この記事はNew Relic Advent Calender 2022 25日目の記事です(遅れました)
🎅🎄メリークリスマス🎄🧑🎄
New Relic Service levelsについて
バーンレートアラートの話をしたいのですが、その前にSLOモニタリングとNew Relic Service levelsについて説明します。
先生、SLOモニタリングがしたいです
Observability PlatformのNew Relicを利用する上で、サイトの信頼性を計測することは重要です。
SLOはクリティカルユーザージャーニー(CUJ)をもとに、サービスレベル指標(SLI)を決めて、サービスレベル目標(SLO)を検討するというプロセスで決定されると思います。
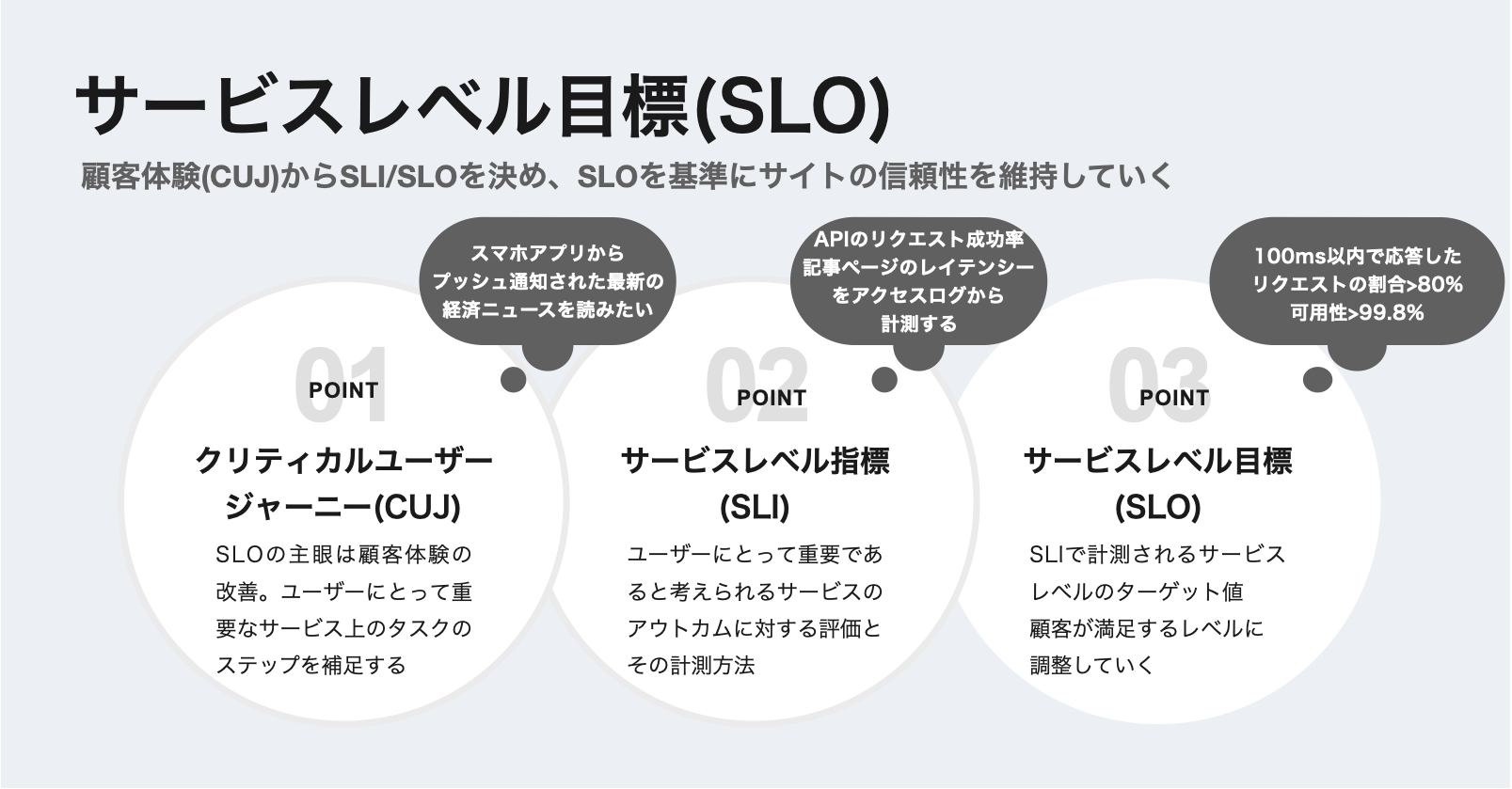
その検討の結果、以下のようなSLOで運用をはじめる時に、どうすればモニタリングできるでしょうか?
- 100ms以内で応答したリクエストの割合 > 80%
- HTTP 5xx status以外の割合 > 99.9%
もし、nginxのアクセスログなどから上記をモニタリングしようとしたら、定期的にログ分析・集計を回すことになって非常に非効率かつ時間がかかるように思えます。ログ収集・分析基盤の構築やETL・SQL・ダッシュボード・アラートの準備なども大変そうですよね。
New RelicにおけるSLOモニタリング
New Relicでは、APMエージェント等から収集したテレメトリデータをもとに「Service levels」という機能を用いて簡単にSLOモニタリングを設定することができます。
定義するのは以下の3つだけです。簡単ですね。
- valid eventsの件数を抽出するNRQL
- good responses(またはbad resposes)件数を抽出するNRQL
- 目標値となるパーセンテージ
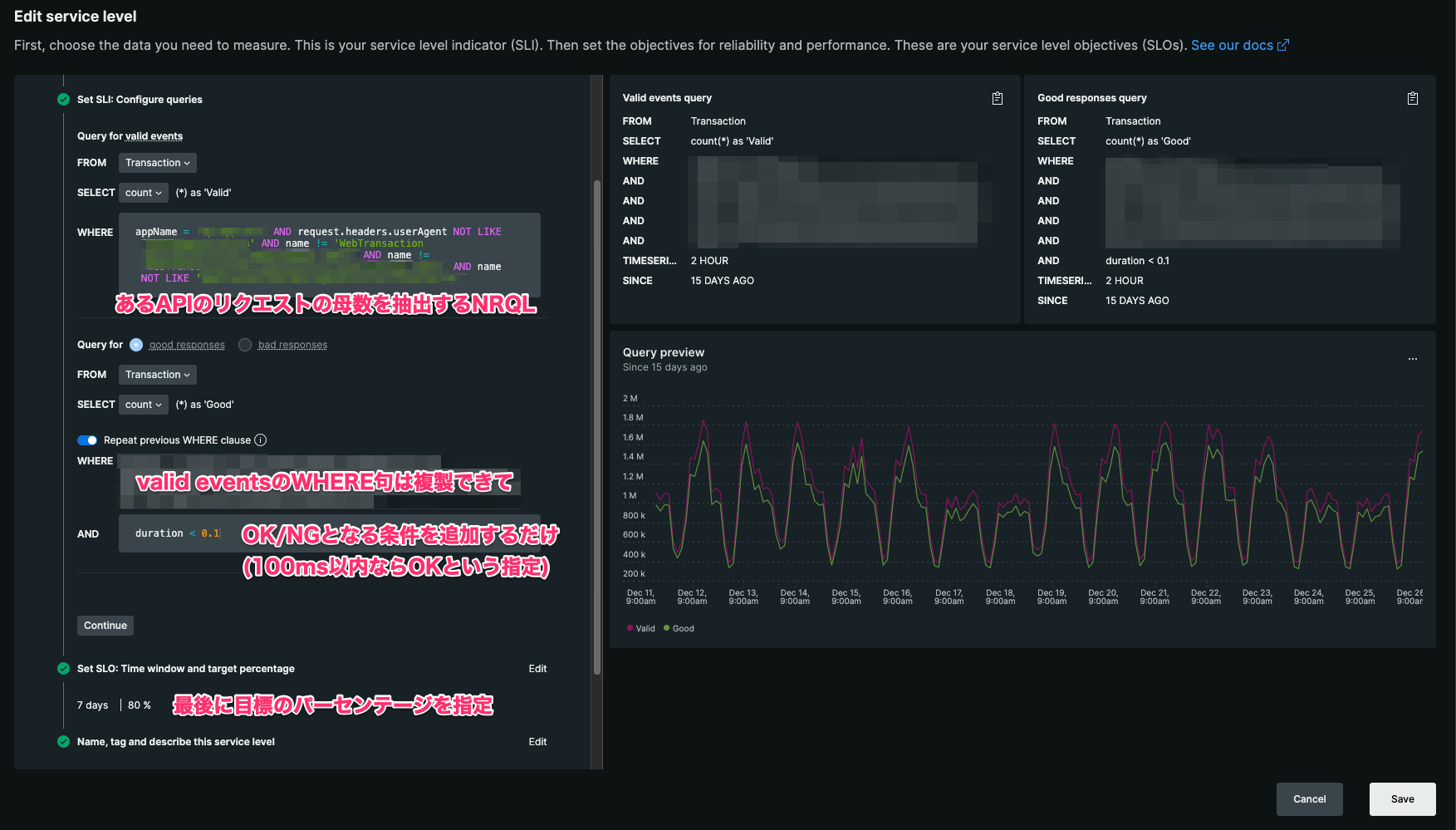
設定するとvalid eventsの件数、good responses(またはbad resposes)の件数を1分ごとのデータポイントでメトリクスとして記録してくれます。
このメトリクスをNRQLで集計・可視化することで、SLO達成状況の前週・前月との比較も行えますし、現在指定しているタイムウィンドウでの残エラーバジェットもわかります。そんなダッシュボードを標準で用意してくれています。
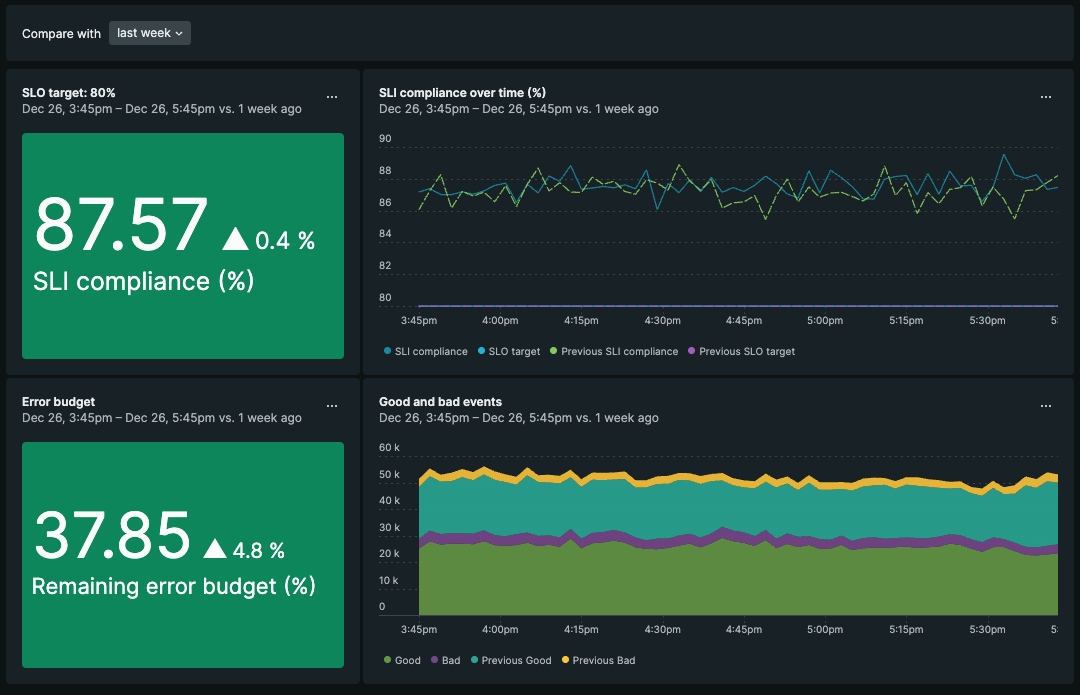
これでSLOがモニタリングできるようになりました!あとはService levelsによって作成されたダッシュボードを週次のチームMTGなどで眺めていればよいのでしょうか?
New Relic Service levelsのバーンレートアラートを設定する
さすがにユーザーにとってサービス利用影響のある障害が発生したら、検知してリアクティブにも対応できるようにしたいです。ここからが本題です。
上記で説明したように、すでにSLOの元ネタ(SLI)となるvalid events/good responses(またはbad resposes)の件数はメトリクスとして記録されていますので、「SLOを違反したらアラート」はNew Relic Alertsを使えばNRQLを書けばすぐに設定できます。問題になるのは、アラートの閾値ではなく感度です。
SREの前提として「100%の可用性はない」ことを考えると、「SLO違反したら即時アラート」というのは毎日のようにアラートが鳴ってしまいますし、「60分連続でSLO違反したらアラート」では検知するのに1時間かかってしまいます。
そこで有用なのが、エラーバジェットの消費ペースでアラートをトリガーするバーンレートアラートです。
例えば1日に24,000リクエストを受け付けるサイトが99%の可用性を達成するには、エラーバジェット(予算)のエラー許容件数は240件/日です。1時間に10件エラーが出たら24時間でエラーバジェットを使い切ってしまうことになるのでバーンレート(燃焼率)=1と考えると、バーンレートが1より大きい状態を知ることで障害の影響に応じたスピードで障害対応の初動につながります。
1時間に1,000リクエストを受け付けるサイトが1時間に10件エラーでバーンレート=1だとすると、バーンレート>2でアラートした場合、1時間かけて21件目のエラーが発生したら1時間でアラートしますが、サービス全断時にはアラートに要する時間は2分以内です。
「障害の影響に応じてアラート検知のスピードが変わる」のはシステムの監視を設計したことがあるエンジニアにとっては画期的ではないでしょうか。
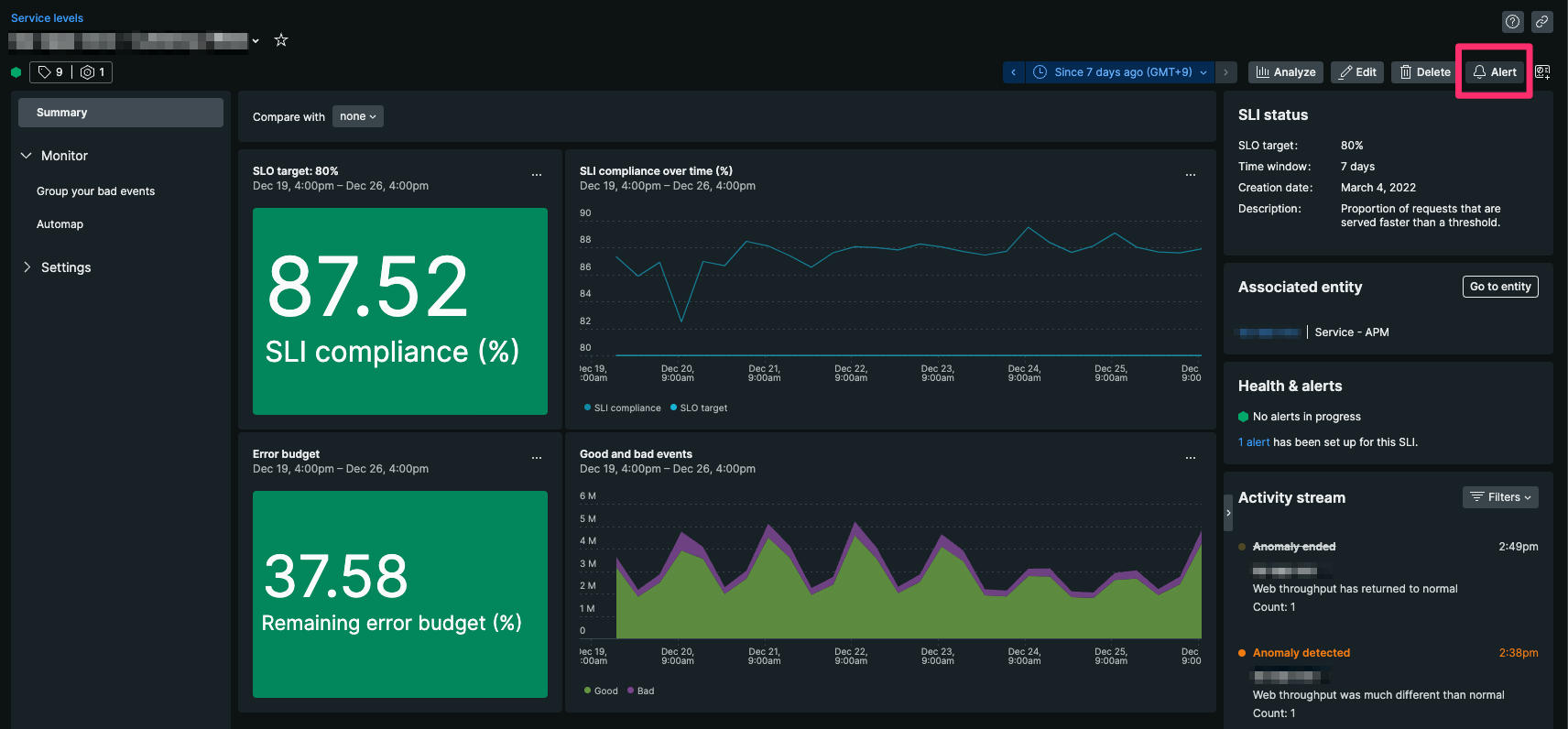
バーンレートアラートの設定はService levelsの詳細ページの右上ボタンから行います。
参考: https://docs.newrelic.com/jp/docs/service-level-management/alerts-slm/
(この機能は、2022/07/28にリリースされたようです)
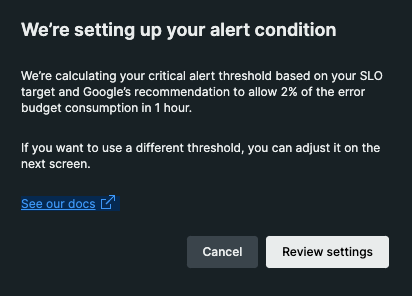
あなたのSLOターゲットと、1時間でエラーバジェットの消費量の2%を許可するGoogleの推奨事項に基づいて、クリティカルアラートのしきい値を計算しています。
という注釈が表示されて、設定に移ります。
なんと、見慣れたNew Relic Alertsの「Create an alert condition」の画面に飛んだだけです!
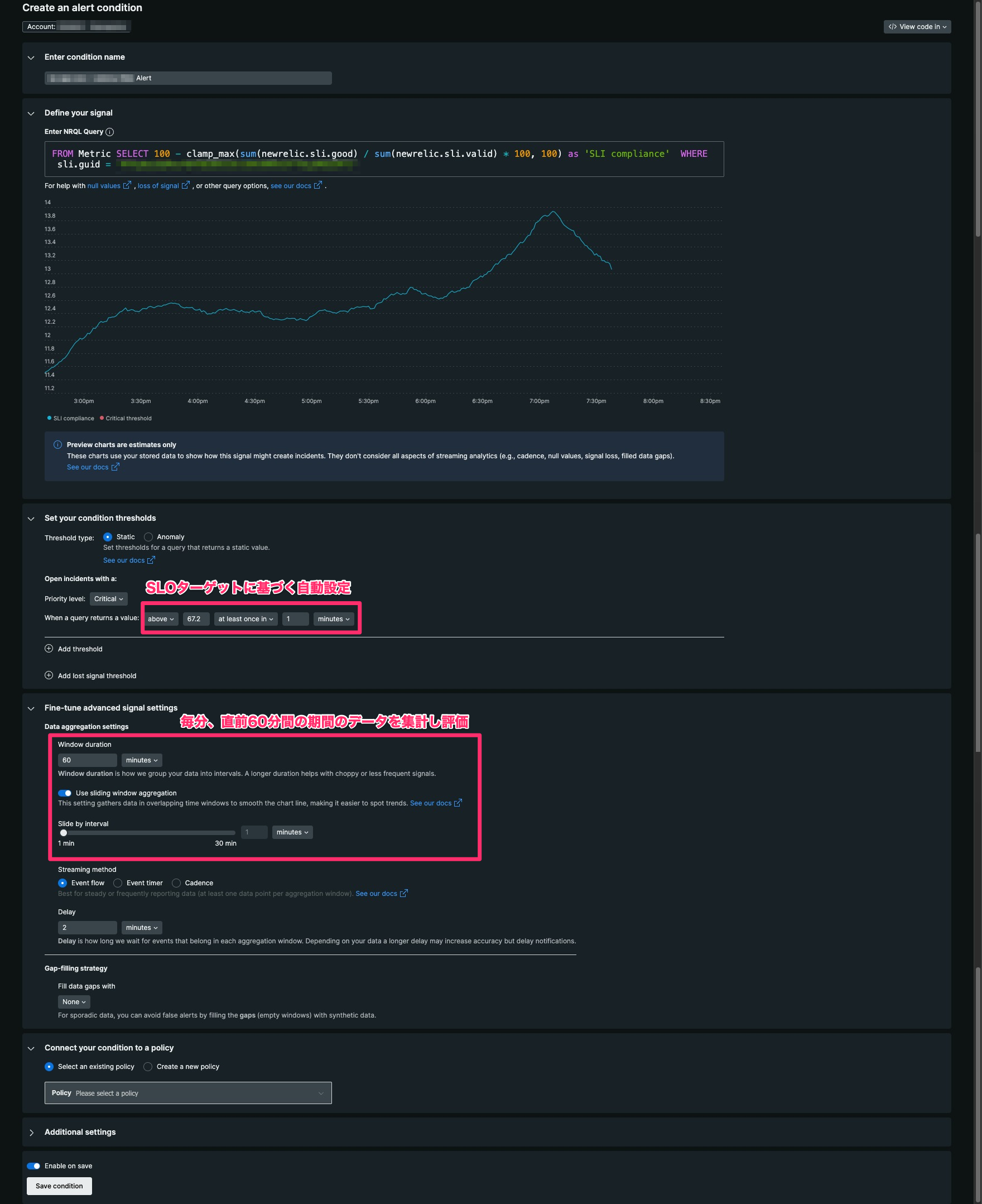
バーンレートアラートという名前がついていると、New Relic Service Levelsとして特別な機能・設定があるように思えますが、実は元々のNew Relic Alertsでもバーンレートアラートを定義することはできて、それを半自動入力で設定してくれる便利なお助け機能だったのでした。
ポイントは3点です
- アラートのシグナルを定義するNRQLで、SLO違反の根拠となるエラー割合(100-SLI準拠率)を集計している
- 1分ごとのエラー割合の閾値をSLOターゲットに基づいて自動設定している
- エラー評価の方法を、毎分、直前60分間の期間のデータを集計し評価する設定にしている
肝中の肝は2つ目の「SLOターゲットに基づく自動設定」です。
例では、「7日間の○○率80%」というSLOに対して、67.2%がエラー率の閾値として自動設定されています。
これは、Googleが1時間で2%のSLOエラーバジェット消費についてアラートを出すことを推奨しているため、50時間でエラーバジェット100%を使い切るバーンレートを検知するアラート設定となっています。
SLOターゲットが80%の場合、エラーは20%ですが、1分間で許容するエラー割合は67.2とバーンレート=3.36を閾値にしています。これは、SLO違反の閾値の3.36倍のペースで50時間エラーを出し続けると、ちょうど1週間(168時間)で許容できるエラーに達するからです(168/50=3.36)。New Relic Service Levelsからのバーンレートアラート設定は、この閾値の自動計算を行ってくれます。
ただ、サイトリライアビリティワークブックでは、28日間のSLO期間に対して1時間でエラーバジェットの2%を消費する(バーンレート=14.4の)場合にPagerを鳴らそうと記載があったので、この設定は7日間のSLO期間に対して適用されていて厳密にGoogleの推奨に準拠しているわけではなかったり、New Relic Service Levelsからの連携が不十分だったり全てのパターンに対応できていないことが考えられます。サービスの信頼性に対する適切なアラートを設定するための利用者でのチューニングは必要だと思いました。
あらためて、New Relic Alertsは高機能ですね。今まで雰囲気で設定していましたが全然使いこなせていませんでした。
バーンレートアラートの設定ロジック含め理解してようやく自分好みのバーンレートアラートが設定できるような気がしてきたので、実運用でブラッシュアップしていきたいと思います。
みなさまもNew Relic Service levelsでのかんたんSLOモニタリングとかんたんバーンレートアラート設定を使って、よいお年を!🌅