はじめに
webサイトが消えてしまって、保存しておいたらよかった、ということありますよね。
pythonを使用してurlの一覧から自動でwebアーカイブサービスに登録するスクリプトを作りました。
使用するアーカイブサービスの候補
ウェブ魚拓
ウェブ魚拓
https://megalodon.jp/
これは国産のサービスでおそらく一番有名なものではないでしょうか。
しかしウェブ魚拓は1日、1IP、20アクセスまでらしいです。
ソース:高校メロン部http://shimarisu.webcrow.jp/gyotaku.html
なので却下
archive.today
海外のサイトでは。
archive.today
http://archive.vn/
というサイトも有名ではないでしょうか。
試してみましたが、待ち時間のqueueが#1500になっていました。
さらに自動化しようとしましたが、CAPTCHAが出てしまいだめでした。
また有志が作ったapiを使用してみたが、動かず。
https://github.com/pastpages/archiveis
import archiveis
archive_url = archiveis.capture("https://ncode.syosetu.com/n9669bk/1/")
print (archive_url)
429 Client Error: Too Many Requests for url: https://archive.md/
queueが長いのが原因かな
Laravelで429 (Too Many Requests)が出た時の対策
初めてなのにどうしてだろう
Wayback Machine
今回のメインであるWayback Machine
https://archive.org/web/
どうやら世界最大級のアーカイブサービスみたいですね
今回はこのサイトに登録していこうと思います。
なお同じページをアーカイブするときは最後に保存されてから30分たっていないとできません。
概要はこちら
https://warp.da.ndl.go.jp/contents/reccommend/world_wa/world_wa02.html
どうやら1分あたり15urlという制限しかないらしい。
https://gist.github.com/eggplants/414bab0230f14358642faf364bc1f7ec
やること
今回はSeleniumを使用して自動化しようと思います。
PythonでSeleniumを利用してWebサイトのログインを自動化する方法を現役エンジニアが解説【初心者向け】
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a
1.chromeが必要なので、ダウンロードしてください。
2.seleniumをダウンロードしてください
pip install selenium
seleniumとは、pythonでchromeを動かすライブラリです。
Python + Selenium で Chrome の自動操作を一通り
こちらを参考にしてください。
3.chromedriver.exeをダウンロードしてください。
chromedriver.exeはseleniumでchromeを動かすために必要なものです。
検索するとバイナリでダウンロードする方法などがあるそうですが、
今回はホームページから直接zipをダウンロードします。
https://chromedriver.chromium.org/downloads
ここからchromeのバージョンとosにあったものをダウンロード、
そして解凍
バージョンについては
https://qiita.com/iHacat/items/9c5c186f0d146bc98784
こちらを参考に
4.スクリプト
from time import sleep
from selenium import webdriver
def url_registrater(url):
driver.get('https://web.archive.org/save')
submit_url_form = driver.find_element_by_xpath('//*[@id="web-save-url-input"]')
submit_url_form.send_keys(url)
save_button = driver.find_element_by_xpath('//*[@id="web-save-form"]/input[2]')
save_button.click()
#Wayback Machineは1分に15urlまで
sleep(4.1)
def login(mail, password):
#ログイン処理
driver.get('https://archive.org/account/login')
email_input_form = driver.find_element_by_xpath('//*[@id="maincontent"]/div/div/div[2]/section[3]/form/label[1]/input')
email_input_form.send_keys(mail)
password_input_form = driver.find_element_by_xpath('/html/body/div/main/div/div/div[2]/section[3]/form/label[2]/div/input')
password_input_form.send_keys(password)
login_button = driver.find_element_by_xpath('//*[@id="maincontent"]/div/div/div[2]/section[3]/form/input[3]')
login_button.click()
sleep(1)
#Trueはチェックボックスにチェックを入れている状態
def url_registrater_logined(url, outlink=True, error_page=True, screen_shot=True, in_my_web=True, email_result=True):
driver.get('https://web.archive.org/save')
submit_url_form = driver.find_element_by_xpath('//*[@id="web-save-url-input"]')
submit_url_form.send_keys(url)
#チェックボックス
#ページ内のurlの先も保存するか
if outlink==True:
save_outlinks_button =driver.find_element_by_xpath('//*[@id="capture_outlinks"]')
save_outlinks_button.click()
#ページがerrorでも保存するか
#このチェックボックスだけ最初からチェックが入っているので挙動を逆に
if error_page==False:
error_page_button =driver.find_element_by_xpath('//*[@id="capture_all"]')
error_page_button.click()
#スクリーンショットを保存するか
if screen_shot==True:
screen_shot_button =driver.find_element_by_xpath('//*[@id="capture_screenshot"]')
screen_shot_button.click()
#ログインアカウントに追加するか
if in_my_web==True:
in_my_web_button =driver.find_element_by_xpath('//*[@id="wm-save-mywebarchive"]')
in_my_web_button.click()
#結果をメールアドレスに追加するか
if email_result==True:
email_result_button =driver.find_element_by_xpath('//*[@id="email_result"]')
email_result_button.click()
#これがないとチェックボックスを押す前にページが遷移してしまう
sleep(1)
save_button = driver.find_element_by_xpath('//*[@id="web-save-form"]/input[2]')
save_button.click()
#Wayback Machineは1分に15urlまで
sleep(3.1)
# 使い方
# chromedriver.exeのパスをかく
driver = webdriver.Chrome("path")
# ダウンロードしたいurlのリスト
urllist=["https://www.google.com/?hl=ja", "https://www.yahoo.co.jp/"]
# 1.ログインなし
for url in urllist:
url_registrater(url)
"""
# 2.ログインした状態で使いとき(できることが増える)
login('mail', 'password')
for url in urllist:
url_registrater_logined(url)
"""
5.使い方
1.ダウンロードしたchromedriver.exeのパスを書く
2.アーカイブしたいurlの一覧をリストで作る
(外部のファイルを読み込むなどはご自由に)
3.ログインしたいときはメールアドレスとパスワードを書く
なおこのサイトは10 minute mailのような捨てメールアドレスでも登録できます。
ログインするとスクリーンショットを保存したり、ページのリンク先も保存できるなどできることが増える(スクリプトのチェックボックスの説明を参照)
4.実行する
うまくいくとchromeが開いてどんどん登録していきます。
問題点
・ずっと動かしていると、sleepを挟んでいるのにたまに1分15urlに引っかかってしまう。
・一部のサイトは
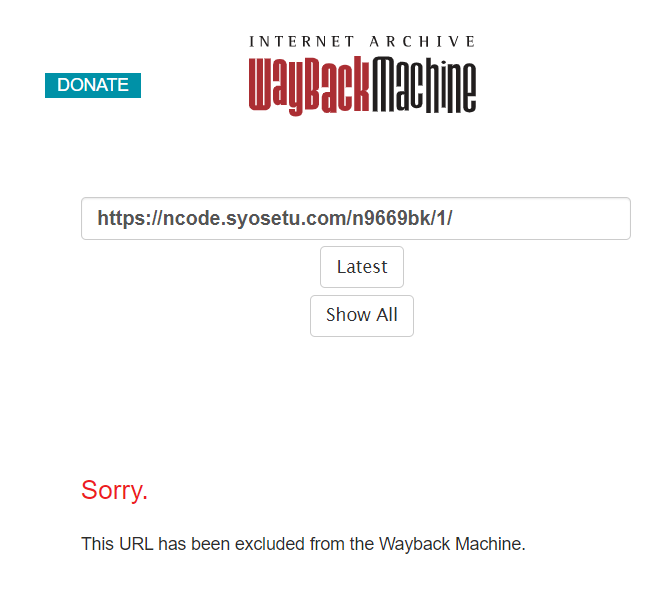
このようにダウンロードできないサイトがある。
どうも著作権の関係で昔ごたついたらしい
https://it.srad.jp/story/18/12/04/0637201/
小説家になろうの作品をどんどん登録しようと思ったのに…
まとめ
自動でwebアーカイブサービスに登録するスクリプトを作りました。
seleniumを使った強引(?)な手でしたが、
もっとrequestとか使ったスマートな方法があれば教えてください。
これでクリック1つでいろいろ登録できそうです。