#はじめに
小説家になろうの作品の中には作品を削除してしまう投稿者も存在する。
そのためアーカイブを残しておきたいと考えたが、
Wayback Machineでは作品ページを登録できない。
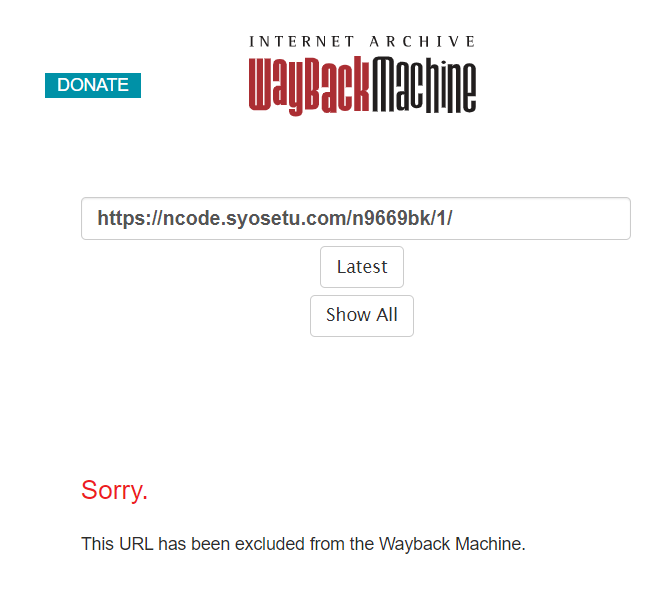
そこで代替的に縦書きPDFを使用したらうまくいったので、
日間ランキングを取得してアーカイブを登録していく方法を紹介する。
手順
1.Nコードを取得
2.pdfのぺージのURLを作成
3.Wayback Machineに登録
#1.日間ランキングの取得
https://dev.syosetu.com/man/rankapi/
小説家になろう公式がなろう小説ランキングAPIを公開しているので、これを使用した。
縦書きPDFのurlは
https://pdfnovels.net/Nコード/main.pdf
となっているので、Nコードを取得する。
参考にしたサイトは、こちら
これを改造して、
import requests
import pandas as pd
import json
import time as tm
import datetime
import gzip
def get_all_novel_info():
api_url="https://api.syosetu.com/rank/rankget/"
df = pd.DataFrame()
day = str(datetime.datetime.now().strftime("%Y%m%d")+ "-d")
payload = {'out': 'json','gzip':5, 'rtype':day }
# なろうAPIにリクエスト
cnt=0
while cnt < 5:
try:
res = requests.get(api_url, params=payload, timeout=30).content
break
except:
print("Connection Error")
cnt = cnt + 1
tm.sleep(120) #接続エラーの場合、120秒後に再リクエストする
r = gzip.decompress(res).decode("utf-8")
# pandasのデータフレームに追加する処理
df_temp = pd.read_json(r)
df = pd.concat([df, df_temp])
return df
これで日間ランキングをpandasのデータフレームで取得できた。
day = str(datetime.datetime.now().strftime("%Y%m%d")+ "-d")
なおこの部分は
ランキングタイプです。蓄積されているランキングを取得できます。
ランキングタイプの形式は日付-種類の形式です。20130501-mのように日付と種類の間に-(ハイフン)をはさみます。
日付は20130501のように西暦(4桁)、月(2桁)、日(2桁)で入力します。 種類には日間の場合はd,週間の場合はw,月間の場合はmが、四半期の場合はqが入ります。
とのこと
#2.Wayback Machineへの登録
以下のコードを使用した。
import requests
import pandas as pd
import json
import time as tm
import datetime
import gzip
from tqdm import tqdm
tqdm.pandas()
from selenium.webdriver.chrome.options import Options
#日間ランキング
def get_all_novel_info():
api_url="https://api.syosetu.com/rank/rankget/"
df = pd.DataFrame()
day = str(datetime.datetime.now().strftime("%Y%m%d")+ "-d")
payload = {'out': 'json','gzip':5, 'rtype':day }
# なろうAPIにリクエスト
cnt=0
while cnt < 5:
try:
res = requests.get(api_url, params=payload, timeout=30).content
break
except:
print("Connection Error")
cnt = cnt + 1
tm.sleep(120) #接続エラーの場合、120秒後に再リクエストする
r = gzip.decompress(res).decode("utf-8")
# pandasのデータフレームに追加する処理
df_temp = pd.read_json(r)
df = pd.concat([df, df_temp])
return df
from time import sleep
from selenium import webdriver
def url_registrater(url):
driver.get('https://web.archive.org/save')
submit_url_form = driver.find_element_by_xpath('//*[@id="web-save-url-input"]')
submit_url_form.send_keys(url)
save_button = driver.find_element_by_xpath('//*[@id="web-save-form"]/input[2]')
save_button.click()
#Wayback Machineは1分に15urlまで
sleep(4.1)
def url_registrater_request(url):
new_url = 'https://web.archive.org/save/' + url
requests.get(new_url)
#Wayback Machineは1分に15urlまで
sleep(4.1)
#ヘッドレスモードで使用したいときはこちら
#options = Options()
#options.add_argument('--headless')
#webdriver.Chrome("path", chrome_options=options)
#chromedriver.exeのパスをかく
driver = webdriver.Chrome("path")
driver.implicitly_wait(1)
daily_list = get_all_novel_info()
urllist = ["https://pdfnovels.net/{}/main.pdf".format(ncode) for ncode in daily_list["ncode"]]
#1.ログインなし
for url in tqdm(urllist):
url_registrater(url)
なお以下のサイトを参考にした。
#問題点

作品によってはpdfが作られておらず、
普通にpdfを読む際は少し待てばpdfが作られるのだが、
アーカイブを保存する際は、これが保存されてしまうことがある。
対処として、一度事前にそのページを表示しておくという方法があるが、
今回はやらない。
#その他今後考えていることなど
これはどうだろうか
ログインするとページ内のurlが一気にアーカイブできるんだったら
qiitaとかにurl貼りまくってそのページアーカイブ取らせたらいいのでは

csv高速化