はじめに
本プログラムは、↓こんな引張試験の電圧の出力値のcsvを指定すれば

実行するだけで以下のようなきれいなグラフを作成できるようにすることを目的としたプログラムです。
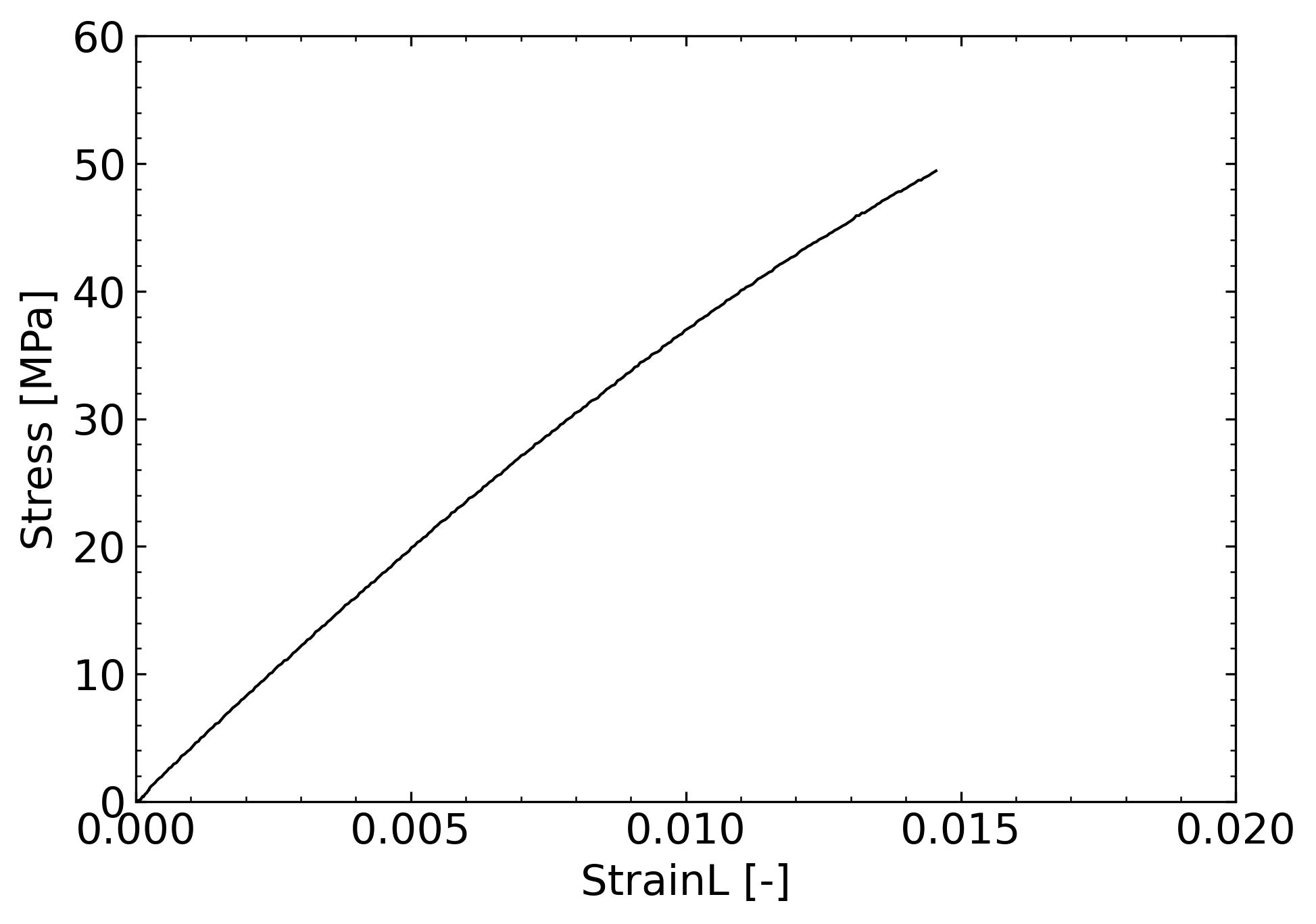


すぐに体験したい人は以下にgooglecolab上で動くように公開しました。
上がcsv1つのバージョンで、下がcsv2つでオブジェクト指向のクラスを使用して書いたプログラムです。
![]()
![]()
また、Githubにも置いておきます。
背景
材料の引張試験をするときは、ひずみゲージを取り付けて荷重やクロスヘッド変位、ひずみゲージの出力値をデータロガーで電圧としてCSV保存するのが一般的です。
しかし電圧から実際のひずみや荷重を計算し、グラフにするのはいろいろと面倒くさいです。
まずエクセル上で電圧から所定の試験条件によって決まる定数をかけて物理量に変換し、さらにgnuplotなどのソフトで見た目をきれいにしたグラフを作る必要があります。グラフ作成だけでも時間がとられるのはもったいないです。
こんなのpythonでできるじゃん、何なら弾性率とかも自動的に計算できるじゃん、と思いプログラムを作った次第です。
プログラム
入力データ
今回使用する入力csvは、キーエンスのデータロガーから得られたものになっています。
具体的には、左から
- 計測日時
- 時間
- 荷重の電圧
- クロスヘッド変位の電圧
- 表面ひずみゲージから得られた縦ひずみ
- 表面ひずみゲージから得られた横ひずみ
- 裏面ひずみゲージから得られた縦ひずみ
- 裏面ひずみゲージから得られた横ひずみ
となっています。
ライブラリ
本プログラムでは、
pandasで読み込みおよびデータ変換をし
sklearnで弾性率を計算し
matplotlibでグラフとして出力しています。
numpyは補助的に使用しています。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
試験片情報
プログラムの冒頭では、試験片の情報を入力します。
引張試験を行う際は力を断面積で割って荷重を計算するため、断面積を求めるために試験片の幅と厚みを複数回測定します。
本プログラムでは、その値をリストとして入力すれば自動で平均値を計算してくれます。
#試験片幅[mm]
width = [14.89,14.90,14.89,14.90,14.91,14.90,14.92,14.92,14.93]
print("平均幅",np.mean(width))
#試験片厚さ[mm]
thickness = [1.29,1.29,1.29,1.26,1.27,1.26,1.29,1.29,1.29]
print("平均厚さ",np.mean(thickness))
#断面積[m^2]
area = np.mean(width) * np.mean(thickness) * 10**-6
print("断面積[m^2]", area)
試験条件
次に試験条件を入力します。
具体的には、使用するひずみゲージのゲージ率、引張試験機で電圧が何N、何mmに対応すると設定したかです。
これをもとに後ほど電圧を物理量に変換していきます。
#ひずみゲージのゲージ率
gauge_rate = 2.1
#[N/V]荷重の出力電圧が何Nに対応するか
Force_scale = 50000 / 5 #50000Nが5Vに対応
#[mm/V]クロスヘッド変位の出力電圧が何mmに対応するか
cross_head_scale = 50 / 5 #50mmが5Vに対応
データの読み込み
次にデータの読み込みです。
pandasライブラリを使用してcsvファイルを読み込みます。
csvファイルには列名と電圧値以外の余計な情報も書いてあるので、headerとskipfooterを使用して必要な部分だけ取り出します。
うまく取り出せるとちゃんと数字として認識しますが、うまくいかず数字が文字列として認識されてしまうときはコメントアウトしているdf.ilocを使用して適宜変換します。
headerについては空行を無視したり色々あるので適宜数値を変えてみて列名がちゃんと指定されるようにしてください。
encodingはとりあえずshift jisとしました。
engineはskipfooterを使用するときに指定しなければいけません。
その他くわしい使い方は以下のリファレンスを読んでください。
#header=56はcsvの最初のほうの行を無視している
#skipfooterはCSVの最後のスキップする行数(適切に指定しないと数字が文字列になってしまう。 また、これを使うためにengine='python'としている)
df = pd.read_csv('test_result1.csv',encoding="shift jis",header=56, skipfooter=3, engine='python')
print(df.dtypes)
#なぜか数字が文字列になったとき用にfloatに変換
#for j in range(2,6):
#df.iloc[:,j] = df.iloc[:,j].astype(float)
データの変換
次に、電圧のデータから物理量に変換します。
応力は電圧値から[N]に変換して、力÷面積で計算します。10^6は単位を[MPa]にするため使用しています。
クロスヘッドへは電圧値から[mm]に変換していますが、正確な値ではないので使用しません。
ひずみは測定したひずみに2をかけてゲージ率で割って計算します。
今回csvにある値は、[μ strain]の単位なので、10^-6を使用して無次元に変換しています。
ゲージ率について詳しくはこちら
今回は、裏表にひずみゲージを貼り付けているため、平均値を計算します。
また、各時間でのポワソン比も、マイナス横ひずみ÷縦ひずみで計算します。
#データの変換
#応力[MPa]
df["stress"] = df["(1)HA-V01"] * Force_scale / (area * 10**6)
#クロスヘッド変位[mm]
df["cross_head_displacement"] = df["(1)HA-V02"] * cross_head_scale
#ひずみ[-]マイクロでもなく%でもなく無次元
df["strainL1"] = df["(2)ST-CH01"]*2*10**-6/gauge_rate
df["strainT1"] = df["(2)ST-CH02"]*2*10**-6/gauge_rate
df["strainL2"] = df["(2)ST-CH03"]*2*10**-6/gauge_rate
df["strainT2"] = df["(2)ST-CH04"]*2*10**-6/gauge_rate
#ひずみの裏表平均
df["strainLave"] = (df["strainL1"] + df["strainL2"])/2
df["strainTave"] = (df["strainT1"] + df["strainT2"])/2
#ポワソン比のひずみ変化
df["poissonLT"] = -1 *df["strainTave"] / df["strainLave"]
情報表示
次に、試験データから要約、最大応力、弾性率、ポアソン比を計算します。
要約
各列の統計値を出力します。
と言ってもこれは使用しないので、なんとなく入れただけです。
#最大。最小・平均などをまとめて表示
df_des = df.describe()
print(df_des)
最大応力
試験時の応力の最大値を出力します。
試験片の強度を確認することができます。
#最大応力表示
stress_max_index = df["stress"].idxmax()
print("最大応力[MPa]", stress_max_index, "番目 値", df["stress"][stress_max_index])
弾性率・ポアソン比
弾性率とポアソン比は決められたひずみの区間の値を使用して最小二乗法で求めます。
今回は、縦ひずみ0.0005と0.0025の間の区間で計算します。
まず縦ひずみ0.0005と0.0025がpnadasのデータフレームの何行目にあるのかを特定する必要があるのですが、0.0005に一番近い値のインデックスをとってくるなどとプログラムを書くと、破断後の元に戻った時のインデックスをとってしまう可能性があるので、1行目から順番に見ていって0.0005を始めて超えたインデックスをとってくるというアルゴリズムを採用しました。
0.0025についても同様です。
0.0025の場合、少し超えているじゃないか、となりますが、その1つ前まで使用することで、収まるようにしました。
その後、sklearn.linear_modelのLinearRegression()を使用して最小二乗法で傾きを求めます。
以下のサイトを参考にしました。
#弾性率計算
#ひずみ0.0005と0.0025における引張り応力を使用して弾性率を最小二乗法で回帰する
#i=1から初めて0.0005を超えたら破断後などのデータが混ざらない
for i in range(len(df)):
if df["strainLave"][i] > 0.0005:
print("i=",i,"ひずみ[-]",df["strainLave"][i])
start_reg_index = i
break
#i=1から初めて0.0025を超えたら破断後などのデータが混ざらない
for i in range(len(df)):
if df["strainLave"][i] > 0.0025:
print("i=",i, "ひずみ[-]",df["strainLave"][i])
end_reg_index = i
break
# 最小二乗法モデルで予測式を求める
#xに関しては、[[10.0], [8.0], [13.0]]というようにしないといけないのでreshape
model = LinearRegression()
model.fit(np.array(df["strainLave"][start_reg_index : end_reg_index]).reshape(-1, 1) , df["stress"][start_reg_index : end_reg_index])
#print("弾性率について、傾きが弾性率[MPa]")
#print('切片:', model.intercept_)
#print('傾き:', model.coef_[0])
print("弾性率[MPa]",model.coef_[0])
#ひずみ0.0005と0.0025における縦ひずみ横ひずみを使用してポワソン比を最小二乗法で回帰する
poisson_model = LinearRegression()
poisson_model.fit(np.array(df["strainLave"][start_reg_index : end_reg_index]).reshape(-1, 1) , df["strainTave"][start_reg_index : end_reg_index])
#print("ポワソン比について、マイナス傾きがポワソン比[-]")
#print('切片:', poisson_model.intercept_)
#print('傾き:', poisson_model.coef_[0])
print("ポワソン比[-]",-poisson_model.coef_[0])
グラフ
グラフ設定
今回グラフ作成にあたり、論文に載せれるを目標に作成しました。
その際、以下のサイトを参考に色々ミックスさせていただきました。
ありがとうございました。
#フォント設定
plt.rcParams['font.family'] = 'Times New Roman' # font familyの設定
#plt.rcParams['mathtext.fontset'] = 'stix' # math fontの設定
plt.rcParams["font.size"] = 15 # 全体のフォントサイズが変更されます。
#plt.rcParams['xtick.labelsize'] = 9 # 軸だけ変更されます。
#plt.rcParams['ytick.labelsize'] = 24 # 軸だけ変更されます
#軸設定
plt.rcParams['xtick.direction'] = 'in' # x axis in
plt.rcParams['ytick.direction'] = 'in' # y axis in
#plt.rcParams['axes.grid'] = True # make grid
#plt.rcParams['grid.linestyle']='--' #グリッドの線種
plt.rcParams["xtick.minor.visible"] = True #x軸補助目盛りの追加
plt.rcParams["ytick.minor.visible"] = True #y軸補助目盛りの追加
plt.rcParams['xtick.top'] = True #x軸の上部目盛り
plt.rcParams['ytick.right'] = True #y軸の右部目盛り
#軸大きさ
#plt.rcParams["xtick.major.width"] = 1.0 #x軸主目盛り線の線幅
#plt.rcParams["ytick.major.width"] = 1.0 #y軸主目盛り線の線幅
#plt.rcParams["xtick.minor.width"] = 1.0 #x軸補助目盛り線の線幅
#plt.rcParams["ytick.minor.width"] = 1.0 #y軸補助目盛り線の線幅
#plt.rcParams["xtick.major.size"] = 10 #x軸主目盛り線の長さ
#plt.rcParams["ytick.major.size"] = 10 #y軸主目盛り線の長さ
#plt.rcParams["xtick.minor.size"] = 5 #x軸補助目盛り線の長さ
#plt.rcParams["ytick.minor.size"] = 5 #y軸補助目盛り線の長さ
#plt.rcParams["axes.linewidth"] = 1.0 #囲みの太さ
#凡例設定
plt.rcParams["legend.fancybox"] = False # 丸角OFF
plt.rcParams["legend.framealpha"] = 1 # 透明度の指定、0で塗りつぶしなし
plt.rcParams["legend.edgecolor"] = 'black' # edgeの色を変更
plt.rcParams["legend.markerscale"] = 5 #markerサイズの倍率
上記の設定で適切に軸を設定すると、以下のようなグラフになります。
グラフテンプレ作成
グラフこの部分では、matplotlib側で軸などを自動で設定してもらってとりあえず表示させるようにしています。
↓こんな感じのがいっぱい
#グラフ描画テンプレ
strain_names = ["strainL1","strainL2","strainLave","strainT1","strainT2","strainTave"]
for col_name in strain_names:
plt.figure(figsize=(7,5),dpi=300)
plt.plot(df[col_name],df["stress"], label=col_name,c="k",lw=1)
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
plt.legend()
#plt.title("Template")
plt.show()
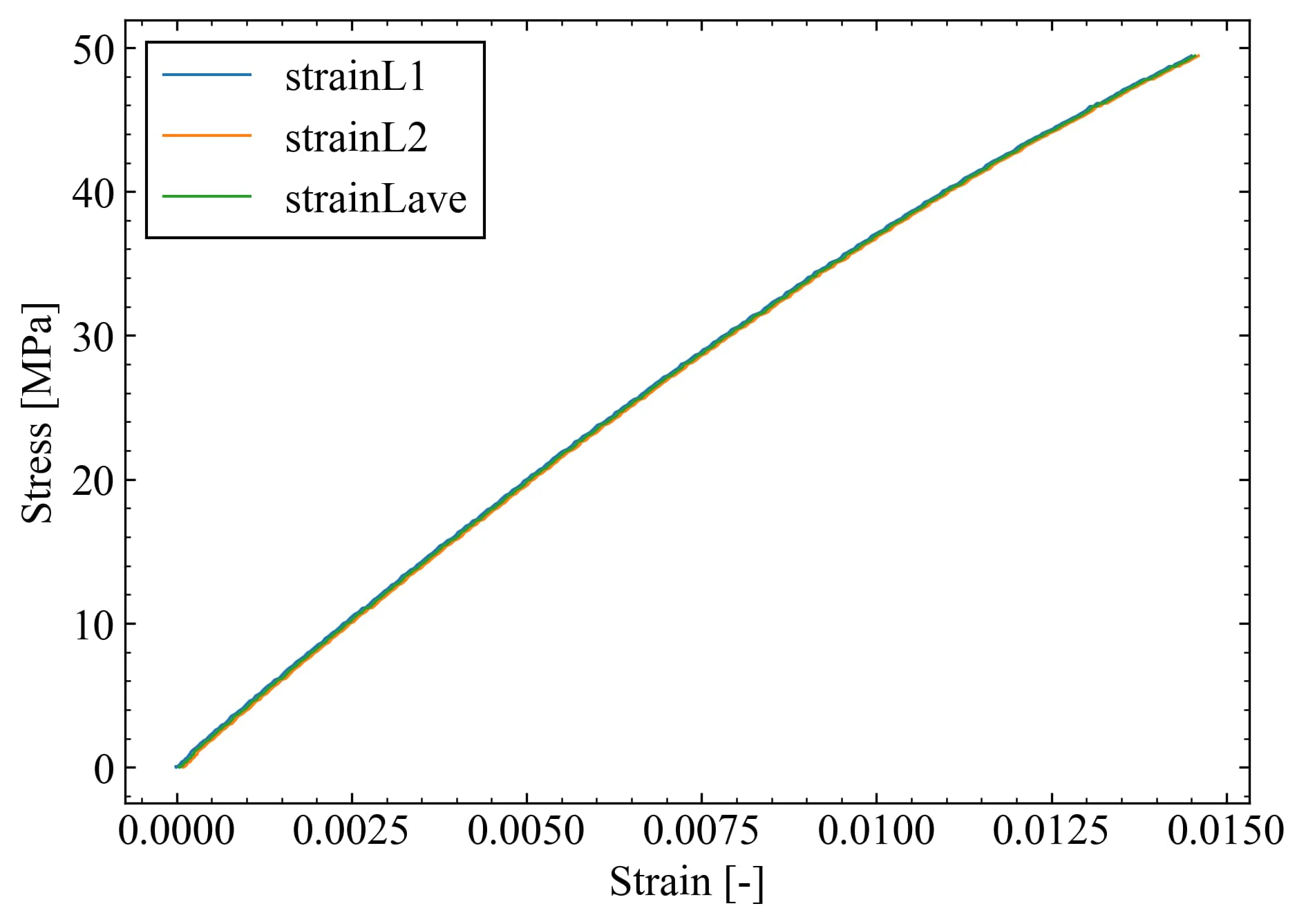
#応力ひずみ線図 L方向まとめ
plt.figure(figsize=(7,5),dpi=300)
plt.plot(df["strainL1"],df["stress"], label="strainL1",lw=1)
plt.plot(df["strainL2"],df["stress"], label="strainL2",lw=1)
plt.plot(df["strainLave"],df["stress"], label="strainLave",lw=1)
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
plt.legend()
#plt.title("Template")
plt.show()
#応力ひずみ線図 T方向まとめ
plt.figure(figsize=(7,5),dpi=300)
plt.plot(df["strainT1"],df["stress"], label="strainT1",lw=1)
plt.plot(df["strainT2"],df["stress"], label="strainT2",lw=1)
plt.plot(df["strainTave"],df["stress"], label="strainTave",lw=1)
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
plt.legend()
#plt.title("Template")
plt.show()
#ポワソン比
plt.figure(figsize=(7,5),dpi=300)
plt.plot(df["strainLave"],df["strainTave"], label="poissonLT",c="k",lw=1)
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
plt.legend()
#plt.title("Template")
plt.show()
#ポワソン比の縦ひずみ変化
plt.figure(figsize=(7,5),dpi=300)
plt.plot(df["strainLave"],df["poissonLT"], label="PoissonLT",c="k",lw=1)
plt.xlabel("StrainL [-]")
plt.ylabel("PoissonLT")
plt.legend()
#plt.title("Template")
plt.show()
弾性率・ポアソン比のグラフ
弾性率とポアソン比を最小二乗法で求めたものが、視覚的に妥当かを見るためのものです。
元のデータを黒丸でプロットし、その上から最小二乗法の結果を赤線で引いたグラフで、↓のように局所的と全体を見れます。


#弾性率のグラフ
x = np.arange(0.0005, 0.0025, 0.00001)
y = model.predict(x.reshape(-1, 1))
# 可視化 ひずみ0.0005と0.0025における
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(df["strainLave"][start_reg_index : end_reg_index] , df["stress"][start_reg_index : end_reg_index], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
#plt.title("Template")
plt.show()
# 可視化 全体
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(df["strainLave"] , df["stress"], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
#plt.title("Template")
plt.show()
#ポアソン比のグラフ
x = np.arange(0.0005, 0.0025, 0.00001)
y = poisson_model.predict(x.reshape(-1, 1))
# 可視化 ひずみ0.0005と0.0025における
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(df["strainLave"][start_reg_index : end_reg_index] , df["strainTave"][start_reg_index : end_reg_index], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
#plt.title("Template")
plt.show()
# 可視化 全体
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(df["strainLave"] , df["strainTave"], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
#plt.title("Template")
plt.show()
きれいなグラフ
最後に、論文用などのために細かく軸などを設定したグラフです。
範囲、軸指定、色指定などをしています。
特徴としては、
- グラフのはじにちゃんと軸の数値が来ている
- 右上に適度なスペースがある
- 軸ラベルがしっかりとある
などですが、まだまだ素人ですので、見落としているところがあるかもしれません。

設定は調べれば山ほど解説サイトが出てくるのでここでは触れません。
ただし、matplotlibにはオブジェクト指向の書き方とmatplotlib独自の書き方の2種類があり、今回はmatplotlib独自の書き方を採用していることに注意してください。
オブジェクト指向の書き方では一つの画像に複数のグラフを入れたりすることができます。
#応力ひずみ線図 L方向
plt.figure(figsize=(7,5),dpi=300)
plt.plot(df["strainLave"],df["stress"], label="strainLave",lw=1,c="k")
plt.xlabel("StrainL [-]")
plt.ylabel("Stress [MPa]")
#軸の範囲
plt.xlim(0,0.020)
plt.ylim(0, 60)
#軸の指定
plt.xticks(np.arange(0, 0.021, 0.005))
plt.yticks(np.arange(0, 61, 10))
#plt.legend()
plt.savefig("引張L.png", format="png", dpi=300,transparent=True)
plt.show()
#応力ひずみ線図 T方向
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(df["strainTave"],df["stress"], label="strainTave",s=1,c="k")
plt.xlabel("StrainT [-]")
plt.ylabel("Stress [MPa]")
#軸の範囲
plt.xlim(-0.005,0)
plt.ylim(0, 60)
#軸の指定
#plt.xticks(np.arange(0, 0.016, 0.005))
plt.yticks(np.arange(0, 61, 10))
#plt.legend()
plt.savefig("引張T.png", format="png", dpi=300,transparent=True)
plt.show()
#ポワソン比
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(df["strainLave"],df["strainTave"], label="poisson",s=1,c="k")
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
#軸の範囲
plt.xlim(0,0.020)
plt.ylim(-0.005,0)
#軸の指定
plt.xticks(np.arange(0, 0.021, 0.005))
plt.yticks(np.arange(-0.005, 0.001, 0.001))
#plt.legend()
#見切れるから対策
plt.tight_layout()
plt.savefig("引張P.png", format="png",transparent=True)
plt.show()
オブジェクト指向のプログラム
以上がcsvファイルからグラフ作成までを自動化したプログラムでした。
しかしここで問題が出てきます。
複数ファイルを入力して重ねてグラフ書きたいときどうするのです。
つまり↓これを作りたいときです。
最初私は上記のプログラムをコピペして、変数名の後ろに2などと付けて無理やり作りましたが、大変で汎用性がありませんでした。
そして、ここで人生初めて、オブジェクト指向の必要性について実感したのです。
オブジェクト指向のクラスを使用してプログラムを書き、各入力ごとにインスタンスを作成すればいいのでは、と。
結果がこちらです。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
class TestObject:
def __init__(self, csv_dir):
self.csv_dir = csv_dir
def set_specimen(self, widths, thicknesses):
#試験片幅[mm]
self.width = np.mean(widths)
print("平均幅[mm]", self.width)
#試験片厚さ[mm]
self.thickness = np.mean(thicknesses)
print("平均厚さ[mm]",self.thickness)
#断面積[m^2]
self.area = self.width * self.thickness * 10**-6
print("断面積[m^2]", self.area)
def set_test_condition(self, gauge_rate, Force_scale, cross_head_scale):
#ひずみゲージのゲージ率
self.gauge_rate = gauge_rate
#[N/V]荷重の出力電圧が何Nに対応するか
self.Force_scale = Force_scale
#[mm/V]クロスヘッド変位の出力電圧が何mmに対応するか
self.cross_head_scale = cross_head_scale
def data2data(self):
#データの読み込み
#header=56はcsvの最初のほうの行を無視している
#skipfooterはCSVの最後のスキップする行数(適切に指定しないと数字が文字列になってしまう。 また、これを使うためにengine='python'としている)
self.df = pd.read_csv(self.csv_dir,encoding="shift jis",header=56, skipfooter=3, engine='python')
print(self.df.dtypes)
#なぜか数字が文字列になったとき用にfloatに変換
#for j in range(2,6):
#self.df.iloc[:,j] = self.df.iloc[:,j].astype(float)
#データの変換
#応力[MPa]
self.df["stress"] = self.df["(1)HA-V01"] * self.Force_scale / (self.area * 10**6)
#クロスヘッド変位[mm]
self.df["cross_head_displacement"] = self.df["(1)HA-V02"] * self.cross_head_scale
#ひずみ[-]マイクロでもなく%でもなく無次元
self.df["strainL1"] = self.df["(2)ST-CH01"]*2*10**-6/self.gauge_rate
self.df["strainT1"] = self.df["(2)ST-CH02"]*2*10**-6/self.gauge_rate
self.df["strainL2"] = self.df["(2)ST-CH03"]*2*10**-6/self.gauge_rate
self.df["strainT2"] = self.df["(2)ST-CH04"]*2*10**-6/self.gauge_rate
self.df["strainLave"] = (self.df["strainL1"] + self.df["strainL2"])/2
self.df["strainTave"] = (self.df["strainT1"] + self.df["strainT2"])/2
self.df["poissonLT"] = -1 *self.df["strainTave"] / self.df["strainLave"]
def get_characteristics(self):
#最大応力表示
#https://www.self-study-blog.com/dokugaku/python-pandas-dataframe-max-min-describe/
#https://www.yutaka-note.com/entry/pandas_maxmin
#最大。最小・平均などをまとめて表示
self.df_des = self.df.describe()
print(self.df_des)
self.stress_max_index = self.df["stress"].idxmax()
print("最大応力", self.stress_max_index, "番目 値[MPa]", self.df["stress"][self.stress_max_index])
#弾性率計算
#ひずみ0.0005と0.0025における引張り応力を使用して弾性率を最小二乗法で回帰する
#i=1から初めて0.0005を超えたら破断後などのデータが混ざらない
for i in range(len(self.df)):
if self.df["strainLave"][i] > 0.0005:
print("i=",i,"ひずみ[-]",self.df["strainLave"][i])
self.start_reg_index = i
break
#i=1から初めて0.0025を超えたら破断後などのデータが混ざらない
for i in range(len(self.df)):
if self.df["strainLave"][i] > 0.0025:
print("i=",i,"ひずみ[-]",self.df["strainLave"][i])
self.end_reg_index = i
break
# 最小二乗法モデルで予測式を求める
#https://qiita.com/niwasawa/items/400afeb5239e197bb53f
#https://laid-back-scientist.com/least-squares
#xに関しては、[[10.0], [8.0], [13.0]]というようにしないといけないのでreshape
self.model = LinearRegression()
self.model.fit(np.array(self.df["strainLave"][self.start_reg_index : self.end_reg_index]).reshape(-1, 1) , self.df["stress"][self.start_reg_index : self.end_reg_index])
#print("弾性率について、傾きが弾性率[MPa]")
#print('切片:', self.model.intercept_)
#print('傾き:', self.model.coef_[0])
print("弾性率[MPa]",self.model.coef_[0])
#ひずみ0.0005と0.0025における縦ひずみ横ひずみを使用してポワソン比を最小二乗法で回帰する
self.poisson_model = LinearRegression()
self.poisson_model.fit(np.array(self.df["strainLave"][self.start_reg_index : self.end_reg_index]).reshape(-1, 1) , self.df["strainTave"][self.start_reg_index : self.end_reg_index])
#print("ポワソン比について、マイナス傾きがポワソン比[-]")
#print('切片:', self.poisson_model.intercept_)
#print('傾き:', self.poisson_model.coef_[0])
print("ポワソン比[-]",-self.poisson_model.coef_[0])
def plot_tmp(self):
#グラフ描画
#https://qiita.com/MENDY/items/fe9b0c50383d8b2fd919
#https://qiita.com/Nick_utuiuc/items/9bf839f5612c54606348
#https://phst.hateblo.jp/entry/2020/02/28/000000
#https://qiita.com/M_Kumagai/items/b11de7c9d06b3c43431d
#グラフ設定
#フォント設定
plt.rcParams['font.family'] = 'Times New Roman' # font familyの設定
#plt.rcParams['mathtext.fontset'] = 'stix' # math fontの設定
plt.rcParams["font.size"] = 15 # 全体のフォントサイズが変更されます。
#plt.rcParams['xtick.labelsize'] = 9 # 軸だけ変更されます。
#plt.rcParams['ytick.labelsize'] = 24 # 軸だけ変更されます
#軸設定
plt.rcParams['xtick.direction'] = 'in' # x axis in
plt.rcParams['ytick.direction'] = 'in' # y axis in
#plt.rcParams['axes.grid'] = True # make grid
#plt.rcParams['grid.linestyle']='--' #グリッドの線種
plt.rcParams["xtick.minor.visible"] = True #x軸補助目盛りの追加
plt.rcParams["ytick.minor.visible"] = True #y軸補助目盛りの追加
plt.rcParams['xtick.top'] = True #x軸の上部目盛り
plt.rcParams['ytick.right'] = True #y軸の右部目盛り
#軸大きさ
#plt.rcParams["xtick.major.width"] = 1.0 #x軸主目盛り線の線幅
#plt.rcParams["ytick.major.width"] = 1.0 #y軸主目盛り線の線幅
#plt.rcParams["xtick.minor.width"] = 1.0 #x軸補助目盛り線の線幅
#plt.rcParams["ytick.minor.width"] = 1.0 #y軸補助目盛り線の線幅
#plt.rcParams["xtick.major.size"] = 10 #x軸主目盛り線の長さ
#plt.rcParams["ytick.major.size"] = 10 #y軸主目盛り線の長さ
#plt.rcParams["xtick.minor.size"] = 5 #x軸補助目盛り線の長さ
#plt.rcParams["ytick.minor.size"] = 5 #y軸補助目盛り線の長さ
#plt.rcParams["axes.linewidth"] = 1.0 #囲みの太さ
#凡例設定
plt.rcParams["legend.fancybox"] = False # 丸角OFF
plt.rcParams["legend.framealpha"] = 1 # 透明度の指定、0で塗りつぶしなし
plt.rcParams["legend.edgecolor"] = 'black' # edgeの色を変更
plt.rcParams["legend.markerscale"] = 5 #markerサイズの倍率
#グラフ描画テンプレ
strain_names = ["strainL1","strainL2","strainLave","strainT1","strainT2","strainTave"]
for col_name in strain_names:
plt.figure(figsize=(7,5),dpi=300)
plt.plot(self.df[col_name],self.df["stress"], label=col_name,c="k",lw=1)
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
plt.legend()
#plt.title("Template")
plt.show()
#応力ひずみ線図 L方向まとめ
plt.figure(figsize=(7,5),dpi=300)
plt.plot(self.df["strainL1"],self.df["stress"], label="strainL1",lw=1)
plt.plot(self.df["strainL2"],self.df["stress"], label="strainL2",lw=1)
plt.plot(self.df["strainLave"],self.df["stress"], label="strainLave",lw=1)
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
plt.legend()
#plt.title("Template")
plt.show()
#応力ひずみ線図 T方向まとめ
plt.figure(figsize=(7,5),dpi=300)
plt.plot(self.df["strainT1"],self.df["stress"], label="strainT1",lw=1)
plt.plot(self.df["strainT2"],self.df["stress"], label="strainT2",lw=1)
plt.plot(self.df["strainTave"],self.df["stress"], label="strainTave",lw=1)
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
plt.legend()
#plt.title("Template")
plt.show()
#ポワソン比
plt.figure(figsize=(7,5),dpi=300)
plt.plot(self.df["strainLave"],self.df["strainTave"], label="poissonLT",c="k",lw=1)
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
plt.legend()
#plt.title("Template")
plt.show()
#ポワソン比の縦ひずみ変化
plt.figure(figsize=(7,5),dpi=300)
plt.plot(self.df["strainLave"],self.df["poissonLT"], label="PoissonLT",c="k",lw=1)
plt.xlabel("StrainL [-]")
plt.ylabel("PoissonLT")
plt.legend()
#plt.title("Template")
plt.show()
#弾性率のグラフ
x = np.arange(0.0005, 0.0025, 0.00001)
y = self.model.predict(x.reshape(-1, 1))
# 可視化 ひずみ0.0005と0.0025における
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(self.df["strainLave"][self.start_reg_index : self.end_reg_index] , self.df["stress"][self.start_reg_index : self.end_reg_index], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
#plt.title("Template")
plt.show()
# 可視化 全体
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(self.df["strainLave"] , self.df["stress"], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("Strain [-]")
plt.ylabel("Stress [MPa]")
#plt.title("Template")
plt.show()
#ポアソン比のグラフ
x = np.arange(0.0005, 0.0025, 0.00001)
y = self.poisson_model.predict(x.reshape(-1, 1))
# 可視化 ひずみ0.0005と0.0025における
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(self.df["strainLave"][self.start_reg_index : self.end_reg_index] , self.df["strainTave"][self.start_reg_index : self.end_reg_index], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
#plt.title("Template")
plt.show()
# 可視化 全体
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(self.df["strainLave"] , self.df["strainTave"], s=1, c='k')
plt.plot(x, y, c='r')
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
#plt.title("Template")
plt.show()
def do_set(self):
self.data2data()
self.get_characteristics()
self.plot_tmp()
先ほどまで作っていたコードをそのままクラスにしただけです。
使い方
使い方は以下です。
TestObjectで入力データを渡しながらインスタンスを作成し、
set_specimenで試験片情報を渡し、
set_test_conditionで試験条件を渡し、
do_setで電圧から物理量への変換のdata2data、弾性率等計算のget_characteristics、テンプレートのグラフ作成のplot_tmpをまとめて行ってくれます。
Test1=TestObject('test_result1.csv')
widths1 = [14.96,14.96,14.96,14.96,15.01,14.97,14.96,14.96,14.96]
thicknesses1 = [1.35,1.33,1.33,1.31,1.30,1.31,1.30,1.31,1.31]
Test1.set_specimen(widths=widths1, thicknesses=thicknesses1)
Test1.set_test_condition(gauge_rate=2.1, Force_scale=50000/5, cross_head_scale=50/5)
Test1.do_set()
Test2=TestObject('test_result2.csv')
widths2 = [15.02,15.04,15.03,14.99,14.99,14.99,15.01,14.99,14.99]
thicknesses2 = [1.33,1.33,1.33,1.31,1.31,1.31,1.30,1.30,1.30]
Test2.set_specimen(widths=widths2, thicknesses=thicknesses2)
Test2.set_test_condition(gauge_rate=2.1, Force_scale=50000/5, cross_head_scale=50/5)
Test2.do_set()
また、グラフを重ねて表示したい際は、念のためグラフ設定を行った後、インスタンスからdfにアクセスして行います。
結果が↓です。
今回は2本しか載せていませんが、インスタンスさえ増やせば何本でも重ねて描写できますし、もちろん1本だけもできます。
#グラフ設定
#フォント設定
plt.rcParams['font.family'] = 'Times New Roman' # font familyの設定
#plt.rcParams['mathtext.fontset'] = 'stix' # math fontの設定
plt.rcParams["font.size"] = 15 # 全体のフォントサイズが変更されます。
#plt.rcParams['xtick.labelsize'] = 9 # 軸だけ変更されます。
#plt.rcParams['ytick.labelsize'] = 24 # 軸だけ変更されます
#軸設定
plt.rcParams['xtick.direction'] = 'in' # x axis in
plt.rcParams['ytick.direction'] = 'in' # y axis in
#plt.rcParams['axes.grid'] = True # make grid
#plt.rcParams['grid.linestyle']='--' #グリッドの線種
plt.rcParams["xtick.minor.visible"] = True #x軸補助目盛りの追加
plt.rcParams["ytick.minor.visible"] = True #y軸補助目盛りの追加
plt.rcParams['xtick.top'] = True #x軸の上部目盛り
plt.rcParams['ytick.right'] = True #y軸の右部目盛り
#軸大きさ
#plt.rcParams["xtick.major.width"] = 1.0 #x軸主目盛り線の線幅
#plt.rcParams["ytick.major.width"] = 1.0 #y軸主目盛り線の線幅
#plt.rcParams["xtick.minor.width"] = 1.0 #x軸補助目盛り線の線幅
#plt.rcParams["ytick.minor.width"] = 1.0 #y軸補助目盛り線の線幅
#plt.rcParams["xtick.major.size"] = 10 #x軸主目盛り線の長さ
#plt.rcParams["ytick.major.size"] = 10 #y軸主目盛り線の長さ
#plt.rcParams["xtick.minor.size"] = 5 #x軸補助目盛り線の長さ
#plt.rcParams["ytick.minor.size"] = 5 #y軸補助目盛り線の長さ
#plt.rcParams["axes.linewidth"] = 1.0 #囲みの太さ
#凡例設定
plt.rcParams["legend.fancybox"] = False # 丸角OFF
plt.rcParams["legend.framealpha"] = 1 # 透明度の指定、0で塗りつぶしなし
plt.rcParams["legend.edgecolor"] = 'black' # edgeの色を変更
plt.rcParams["legend.markerscale"] = 5 #markerサイズの倍率
#応力ひずみ線図 L方向
plt.figure(figsize=(7,5),dpi=300)
plt.plot(Test1.df["strainLave"],Test1.df["stress"], label="No. 1",lw=1)
plt.plot(Test2.df["strainLave"],Test2.df["stress"], label="No. 2",lw=1)
plt.xlabel("StrainL [-]")
plt.ylabel("Stress [MPa]")
#軸の範囲
plt.xlim(0,0.020)
plt.ylim(0, 60)
#軸の指定
plt.xticks(np.arange(0, 0.021, 0.005))
plt.yticks(np.arange(0, 61, 10))
plt.legend()
plt.savefig("引張L.png", format="png", dpi=300,transparent=True)
plt.show()
#応力ひずみ線図 T方向
plt.figure(figsize=(7,5),dpi=300)
plt.plot(Test1.df["strainTave"],Test1.df["stress"], label="No. 1",lw=1)
plt.plot(Test2.df["strainTave"],Test2.df["stress"], label="No. 2",lw=1)
plt.xlabel("StrainT [-]")
plt.ylabel("Stress [MPa]")
#軸の範囲
plt.xlim(-0.005,0)
plt.ylim(0, 60)
#軸の指定
#plt.xticks(np.arange(0, 0.016, 0.005))
plt.yticks(np.arange(0, 61, 10))
plt.legend()
plt.savefig("引張T.png", format="png", dpi=300,transparent=True)
plt.show()
#ポワソン比
plt.figure(figsize=(7,5),dpi=300)
plt.scatter(Test1.df["strainLave"],Test1.df["strainTave"], label="No. 1",s=1)
plt.scatter(Test2.df["strainLave"],Test2.df["strainTave"], label="No. 2",s=1)
plt.xlabel("StrainL [-]")
plt.ylabel("StrainT [-]")
#軸の範囲
plt.xlim(0,0.020)
plt.ylim(-0.005,0)
#軸の指定
plt.xticks(np.arange(0, 0.021, 0.005))
plt.yticks(np.arange(-0.005, 0.001, 0.001))
plt.legend()
#見切れるから対策
plt.tight_layout()
plt.savefig("引張P.png", format="png",transparent=True)
plt.show()
【20221003追加】gif作成の追加
グラフだけだと、時間変化でそれぞれのグラフがどのように動くかがわかりにくいですよね。
そこで↓のようなそれぞれが連動したgifアニメーションを作れるように機能を追加しました。
なお、クラスバージョンにしか追加しておらず、Githubのクラスのほうのプログラムのみ対応させました。
全体像
ライブラリとしては、matplotlibからFuncAnimationを使用します。
from matplotlib.animation import FuncAnimation
追加する関数はmake_plot_animationとplot_itimeの2つです。
Githubのほうではdo_setの後に追加しています。
内容としては、plot_itimeが引数iに対してi番目のフレームを描写する関数。
make_plot_animationはplot_itimeを使用してアニメーションを作成するものとなっています。
def do_set(self):
self.data2data()
self.get_characteristics()
self.plot_tmp()
def make_plot_animation(self):
self.fig, self.ax = plt.subplots(2,2, dpi=100, figsize=(21,14))
self.anim = FuncAnimation(self.fig, self.plot_itime, frames=range(0,len(self.df),10), interval=10)
self.anim.save(self.csv_dir+"_anime.gif", writer="pillow")
plt.close()
def plot_itime(self, i):
self.ax[0,0].cla()
self.ax[0,0].plot(self.df["cross_head_displacement"],self.df["stress"], label="cross_head_displacement",lw=1,c="k")
self.ax[0,0].set_xlabel("Crosshead Displacement [mm]")
self.ax[0,0].set_ylabel("Stress [MPa]")
#self.ax[0,0].legend()
self.ax[0,0].axvline(self.df["cross_head_displacement"][i], c="r")
self.ax[0,0].plot(self.df["cross_head_displacement"][i],self.df["stress"][i], c="r", marker='v')
self.ax[0,1].cla()
self.ax[0,1].plot(self.df["strainLave"],self.df["stress"], label="strainLave",lw=1,c="k")
self.ax[0,1].set_xlabel("Strain [-]")
self.ax[0,1].set_ylabel("Stress [MPa]")
#self.ax[0,1].legend()
self.ax[0,1].axvline(self.df["strainLave"][i], c="r")
self.ax[0,1].plot(self.df["strainLave"][i],self.df["stress"][i], c="r", marker='v')
self.ax[1,0].cla()
self.ax[1,0].plot(self.df["strainTave"],self.df["stress"], label="strainTave",lw=1,c="k")
self.ax[1,0].set_xlabel("Strain [-]")
self.ax[1,0].set_ylabel("Stress [MPa]")
#self.ax[1,0].legend()
self.ax[1,0].axvline(self.df["strainTave"][i], c="r")
self.ax[1,0].plot(self.df["strainTave"][i],self.df["stress"][i], c="r", marker='v')
self.ax[1,1].cla()
self.ax[1,1].plot(self.df["strainLave"],self.df["strainTave"], label="strainLave",lw=1,c="k")
self.ax[1,1].set_xlabel("StrainL [-]")
self.ax[1,1].set_ylabel("StrainT [-]")
#self.ax[1,1].legend()
self.ax[1,1].axvline(self.df["strainLave"][i], c="r")
self.ax[1,1].plot(self.df["strainLave"][i],self.df["strainTave"][i], c="r", marker='v')
詳しく解説
詳しくプログラムの内容を説明すると、
self.fig, self.ax = plt.subplots(2,2, dpi=100, figsize=(21,14))
こちらで2x2のグラフを作成します。
例えば6つのグラフを並べたかったら最初の引数を2,3などにすればいいです。
今回2x2の場所を作成したので、plot_itimeではax[0,0]~ax[1,1]でそれぞれ描写します。
self.anim = FuncAnimation(self.fig, self.plot_itime, frames=range(0,len(self.df),10), interval=10)
次にこちらですが、すべてのデータを描写するとかなりファイルサイズが大きくなり、プログラムの実行も長くなってしまうためframes=range(0,len(self.df),10)の最後の10というところで何個おきに描写するかを変化させています。大きくすればとびとびになります。
interval=10では、各フレーム間の時間をmsで指定しています。つまり今回は10msごとに描写、つまり100fpsとなります。
intervalを大きくすればかくかくの動画になります。
また、
self.ax[0,0].cla()
というのは、毎回前の描写をクリアするために使用しています。
これがないと前に描写したものの上からさらに描写するようになってしまいます。
実行方法
実行をするときは、このように行いなます。
なお、フレーム数を多くするとアニメーションを作成するのにかなり時間がかかってしまうので、デフォルトではオフにすることをお勧めします。
Test1.make_plot_animation()
Test2.make_plot_animation()
参考
まとめ
以上が今回作成したプログラムの全貌です。
これを作成することで実験後のデータ整理が格段に楽になったうえ、オブジェクト指向のありがたみを初めて知ることができるという素晴らしい経験をすることができました。
工学系の皆さん、ぜひもっとpythonを使いませんか。
また、今後3点曲げもする予定なので、そのプログラムを作成したいと思っています。