はじめに

アノテーションとは、一言で言えば学習用の正解データ(正解ラベル画像)を作成するための作業です。
Semantic Segmentationの場合は、ピクセル単位で意味的なラベルを割り当てるような作業に対応します。見方によっては、問題の定義を行うのにも近い作業とも言えます。
上の画像のようなアスパラ収穫で用いるようなシーンを例に挙げます。
この場合、各ピクセルがアスパラ・地面・チューブ・その他のどれに対応するかを人の手で割り当てる作業になります。
このSemantic Segmentationのアノテーション作業を他の方に委託する場合は、もちろんその仕様を決める必要があります。ただ、属人性を完全に取り払った形で言語化をするのはなかなか難しいと感じています。
今回は、そのようなアノテーションの側面についてのポエムです。
1. アノテーションの具体例

例えば、上のような擬葉(アスパラの葉っぱ。仮葉枝)が穂先または全体に掛かったアスパラのケースについて触れながら、アノテーション仕様を決める事の難しさについて考えてみましょう。Semantic Segmentationのアノテーションでは基本的に、可能な限り輪郭を捉えた形で行う事が望ましいです。
2. 自分が指示に悩んだ場面の一例
極端に擬葉が掛かっているケース

では、このようなかなり極端に擬葉が掛かっているケースはどうでしょうか?
一応アスパラは目視できますが、ほぼ擬葉に覆われていますし、輪郭も曖昧です。
このような場合に、あなたはどのような形でアノテーションを指示をするでしょうか?
例えば上の例について、
輪郭が不明瞭になるほど擬葉が掛かっているアスパラにはアスパララベルを付与しない
という指示を考えたとしましょう。この指示の属人性の無い形での言い換え方はできるでしょうか?
もし”文章の意味は分かるか?”と聞かれたら、多くの人がハイと答えると思います。
ただ、どこのどの部分にラベルの境界を引くか、その程度はおそらく人によって異なるのではと思います。その一つの理由は、物体の輪郭(あるいはエッジ)をあらゆるデータ・あらゆる人の直観に当てはまる形で数理的に書き下す事はおそらく難しいためです。
属人性の無い形での言語化もまた難しいです。(とはいえ問題設定にはもちろん依存する部分はありますが。)
学習上のスタンスとアノテーションの指示
画像一枚について、どのような捉え方・指示をするか一つとっても、意見や感覚・スタンスは人によって異なるように思います。
アスパラ領域をアノテーションするという立場
一方で、人間の目でも画像をよく見ると存在する事が分かる程度ではあります。人間が認識できる程度と同等にモデルを学習させたい、という目的があった場合は、上の例についてもアスパララベルを付与する方が妥当という立場もあると思います。ただし、厳密性とアノテーション作業のためのリソース消費量・作業負荷はトレードオフがあるように思います。
作業を外注する、という手段もありますが、下のような状況である場合、実際割に合わない事が多いです。
- リードタイムがシビア(農業領域においては状況が遷移することもある。納品までの1週間が長く感じる場面もある。)
- 検証のためにデータ撮影・学習・評価を短期的に行う必要がある
アスパラ領域をアノテーションしないという立場
そもそもこの領域でのアスパララベルのアノテーションはしない、という形も場合によっては採用できるのかなと思っています。
例えば、上のケースをアノテーションするに際して、次の2つの条件に当てはまっているとします。
- データセット全体から見ると非常にレアなケースである
- 学習条件を整えたとしても精密な区別が確信度高くできないようなモデル・問題設定を採用している
このような場合、下手にアノテーションしても単にノイズ的ラベルとして扱うのとほぼ同様と見なすこともできる事が多いです。実際、弁別性の強い損失関数(Lovasz-Softmax loss等)を採用した場合は、事例が少ないケースについては背景ラベルに割り振られる等"無難"に学習される傾向があるように思います。
また、そのような特徴を持たない損失関数を採用した場合も、学習上の副作用の方が大きいといった話になり得ます。
なので、あえて負例として、
輪郭が不明瞭になるほど掛かっているようなアスパラについては背景ラベルとする
といった形の指示をする事で、正確に認識して欲しい対象を際立たせるような形で学習ができる(のでは)、といった考え方もモデルによっては採用できそうです。また、1枚あたりのアノテーション時間・作業負荷も削減できます。
3. 私はどのように対処しているか
アノテーションの作業にどのような指示をするかは、
- データセットの質・量、そしてモデルがどの程度分類能力を持つか、
- アノテーションに割けるリソースがどの程度あるか
と言った事柄に左右され得ると思います。
特に、データにどのような"素性"や"多様性"があるか、現状完全に認識できているわけではない場合、
現場で実際にデータ撮影・学習・検証のイテレーションを踏まなければ分からない事柄も多いようにも思います。
場面によらず、事前に完璧な”仕様書・手引書”を事前に作る事は困難だと思います。そしてこれは、例えばインターン生にアノテーション作業を手伝ってもらう、疑問点に答える、モデルの性能を出す、といった実際の場面でも問題になり得ます。
ですので、私は「高速に仕様の検証・改善を繰り返すことができるようなデータ収集・アノテーションフレームワーク」が肝要だろう、というという視点から次のような形でツール群を作成・整備しました。
1. 現地でリアルタイムにモデルの出力結果を確認できるツール、また撮影ができるツールを作成した
- 現地で様々なケースに対しての推論結果を眺める事で、仕様の妥当性が怪しい場面を効率よく洗い出す事ができる
- 事前にモデルやデータを触った事が無い人でも、モデルの実力や振る舞いをツールを通して直観的に把握できる
- モデルを改善した際にはその性能的差分も柔軟に確認できる
- 上の結果を踏まえて、実例ベースでアノテーション仕様を議論できる
2. 事前学習済のモデルを用いて、アノテーションデータを自動生成できるような形にした
- 事前に、ラフにアノテーションを行わせる事で、作業時間を短縮した
- ある程度適切なアーキテクチャを選定したり、多少の手作業でのアノテーション等の事前作業は必要
3. インターン生等に2.で生成したデータを用いてアノテーションしてもらい、仕上げは画像処理エンジニアが行う
- アノテーションの要求仕様が完全には言語化できないことを前提として、QA作業を行いやすいツールを選定した
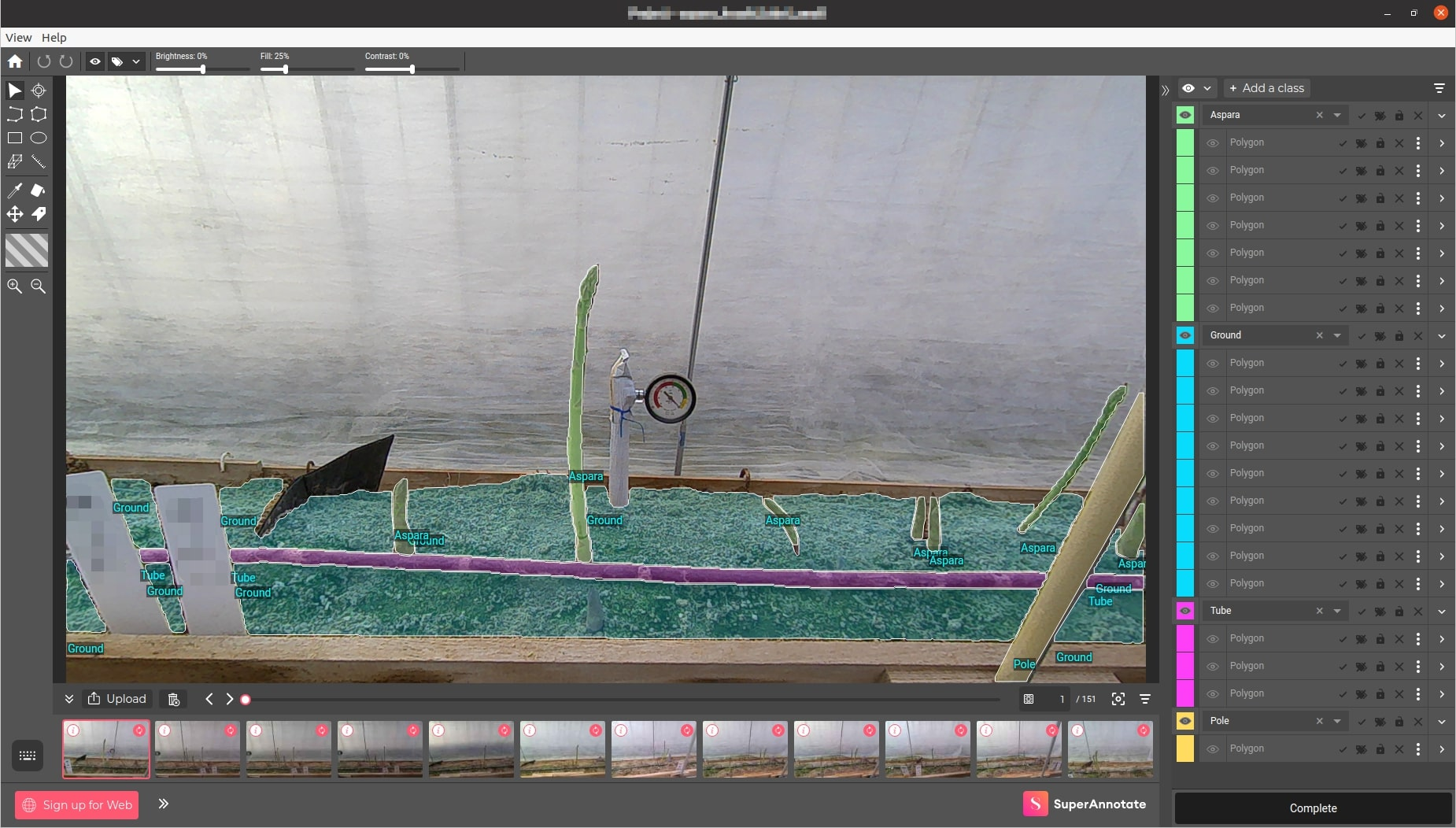
- アノテーションツールは、カスタマイズ性・操作性・分散作業の容易性からSuperAnnotateを選定した
- 要求仕様と厳密に合わない箇所は画像処理エンジニアの手で修正する事ができる
おわりに
近年は、ニューラルネットワークのアーキテクチャや学習用フレームワークの進化だけでなく、例えばバックエンドに合わせて柔軟に推論を高速化できるフレームワークや、最適なハイパーパラメタ・モデル設定等を探索・管理するための実験ツール等、一定のデータや計算資源がある場合に問題解決のための手段を効率よく探り当てる事ができる世の中になってきていると思います。(少なくともニューラルネット周りについては、あくまで私見ですが)
ただ、ゼロから学習用データを得たい、という段階においては領域依存・組織依存の問題から避けられる事はできませんし、アノテーションの仕様決定については話が出にくい割にそれなりに大変な部分だと思います。
そういった意味で、少なくとも自分たちはこうしてるよ、という知見共有も誰かの琴線に触れる事もあるのかなと思い情報を共有した次第でした。