本文書について
タイトルは少し盛りました。
手法上、はてなブックマークでコメントされている記事がターゲットとなります。
本文書では、COTOHA APIの感情分析機能を使って、WEB上の任意の記事からそれを読んだ読者の感情を推定する「読者の感情推定器」について述べる。
読者の感情推定器
背景
ニュースサイトやブログサイト上の記事を閲覧する際、情報自体はもちろん重要だが同時に「他の人はこの記事を読んでどう思っているのか」も参考になることが多い。
ある記事を読む前/読んだ後に、「この記事に対して世間は好意的」とか「この記事を読むと怒りを感じられる」とか、読者の感情がひと目で分かると情報収集が捗ると考え、「読者の感情推定器」を試作した次第である。
概要
一般的に、WEB上の記事から直接読者の感情を推定することは容易ではない。
読者は読んだ記事内容に加えて、それまでの経験や世論等の背景情報も含めて何らかの感情を持つものであり、著者が読者に想起させたい感情を意識していたとしても、記事から直接的に読者の感情を推定することは難しい。

一方で、より直接的に読者が感情を表出する場が存在する。記事の「感想欄」や「SNS」である。

感情を表現しているテキストからその感情を推定することは比較的容易と考えられる。
感情推定の方法はいくつか出回っているが、今回は最近リリースされたNTTの感情分析APIを利用してみる。
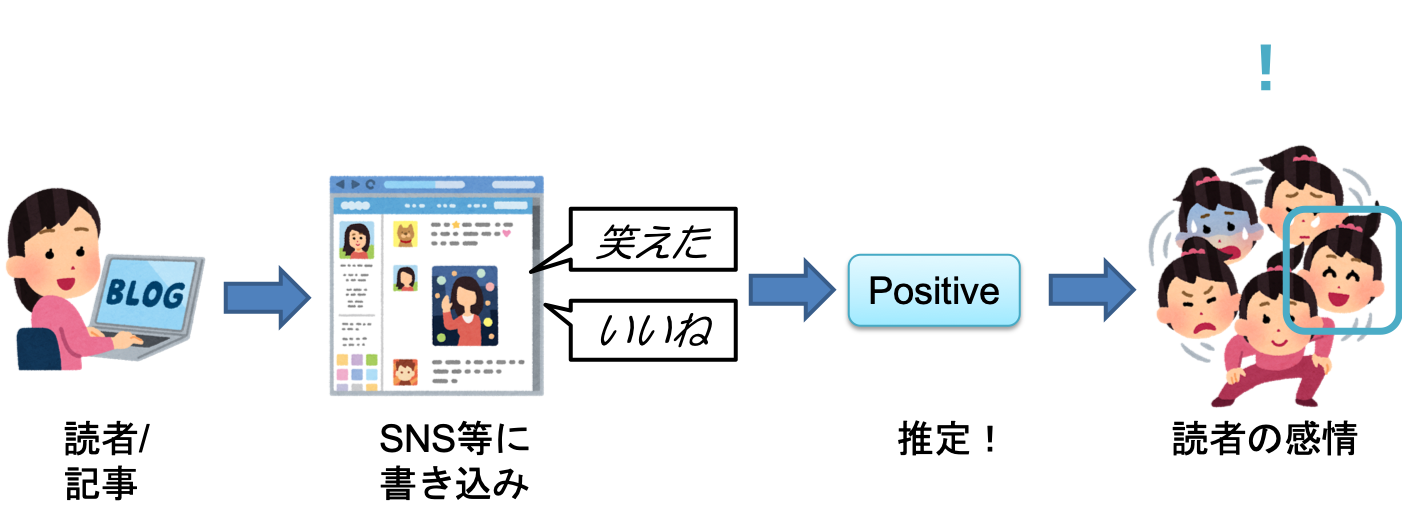
本文書では、様々なWEB上の記事が登録されコメントされるはてなブックマークのコメントに対して、COTOHA APIの感情分析機能を使うことで、任意の記事に対する読者の感情を推定する一手法を紹介する。
動作環境
python3.6.2
読者のコメントを取得
(参考)はてなブックマークエントリー情報取得API
hatenaの特定のURLに、任意のURLをGETリクエストで送信するだけで、簡単に情報を取得できる。
HATENA_BOOKMARK_URL = 'http://b.hatena.ne.jp/entry/jsonlite/'
def get_hatena_comments_from_url(url):
comments = list()
params = {'url' : url}
res = requests.get(HATENA_BOOKMARK_URL,params=params)
res = res.json()
self.title = res['title']
for r in res['bookmarks']:
if r['comment']:
comments.append(r['comment'])
return comments
テキストの感情を推定
(参考)感情分析API
テキストを入力すると、そのテキストの書き手の感情(ネガティブ・ポジティブ)を判定する。
感情の精度は良い印象。特にNeutralの判定が適切と感じた。感情的なテキストとそうでないテキストが混じっている場合の解析に適しているか。
ACCESS_TOKEN = 'XXX'
def sentiment(sentence):
headers = {'Content-Type': 'application/json',
'charset': 'UTF-8',
'Authorization': 'Bearer '+ACCESS_TOKEN}
data = {'sentence':sentence,}
data= json.dumps(data)
response = requests.post(API_BASE_URL+'v1/sentiment', headers=headers, data=data)
response = json.loads(response.text)
if response['status'] == 99998:
ACCESS_TOKEN = get_access_token()
with open('ACCESS_TOKEN.pickle', mode='wb') as f:
pickle.dump(ACCESS_TOKEN, f)
return sentiment(sentence)
return response
例:「これはアメリカの調査チームに心から感謝したい 」
{
"result": {
"sentiment": "Positive",
"score": 0.6469756927172071,
"emotional_phrase": [
{
"form": "感謝したい",
"emotion": "P"
}
]
},
"status": 0,
"message": "OK"
}
スクリプト全体
クリックして開いてください
# -*- coding: utf-8 -*-
import os
import json
import requests
import pickle
import random
CLIENT_ID = 'XXX'
CLIENT_SECRET = 'XXX'
API_BASE_URL = 'https://api.ce-cotoha.com/api/dev/nlp/'
ACCESS_TOKEN_PUBLISH_URL = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
HATENA_BOOKMARK_URL = 'http://b.hatena.ne.jp/entry/jsonlite/'
def get_access_token():
headers = {'Content-Type': 'application/json',
'charset': 'UTF-8',}
data = {'grantType':'client_credentials',
'clientId':CLIENT_ID,
'clientSecret':CLIENT_SECRET}
data = json.dumps(data)
response = requests.post(ACCESS_TOKEN_PUBLISH_URL, headers=headers, data=data)
response = json.loads(response.text)
return response['access_token']
if not os.path.isfile('./ACCESS_TOKEN.pickle'):
ACCESS_TOKEN = get_access_token()
with open('ACCESS_TOKEN.pickle', mode='wb') as f:
pickle.dump(ACCESS_TOKEN, f)
with open('ACCESS_TOKEN.pickle', mode='rb') as f:
ACCESS_TOKEN = pickle.load(f)
def sentiment(sentence):
global ACCESS_TOKEN
headers = {'Content-Type': 'application/json',
'charset': 'UTF-8',
'Authorization': 'Bearer '+ACCESS_TOKEN}
data = {'sentence':sentence,}
data= json.dumps(data)
response = requests.post(API_BASE_URL+'v1/sentiment', headers=headers, data=data)
response = json.loads(response.text)
if response['status'] == 99998:
ACCESS_TOKEN = get_access_token()
with open('ACCESS_TOKEN.pickle', mode='wb') as f:
pickle.dump(ACCESS_TOKEN, f)
return sentiment(sentence)
return response['result']
class SentimentOfArticle:
def __init__(self,url):
self.sent = None
self.phrases = list()
self.url = url
self.title = None
self.API_RESPONSE = 10
def _get_hatena_comments_from_url(self,url):
comments = list()
params = {'url' : url}
res = requests.get(HATENA_BOOKMARK_URL,params=params)
res = res.json()
self.title = res['title']
for r in res['bookmarks']:
if r['comment']:
comments.append(r['comment'])
return comments
def run(self):
comments = self._get_hatena_comments_from_url(self.url)
if len(comments)>self.API_RESPONSE:
comments = random.sample(comments, self.API_RESPONSE)
results = list()
for c in comments:
res_cotoha = sentiment(c)
results.append(res_cotoha['sentiment'])
for w in res_cotoha['emotional_phrase']:
self.phrases.append(w['form'])
num_P = results.count('Positive')
num_N = results.count('Negative')
if num_P>2 or num_N>2:
# Positive/Negative
if abs(num_P-num_N)<3 and num_P>2 and num_N>2:
self.sent = 'P/N'
# Positive
elif num_P>num_N:
self.sent = 'P'
# Negative
else:
self.sent = 'N'
else:
# Neutral
self.sent = 'neutral'
def display(self):
print('記事タイトル:\n\t',self.title)
if self.sent=='P':
print('センチメント:\n\tポジティブ😁')
elif self.sent=='N':
print('センチメント:\n\tネガティブ😥')
elif self.sent=='P/N':
print('センチメント:\n\t賛否両論!😲')
else:
print('センチメント:\n\tにゅーとらる')
if len(self.phrases)>5:
print('キーフレーズ:\n\t',','.join(random.sample(self.phrases,5)))
else:
print('キーフレーズ:\n\t',','.join(self.phrases))
print('\n')
if __name__ == "__main__":
soa = SentimentOfArticle(url='http://hoasissimo.hatenablog.com/entry/2019/02/04/000200')
soa.run()
soa.display()
使ってみる
「安倍首相、アベノミクス偽装を否定=「できるはずがない」」
記事タイトル:
安倍首相、アベノミクス偽装を否定=「できるはずがない」-衆院予算委:時事ドットコム
センチメント:
ネガティブ😥
キーフレーズ:
悪い,不祥事,良く,不可能,食い違ってる,わかっていた,めちゃくちゃ
最近話題のニュース記事を入れてみる。
ネガティブな記事とひと目で分かるだけでなく、 感情的なフレーズ も出力してみた。
どのようなコメントがされているか確認でき、記事の要約のような使い方もできそう。
「6年勤めたNTTを退職しました」
記事タイトル:
6年勤めたNTTを退職しました - Software Transactional Memo
センチメント:
賛否両論!😲
キーフレーズ:
褒める,真剣,ちょうどよい,よかった,驚いた,満足できるわけない,笑ってしまう
少し前に話題になった記事。
賛否両論の記事はキーフレーズが印象的な印象。
「もし3ヶ国語覚えられる薬があったら」
記事タイトル:
もし3ヶ国語覚えられる薬があったら
センチメント:
にゅーとらる
キーフレーズ:
上品な,広すぎだろ,何とかなる,役立ちそうな,迷う,敬われたい
「自分は〇〇語!」のような、感情的でないと判定されたコメントが多く、その結果記事も感情的でないと判定された。
感情的な記事/感情的でない記事が判定できるのは本手法の特長と考えている。
「デブでブサイクな男子大学生が女子店員よりもレディース服を売れるようになった話。」
記事タイトル:
デブでブサイクな男子大学生が女子店員よりもレディース服を売れるようになった話。|うすい よしき|note
センチメント:
ポジティブ😁
キーフレーズ:
頑張ってほしい,ほほえましい,すごい,面白かった,上手い,素直に凄い,ついでに気になってた
タイトルや本文ではネガティブな表現が多い記事だが、読者のコメントを直接推定することでポジティブな記事と推定できた、良い例。
記事自体も良かった。おすすめ。
「ペットボトルを机に置いてください。出来たらあなたは合格です。」
記事タイトル:
ペットボトルを机に置いてください。出来たらあなたは合格です。 - ペットボトルを机に置いてください。出来たらあなたは合格です。(グレブナー基底大好きbot) - カクヨム
センチメント:
ポジティブ😁
キーフレーズ:
痺れますね,面白かったです,よい,合格,よし,面白い,重要な
個人的に好きな記事。
皆面白がっている事がわかる。おすすめ。
「戦艦「比叡」見つかる 太平洋戦争中に沈没 謎の解明も…」
記事タイトル:
戦艦「比叡」見つかる 太平洋戦争中に沈没 謎の解明も… | NHKニュース
センチメント:
ポジティブ😁
キーフレーズ:
頑張って,泣ける,お気に入りだったな,意味があるなあ,沈んでる
良かった。嬉しい。(元提督感)
まとめ
実際に出力させてみると楽しかったです。(小並感)
思わず記事紹介になってしまった。
記事のコメントをまとめているだけだが、世間の本音を探っている感じがする。
大手のニュースサイトでも、感情を出力してくれると嬉しいなと思いました。