何の成果も!!得られませんでした!!
結論から言います。
何の成果も!!得られませんでした!!
私は進撃の巨人が大好きで、特に現在(2022/1/30)アニメ進撃の巨人final season part2を毎回楽しみに見ています。
ちなみに漫画は最後まで読んでいます。
進撃の巨人には有名なセリフがとても多く、とても汎用性が高いです。
例
セリフが多いんだし、IMEの辞書でも作るかと思って、IME変換辞書が何なのかもわからないまま作り始めました。
結果として、タイトル通り、1500のセリフのIME変換辞書は5時間で作ることができました。
しかし、セリフのほとんどが長文で、全部タイプして変換を押して、やっと原作のセリフになるという使用になってしまいました。
文字を打っていったら、予測変換に登録したセリフが出てこればいいかなと思っていましたが、IME辞書はそういうものではありませんでした。
何はともあれ、辞書は完成したので、配布はします。shingekiIME.txtというものです。
IMEの仕組み
IME変換辞書に登録するためには、単語、よみ、品詞が必要になります。
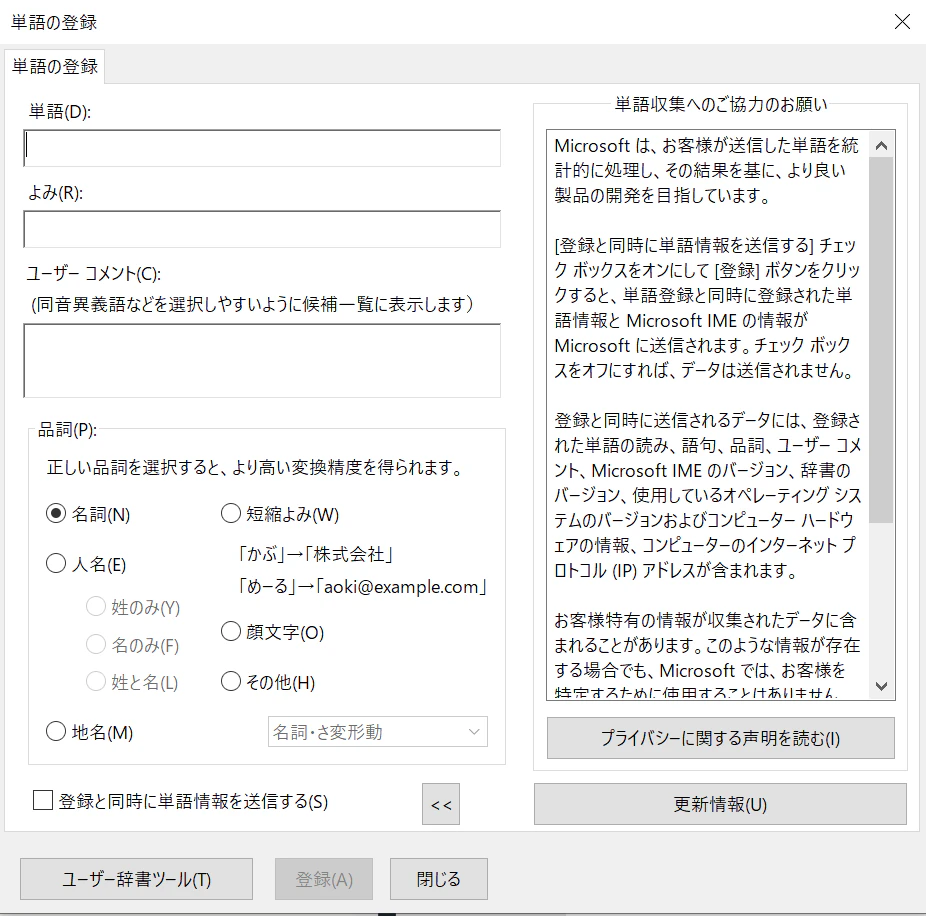
そして、タブ区切りのtxtファイルを作成することで一括で登録することができます。
配布されているIME変換辞書例
大量のセリフをどう集めるか
漫画は全34巻あるので、すべてのセリフをタイプするというのは現実的ではありません。
そこで、進撃の巨人のセリフをまとめているサイトがあったので、そこからスクレイピングすることにしました。
検索は、「進撃の巨人 セリフ 一覧」や、「進撃の巨人 名言」です。
以下は、コピペしたサイトです。
本当にありがたかったです。
ここまでこれらのサイトから、重複、空白等含めて2484語集めることができました。
ただし、問題としてアニメ化されている部分が多かったりと、偏りました。
1
コピペして手動でうまくやりました。
2
shingeki_get_words2.pyでスクレイピング
3
shingeki_get_words3.pyでスクレイピング
4
shingeki_get_words4.pyでスクレイピング
5
shingeki_get_words5.pyでスクレイピング
重複の削除
今回集めた語はgoogle spread sheetにまとめました。
まず、重複したものをgoogle spread sheetの重複を削除という機能で消しました。
その結果、2484語から1689語にまで減少しました。
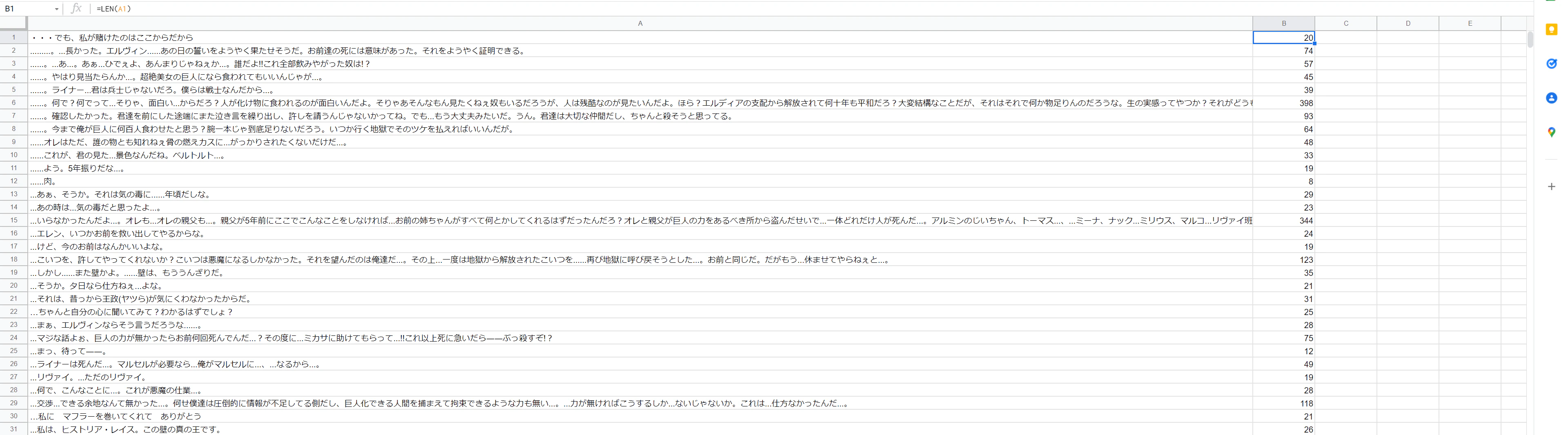
文字数で並べ替え
進撃の巨人特有でない短い単語が紛れているので、LEN()関数を使用して長さ順で並べ替えました。

道は進撃でも重要ですが、普通の単語ですね。
逆に、一番長かった語は413語でした。
お前らほど!!楽しそうに人を痛めつける奴は見たことがねぇ!!やれよ!!もっと!!お前の大好きな拷問を続けろ!!暴力が好きなんだろ!?俺もそうだ!!抵抗できない奴をいたぶると興奮する!!もっと俺で楽しんでくれ!!お前らは正義の味方なんだから遠慮する必要は無いんだぜ!?お前の言った通りだハンジ!!仕方ないんんだ!!正義のためだ!!そう思えりゃすべてが楽だ!!自分がすごい人間になれたと思えて気分が高揚するだろ!?お前ら化け物だ!!巨人なんかかわいいもんだ!!でも...俺は怖くねぇんだよ!!俺は...!俺には...王がいる...。何年も...仲間と一緒に王を守ってきたんだ...。俺は、この壁の安泰と...王を...信じてる...。俺達のやってきたことは...間違っていないと...。信じたい...。...けど...こんなに痛かったんだな...。俺を嬲り殺しにしてくれ...。それが...俺の、血に染まった...人生のすべてだ。

不適切を削除
スクレイピング時に間違って集めてしまった関係ない語などを手動で削除します。
似た表現を消す
サイトから自動で集めたので、サイトごとに表現が違ったりします。
例えば、画像のように句読点や「…」があったりなかったりしました。

そこで、difflibという単語間の類似度が分かるライブラリを使用して削除していきます。
import difflib
from difflib import SequenceMatcher
import itertools
import pandas as pd
df = pd.read_excel('進撃辞書.xlsx',header=None)
lst = list(df[0])
for i in itertools.combinations(lst, 2):
s = SequenceMatcher(None, *i)
if s.ratio() > 0.85:
print('類似度:{0}%,{1}'.format(round(s.ratio()*100,1), i))
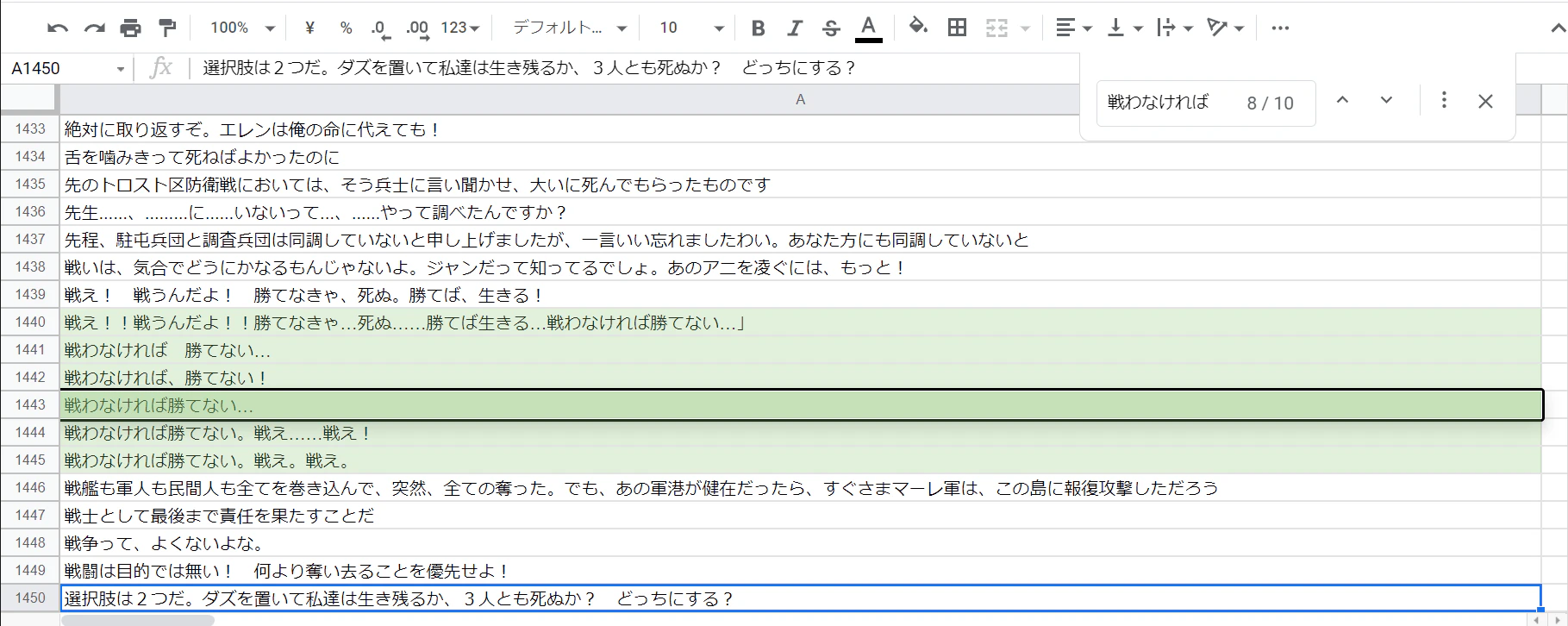
最後の0.85という部分を小さくして言って順次手動で削除していきます。
類似度:95.7%,('戦わなければ勝てない…', '戦わなければ\u3000勝てない…')
類似度:97.1%,('女神様もそんなに悪い気分じゃないね', '女神様もそんなに、悪い気分じゃないね')
類似度:97.7%,('最後まで読んで頂きありがとうございました。', '最後まで読んで頂き、ありがとうございました。')
類似度:96.3%,('何言ってんの?\u3000調査兵団は未だ負けたことしかないんだよ', '何言ってんの?調査兵団は未だ負けたことしかないんだよ?')
類似度:98.2%,('何言ってんの?\u3000調査兵団は未だ負けたことしかないんだよ', '何言ってんの?\u3000調査兵団は未だ負けたことしかないんだよ?')
類似度:75.0%,('鎧の巨人', '獣の巨人')
類似度:80.0%,('心臓を\u3000捧げよ', '心臓を捧げよ!!')
類似度:92.3%,('じゃあ帰ろう、私達の家に', 'じゃあ、帰ろう、私達の家に。')
類似度:83.3%,('俺は自由だ', '俺は、自由だ!')
類似度:76.9%,('お前ら、ありがとうな', 'ふふ...お前ら、ありがとうな。')
類似度:71.4%,('アニ、落ちて。', 'アニ……落ちて')
類似度:80.0%,('ねえ、アニ。私にも、それ', 'ねえ、アニ。私にも、それ……教えて?')

最終的に1590単語にまで減りました。
品詞を追加する
後にpandasを使用することから、1列目に今までの単語、3列目に品詞を追加します。
品詞の種類には名詞、短縮読み、人名、などありますが、今回はすべて名詞としました。

読みを追加して、変換辞書としてダウンロードする
変換辞書では、もちろんひらがなでの読みが必要です。
今回、一つずつ手動で打ち込むことはできないので、pykakasiというライブラリを使用して機械的に追加します。
今回は、googlecolabで実装し、shingekik2h.ipynbという名前にしています。
作成した進撃辞書.xlsxをアップロードしてshingekiIME.txtをダウンロードします。
この際、エンコードはUTF-16LEで、読み、語、品詞の順でタブ区切りしたtxtファイルで保存しなければいけません。
実際にIMEに登録
登録する前に、一つやらなければいけないことがあります。
メモ帳でエンコーディングをUTF-16LEを指定してtxtを開いて、保存しなおす必要があります。なぜこうなってしまったかはわかりません。
また、IME変換辞書は60文字制限があるそうです。そのため、一部は登録できません。
txtを開いて
追加しますが、一部失敗します。
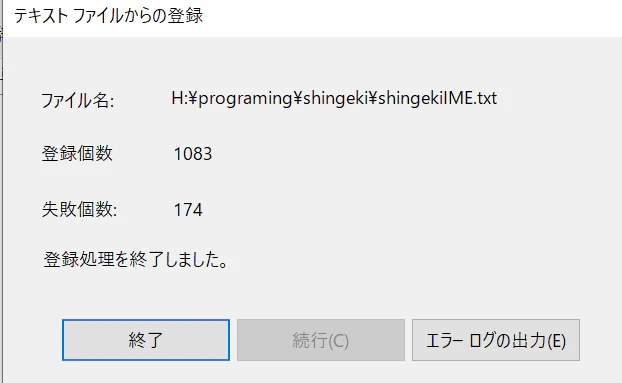
追加されたものがこちら
問題点
機械的に読みを追加したので、
使い勝手は悪い
セリフが中心で、キャラクター名、地名、固有名詞などは追加されていない
おまけ
せっかく作りましたが、あまり役に立たなかったので、入力した文字に近い進撃の巨人のセリフを出力するプログラムも作りました。
作成した進撃辞書.xlsxアップロードすると、入力した単語と近いセリフを上から3つ出力します。
今回は、difflib、python-Levenshtein、textdistanceを使用しています。
あまりうまくいきませんね

まとめ
進撃の巨人のセリフのIME変換辞書を作成しました。
とりあえず作ってみましたが、いざできたものはあまり使えない、ちゃんと目的をはっきりしてから作り始めないといけないですね。
他にもIME辞書を作ろうとする人向けに記事を残すことにしました。