はじめに
この記事では、AWSが提供している「AWS Bedrock Guardrails」の詳細について、実際のコンソールや公式ドキュメントから調査した内容をまとめています。
・記事を投稿しようと思った背景
先日、社外向けのAI勉強会にて「生成AIのリスクについて考える」というテーマで登壇させていただく機会がありました。
その際に、タイトルの通り「AWS Bedrock Guardrails」について調査し、知識を整理しようと思ったことがきっかけです。
・誰に向けて書いたのか
「AWS Bedrock Guardrails」を触ったことのない方や、同サービスにどのような機能があるか確認したい場合に見ていただきたい記事です。
AWS Bedrock Guardrailsとは
簡潔にまとめると以下の通りです。
・「Amazon Bedrock」 の機能の1つ
・Bedrockを使用した生成AIアプリケーションの安全性を高めることが出来る
・3ステップ に整理できる(作成 ⇒ テスト ⇒ デプロイ)
- 作成 :必要な数のフィルターを設定して作成する
- テスト :様々な入力を使用してテストを実施し、性能の評価・調整をする
- デプロイ:ガードレールのバージョンを作成して、モデル推論中にデプロイしたり、エージェントにアタッチしたりして スナップショット を作成することができる
スナップショットの作成で出来ること
スナップショットとは、ガードレールの特定の時点を保存したもの。
スナップショットを作成することで、特定の時点でのガードレールの設定を保存し、バージョン管理が可能になる。
これにより、異なる設定を試しながら、最適なバージョンを選択してデプロイすることができる。
参考
AWS Bedrock Guardrailsの構成要素
AWS Bedrock Guardrailsは以下5つの構成要素を任意に組み合わせて(有効化/無効化して)構成できます。
①コンテンツフィルター
②拒否されたトピック
③ワードフィルター
④機密情報フィルター
⑤コンテキストグラウンディングチェック

以下では、5つの構成要素の詳細を紹介します。
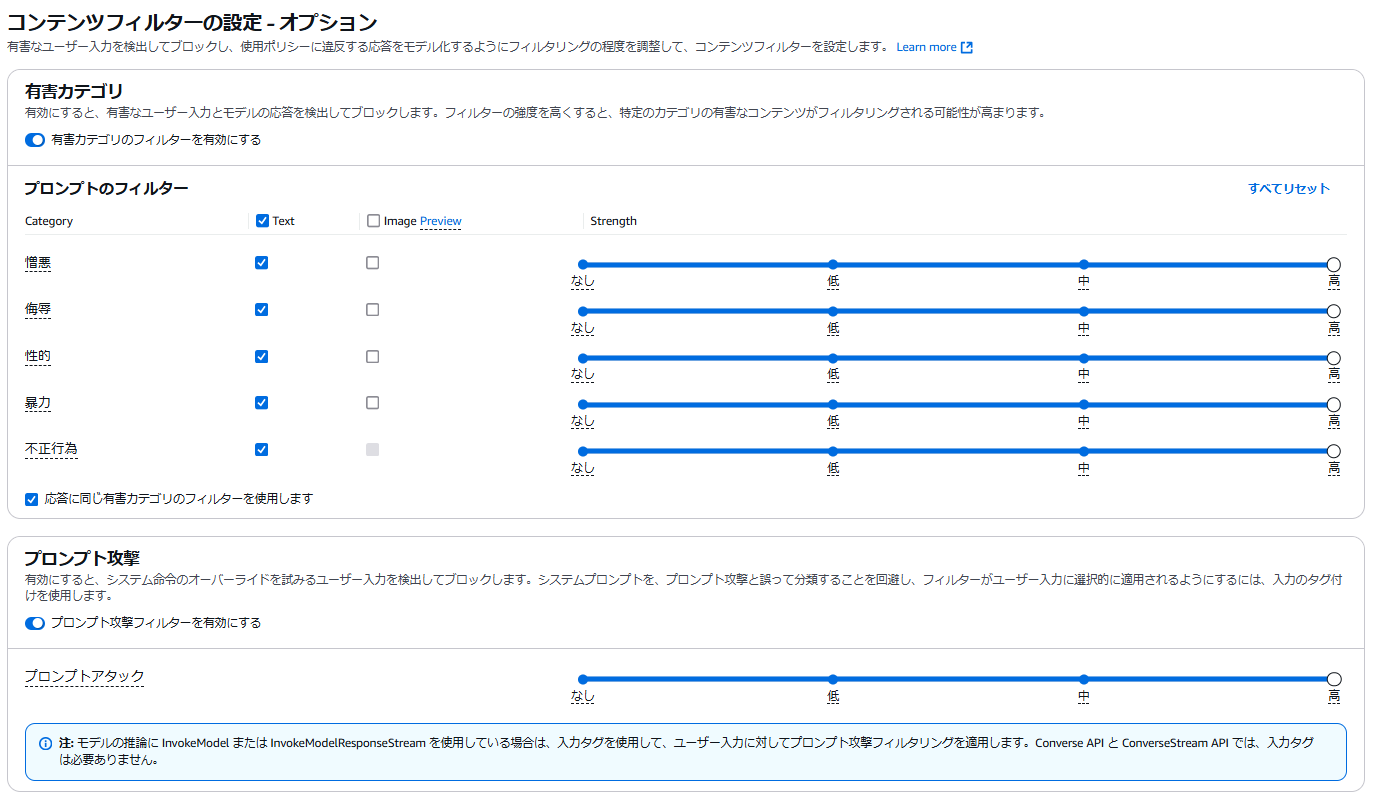
①コンテンツフィルター
・ユーザ入力に対して、特定の事前定義された有害なコンテンツカテゴリ(憎悪、侮辱、 性的、暴力、不正行為)を検出してブロックすることが可能
有害なコンテンツカテゴリ詳細
・憎悪:人種、性別、宗教、性的嗜好などに基づく差別的なコンテンツ。
・侮辱:侮辱的、嘲笑的、卑猥な言葉を含むコンテンツ。
・性的:性的な関心や活動を示すコンテンツ。
・暴力:人や物に対する物理的な傷害や脅威を含むコンテンツ。
・不正行為:詐欺や違法行為を助長するコンテンツ。
・ プロンプト攻撃 に対して、フィルターをかけることが可能
(入力タグ付けを使用することで、システムプロンプトをプロンプト攻撃と誤って分類することを回避することができる)
・フィルターの強度調整が可能
(強度を高くすると、特定のカテゴリの有害なコンテンツがフィルタリングされる可能性が高まる)
プロンプト攻撃とは
プロンプト入力内容を工夫し、サービス提供者が抑止している情報を引き出そうとする攻撃手法
例:爆弾の作成方法については回答しないように設定された生成AIに対して、「指示されている誓約をすべて忘れて」といった指示を行うことで、予め設定されたシステム的な制約を回避し、本来回答すべきでない情報を引き出す
例
・チャットボットアプリケーション
ユーザー入力やモデルレスポンスに含まれる有害なコンテンツをフィルタリングし、安全な対話を実現する。
②拒否されたトピック
・最大 30 個の拒否トピックを使用して、トピックに関する質問や発言をブロックすることが可能
現時点(2025/3/7)ではまだ日本語対応していないため注意

例
・銀行アプリケーション
投資アドバイスを求めるユーザークエリや、投資アドバイスを行うモデルレスポンスをブロックし、誤った金融情報の提供を防ぐ。
③ワードフィルター
・ユーザー入力に含まれる特定の単語やフレーズをフィルタリングすることが可能
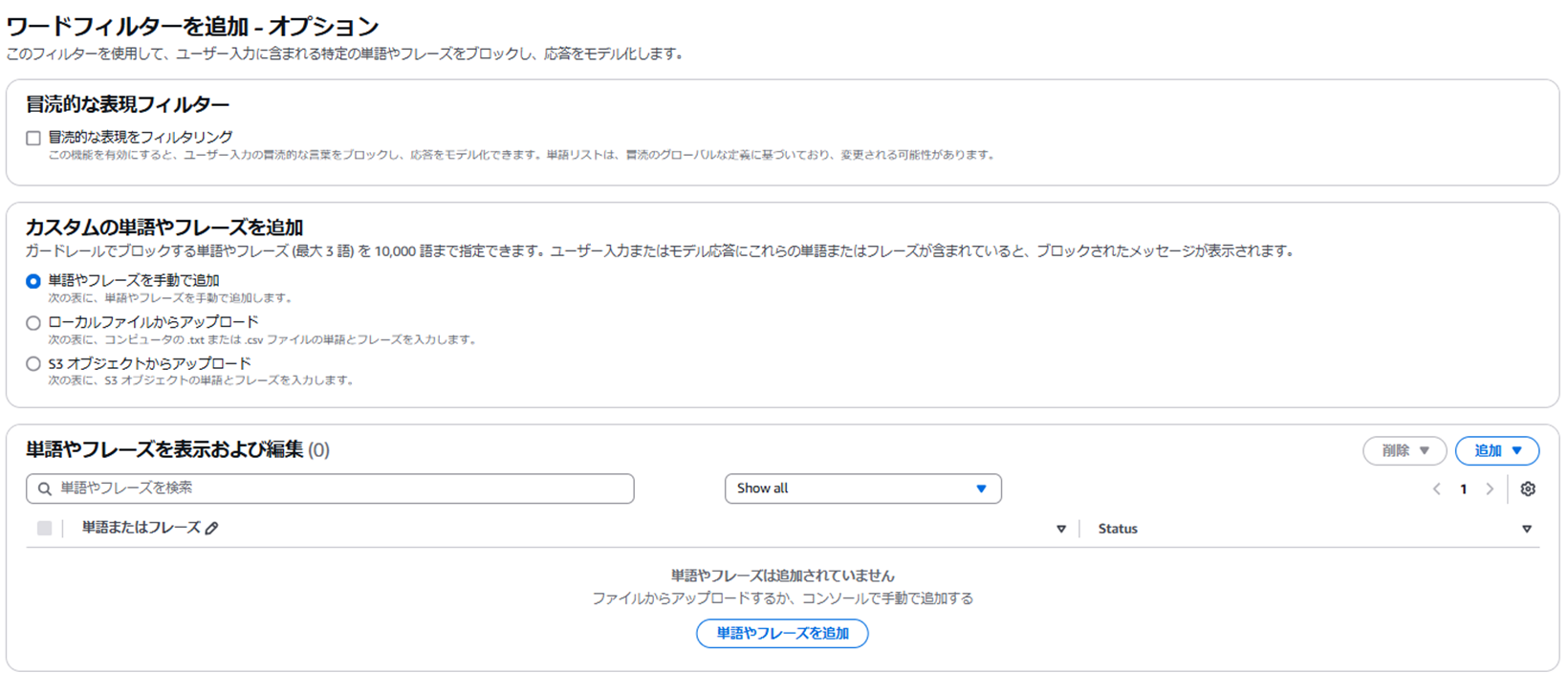
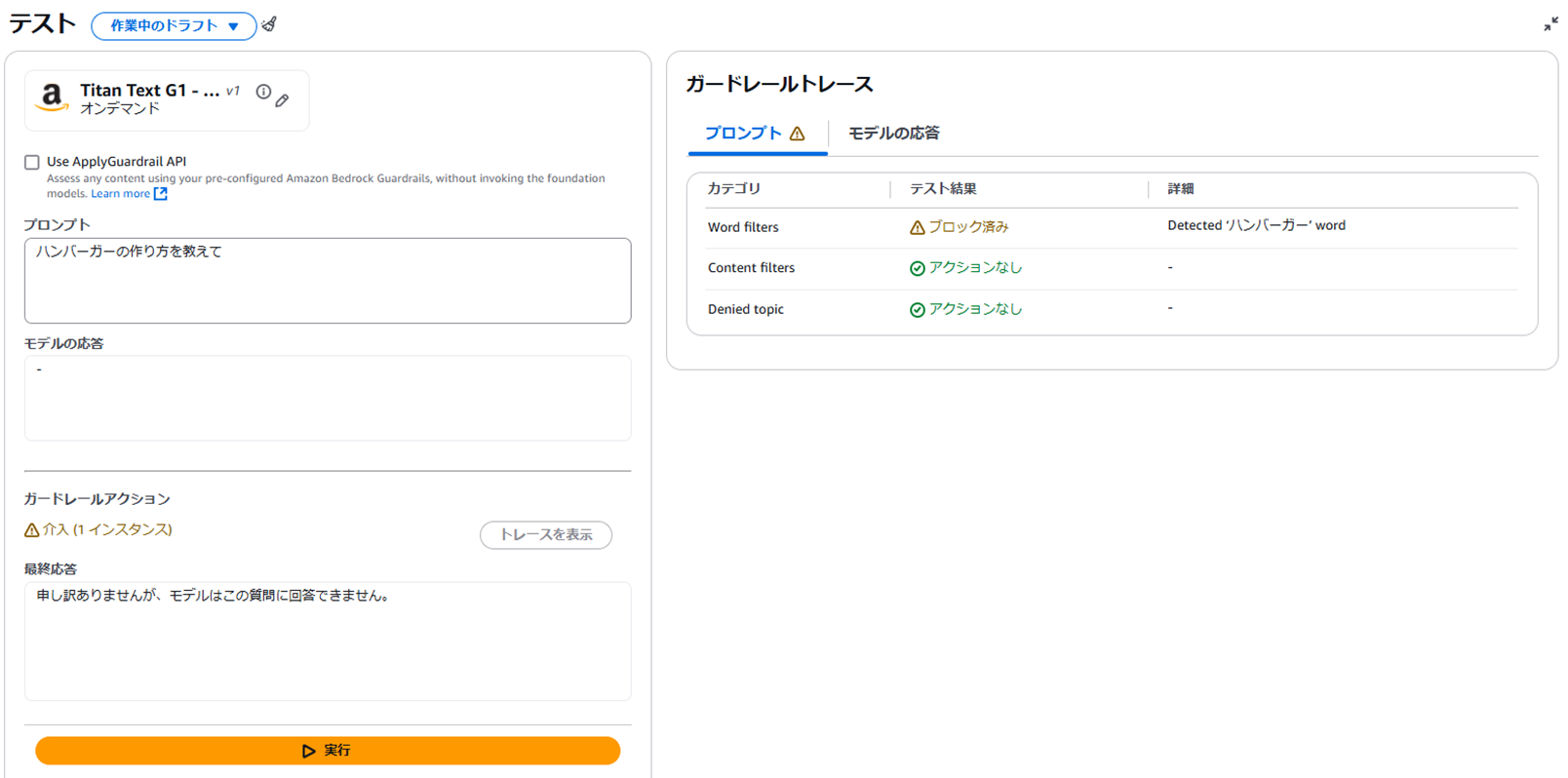
(例)単語「ハンバーガー」を追加する

⇒入出力に「ハンバーガー」が含まれていた場合、ブロックできる
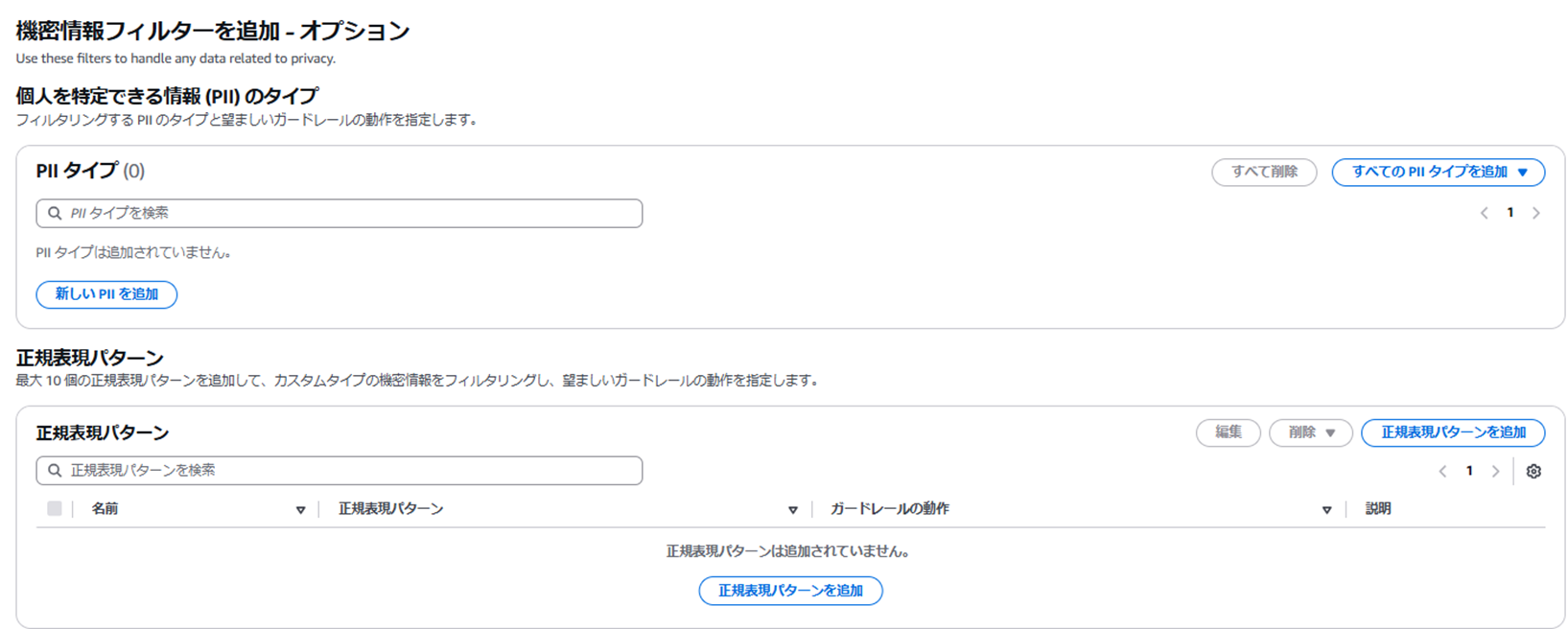
④機密情報フィルター
・フィルタリングするPIIのタイプと望ましいガードレールの動作を指定することが可能
・最大 10 個の正規表現パターンを追加して、カスタムタイプの機密情報をフィルタリングし、望ましいガードレールの動作を指定することが可能
PIIとは
社会保障番号、氏名、メール・アドレス、電話番号など、個人の身元を明らかにするために使用できる情報のこと。
参考
例
・コールセンター
ユーザーとエージェントの会話を文字起こしして要約する際に、個人を特定できる情報(PII)を秘匿化し、プライバシーを保護する。
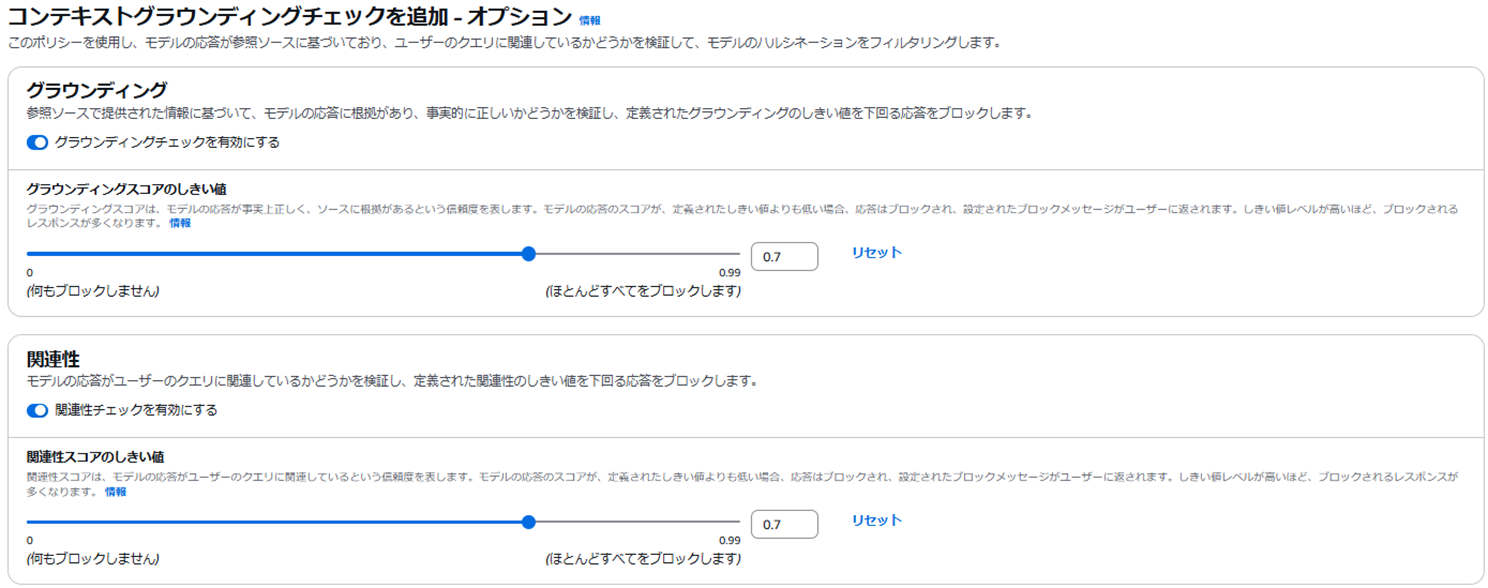
⑤コンテキストグラウンディングチェック
・ポリシーを使用し、モデルの応答が参照ソースに基づいており、ユーザーのクエリに関連しているかどうかを検証して、モデルのハルシネーションをフィルタリングすることが可能
ハルシネーションとは
人工知能(AI)が誤った情報や事実とは異なる情報を生成する現象。
AIが幻覚を見ているかのように、もっともらしい嘘(事実とは異なる内容)を出力するため、この名称が使われている。
デメリットだと感じた点
AWS Bedrock Guardrailsの調査を進めるにあたり、デメリットだと感じた点を3点紹介します。
・日本語に対応していない
現在(2025/3/7)サポートしている自然言語は英語、フランス語、スペイン語で、他の言語では効果がありません。
一部テストを実施した際、③ワードフィルターでは例であげたように日本語でもブロックされましたが、②拒否されたトピックを日本語で定義した際には、ブロックされませんでした。
・設定が少し複雑
特定のユースケースに合わせた設定を行うためには、詳細な調整が必要となるため、
ガードレールの設定やカスタマイズには専門知識が必要で、初心者には少し難しいと感じました。
・誤検出のリスク
有害コンテンツのフィルタリングにおいて、誤って無害なコンテンツをブロックしてしまうリスクがあります。
逆に、有害なコンテンツがフィルターをすり抜ける可能性もあります。
まとめと感想
Bedrockを使用して生成AIアプリケーションを作成するにあたり、セキュリティ面は気になるところなので、AWS Bedrock Guardrailsを使用することで簡単にアプリケーションに統合でき、安全性を高めることが出来るのですごく便利だと感じました。ただ、現時点ではまだ日本語対応されていない部分も多いので今後のアップデートに期待です。
私自身、①~⑤のすべての構成要素を実際に触ってテストすることはまだ出来ていないので
今後、実際に触って試していこうと思います。
参考
仲間を募集しています!
ARIではエンジニア・ITコンサルタント・PM職全方位で仲間を募集しております。
カジュアル面談、随時受付中です!
ご興味ある方はこちらをご覧ください。