形で示すものです。第一項($\sigma(0,d_{t},r_{t})$)が定常状態に対するコスト、第二項($\sigma(1,d_{t},r_{t})$)がバースト状態に対するコストを示します。より近い状態のコストは小さくなります。そのため、バースト状態に近い場合は$第一項 > 第二項$となるためburst_weightは0より大きくなります。
なお、第三項の$\gamma \times ln(w)$はノイズ除去のための補正項で$w$はWindow内のBatch数になります。$\gamma$を大きくすること(あるいはWindowを構成するBatch数を大きくすること)でバースト状態を検知する感度を低くし、ドキュメント数の大きな変化のみを抽出することができるようになります。
jubaburstの使い方
それでは実際にjubaburstを使ってみたいと思います。
他のjubatusの機能と同様にjubaburstでもまずはjubatusサーバを起動します。
$ jubaburst -f config.json
設定ファイルでは以下のようなパラメータを設定します。
{
"parameter" : {
"window_batch_size": 5,
"batch_interval": 10,
"max_reuse_batch_num": 2,
"costcut_threshold": -1,
"result_window_rotate_size": 5
},
"method" : "burst"
}
- window_batch_size Windowを構成するbatch数
- batch_interval batchに含む時間
- 後述しますが、ドキュメントを追加する際に時間をdouble型の数値で指定します
- max_reuse_batch_num 再計算を省略するバッチ数
- jubaburstではオンライン処理を行うためにWindowを移動させながら計算を行っていきます。個々のWindowは完全に独立している訳ではなく半数のbatchは重複するようにWindowを少しずつずらしていきます。重複したbatchについてもburst_weightを再計算しますが、本パラメータを設定することで前回の計算結果を再利用し計算量を削減します.重複するbatchはWindowに含まれるbatchの(最大でも)半分であるため,本パラメータもそれ以上の値を指定しても意味はありません(動作に支障はありません)
- costcut_threshold 計算量を削減するための閾値を定めます
- ここでは無効化(0以下の値を設定)しています
- result_window_rotate_size 現在計算中のWindowを含めて、メモリに保持するWindow数を決定します
サーバを起動したら、ドキュメントの追加とburst_weightを計算します。
jubatus-exampleを参考に手順を説明します。
なお、jubatus.burst.clientによるclientインスタンスを作成するまでは省略しています。
# あらかじめキーワードを登録しておく
client.add_keyword(KeywordWithParams("バルス", 1.001, 0.1))
add_keywordメソッドによりバースト検知を行うキーワードを登録します。同時にスケーリングパラメータ$s$と$\gamma$を指定します。上記の例ではキーワードを「バルス」、スケーリングパラメータと$\gamma$をそれぞれ$1.001, 0.1$と指定しています。
# それっぽいデータを生成する関数
def add(pos, burst_count, nonburst_count):
pos = float(pos)
client.add_documents(
[Document(pos, "バルス!!")] * burst_count +
[Document(pos, "ユバタス")] * nonburst_count
)
add_documentsメソッドによりドキュメントを追加します。このとき同時にdouble型で数値を指定します。これは時系列的な位置を表します。
# 適当な時系列データを生成して投入
# Time Burst Non-Burst
add( 1, 5, 30)
add( 11, 15, 50)
add( 21, 500, 10)
add( 31, 2000, 10)
add( 41, 22222, 40) # バルスの高まり
add( 51, 10, 10)
add( 61, 5, 25)
# バースト検知の結果を表示
for r in client.get_result("バルス").batches:
print(r)
get_resultメソッドにより、Windowに属する全てのbatchのburst_weightを取得することができます。
各メソッドの詳細は公式サイトの解説をご参照ください。
パラメータの調整方法について
jubaburstのパラメータ調整ではいくつか注意することがあります。
スケーリングパラメータについて
スケーリングパラメータ$s$を使ってバースト状態確率$p_{1}$を定めます。このとき$p_{1} < 1$となるように$s$を定める必要があります。$p_{1}$が1を超えるとburst_weightが計算不能になります(burst_weightはinfとなり値に意味がなくなります)。
また、$p_{1}$が大きくなるほど(1に近づくほど)、関連ドキュメント数の発生確率が大きくないとバースト状態とみなされないようになります。このためバーストの初期段階を見逃す可能性があります。一方で、スケーリングパラメータを小さくするとコスト$\sigma$の値が小さくなり、burst_weightの計算式の第三項($γ×ln(w)γ×ln(w)$)の補正により、特に$\gamma$を大きくしていると、burst_weightが0以下になり、やはりバースト状態を見逃す可能性があります。
スケーリングパラメータはキーワード指定時に指定する必要がありその後随意に変更することができません。そのため事前に関連ドキュメントの最大数を見積り、上記を考慮しつつ慎重にスケーリングパラメータ$s$を決める必要があります。
この調整は試行錯誤が必要です。初期の値としてはスケーリングパラメータ、$\gamma$共に小さい値から試すのがよいでしょう
Window_batch_size
バースト状態確率を計算する基礎となる$d,r$はWindowごとに計算します。そのため以下の図のようにバースト状態にある期間よりもWindowのサイズが小さいと、バースト期間中は$r$が大きくなるため定常状態確率$p_{0}=r/d$が1に近くなるため、例えスケーリングパラメータが小さくてもバースト状態確率$p_{1}$が1を超えburst_weightが計算不能になります。
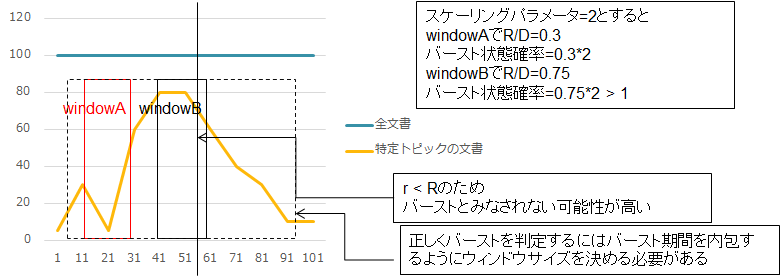
これを防ぐために上図のようにバースト期間を内包するようにWindow_batch_sizeを決定する必要があります。
Window_batch_sizeはjubatusサーバ起動時に設定ファイルにて指定します。このため、jubaburst動作時に変更することは困難です。測定期間などを考慮してある程度余裕のあるWindow_batch_sizeを決める必要があります。
ただし、ここで検出できなくなるのはバースト状態の頂点に達して関連ドキュメント数の変化がなくなったときであり、バースト初期状態の関連ドキュメント数の変化が激しいときではありません。バーストの初期状態を検知すると割り切った場合にはWindow_batch_sizeはちいさい方がよいでしょうk。
参考までに、window_batch_sizeを変化させたときのburst_weightの値を調査しました。
数では$r/d$の最大値が$0.6$となるようにドキュメントを生成しています。またスケーリングパラメータは$1.2$です。
window_batch_size以外の設定値は先ほどサンプルとして掲示したconfig.jsonの値を利用しています。
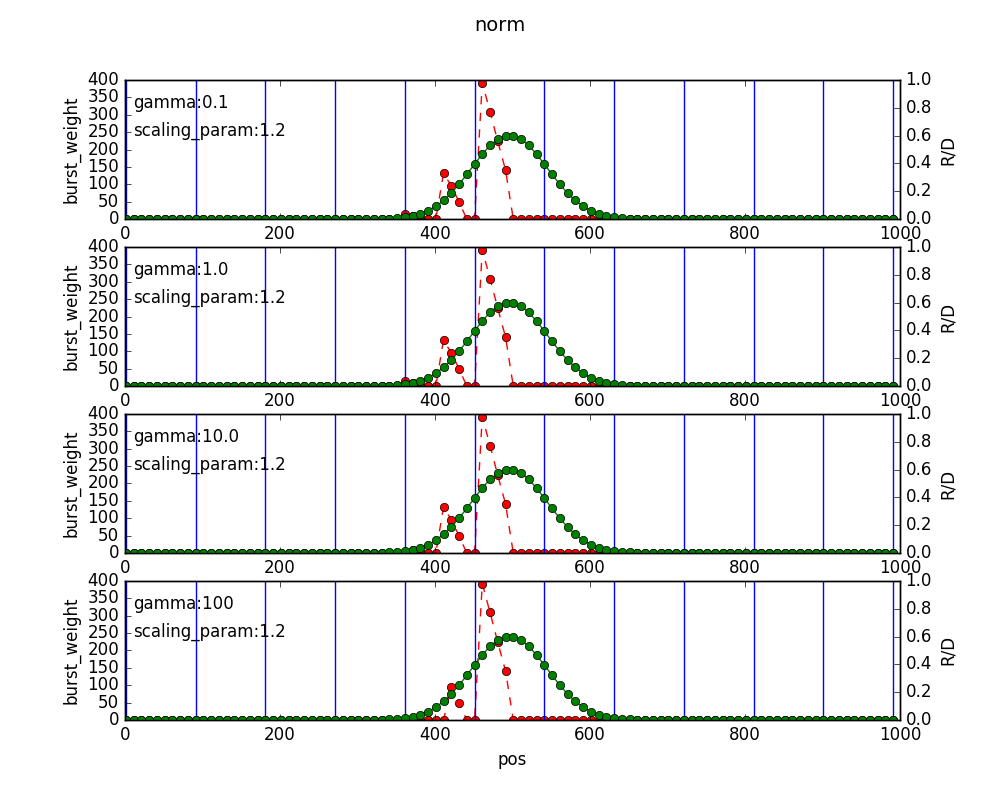
まずはwindow_batch_size=9のときのburst_weightの値です。青色の縦線がWindowを表しています. グラフが4つあるのは$\gamma$の値を変化させているからです。緑線は$r/d$の値、赤線がburst_weightの値になります。
次にwindow_batch_size=3のときのburst_weightの値です。
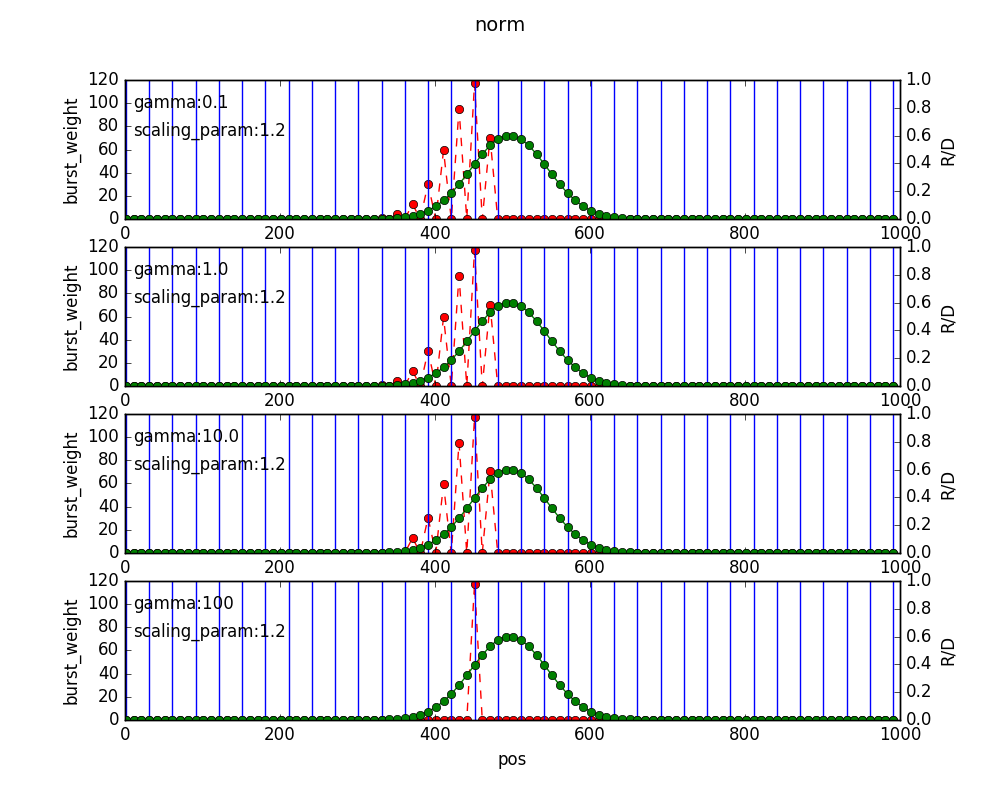
burst_weight(左軸)のスケールが違うことにご注意ください。window_batch_size=9のときの方が、3のときよりもburst期間の最後までburst_weightを出力することができていることが分かります。一方で3の時の方がより早くバースト状態を検知できていることが分かります。
window_batch_sizeが小さくなるとburst_weightの絶対値は小さくなります.このため,$\gamma$の影響が大きい(小さいburst_weightの変動が除去される)ことが分かります.
最後に
jubaburstはパラメータ調整も難しくJubatusの中でもなかなか使いこなすのが難しい機能の一つです。この記事を作成するにあたって調査していく中でいろいろな改善点が分かりましたので今後より利用しやすくするために活動を続けていきたいと思います。
参考資料
-
http://tech.albert2005.co.jp/391/
- バースト検知アルゴリズムについてより分かりやすく説明いただいています。ぜひご参照ください。
-
http://www.slideshare.net/JubatusOfficial/ss-68850498
- Jubatusハッカソンにおいてjubaburstを使って今年の漢字を予測したチームの発表資料です。いろいろと苦労してjubaburstをお使いいただきました。このとき予測した「選」は2016年度の今年の漢字候補の第2位でした。