はじめに
この記事は、本番環境などでやらかしちゃった人 Advent Calendar 2023 の6日目です。
この記事で取り上げるやらかしは数年前の出来事です。
当時新卒2年目のエンジニアだった私が、ロードバランサ配下のサーバを全部切り離してサービス停止させてしまった話について、ここに供養させていただきます。
自分の失敗談なんて書きとぉないんじゃ、、というのが本音ですが、毎年やらかし系のアドベントカレンダーに勇気と希望をもらっていたので、今年は私もその一助となれたらという思いです。
やらかして死にたくなっているあなたへ。
背景
新卒で入社した会社で社内システム向けインフラの保守運用に携わっていました。
2年目となって仕事にも慣れてきた頃(フラグ)、事を起こしてしまいました。
環境
やらかしの対象となった環境はこちら。

AWS環境上で、ロードバランサとしてELBがあり、その配下にサーバ(EC2)を2台配置しているという、よくある構成です。
サーバ上ではSquidが動いており、この環境はフォワードプロキシとして機能提供しています。
社内システムを提供するサーバ側でこのロードバランサをプロキシとして設定し、インターネットに通信しにいく際にこのロードバランサを経由させる、という使われ方です。
当時の運用
保守運用作業でプロキシサーバ内の設定ファイルを書き換えたり、モジュールのバージョンアップを行ったりする際は、その変更がサービス提供に影響を与えないようにするため、変更作業前にロードバランサから片系ずつサーバの切り離しを行っていました。
※プロキシサーバ#2→プロキシサーバ#1の順に、以下作業を行う
1. ロードバランサからの切り離し
2. プロキシサーバ内の変更作業
3. ロードバランサへの再登録
そして、そのサーバの切り離し、および再登録は、AWS CLIにより行っていました。
ある日、事件は起こった
プロキシサーバの変更作業に伴い、いつものようにプロキシサーバ#2から作業を始めました。
ロードバランサからプロキシサーバ#2を切り離し、予定通り変更作業を進めていると、社内システムの担当者から 「インターネット向けの通信でエラーが出ている」 という連絡が。
あれ、プロキシサーバ#1は生きているはずなのに、、
急いでマネジメントコンソール(AWS環境の管理画面)からロードバランサを状態を確認すると、
ロードバランサの配下に、プロキシサーバが2台とも登録されていない状態となっていました。
止まらない冷や汗。
即座に作業を中断し、震える手でプロキシサーバ#2をロードバランサに再登録しました。
ロードバランサ経由のインターネット接続に問題がないことを確認し、復旧。
原因
その日はたまたま、別件でプロキシサーバに対する変更作業があり、並行して作業が進んでいました。
別作業の担当者がプロキシサーバ#1を切り離し、その後に私がプロキシサーバ#2を切り離してしまったため、結果障害。
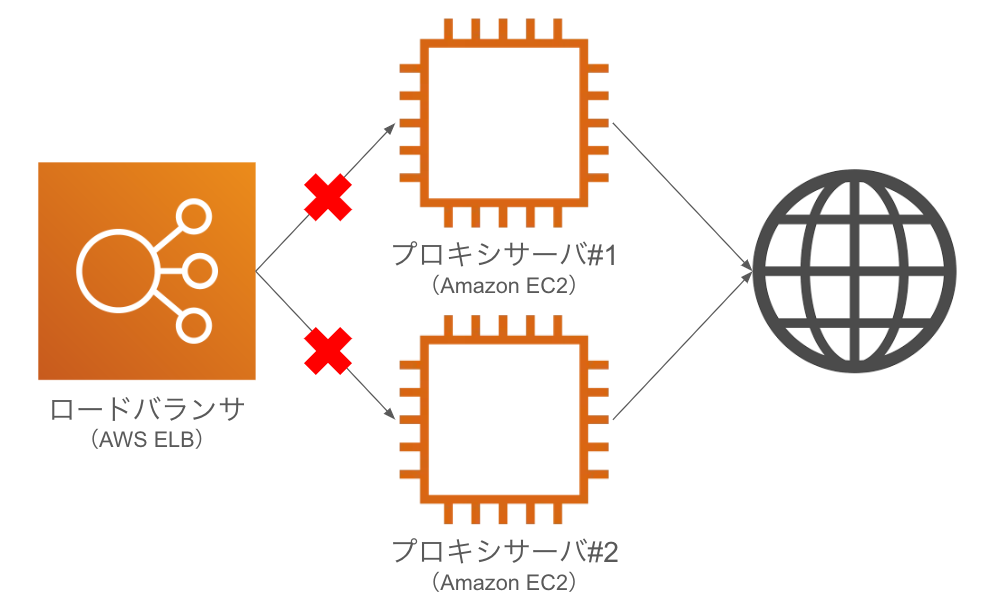
根本原因としては以下が考えられました。
- 当日実施される作業の全量、およびその内容がチーム内で共有できておらず、並行して複数の作業を行うことに問題がないかという目線で事前にチェックができていなかった
- ロードバランサからプロキシサーバを切り離す前に、両系がロードバランサに登録されていることを確認すべきだったが、その手順が作業手順書に含まれていなかった
終わりに
この件を上司に報告し、しっぽり怒られたあと、上記根本原因に対する対応に着手しました。
作業に関するチーム内コミュニケーションの円滑化、作業手順書の修正を行い、事象の再発には至っていません。
やらかしは起こさないに越したことはないですが、もしやらかしを起こしてしまった場合は、真摯に再発防止につとめ、後輩が同じ轍を踏まないようにしてあげたいなあと思います。
そのやらかしも、いつかまた思い出話する日の花になる迄。。
お付き合いいただきありがとうございました。