はじめに
はじめに言っておきますが、読書メーターの情報はエクスポートできません。詰みました。お疲れ様です。
しかし、エクスポートの目的は過去情報を抽出することなので、とりあえず強引にでも抽出できればOKなわけです。これは疑似エクスポートみたいな感じですかね(そんな大したことやってるわけじゃない)。
僕は読書メーターを使っていたんですが、あまり使い勝手がよくないと思って使っていました。「もういっそのことスプレッドシートで読書管理・記録しよう!」と決めたのです。
自分が欲しいと思った情報は、読了した書籍の読了日、タイトル、著者名ぐらいでした(+αのページ数)。感想とかは全部書いているわけじゃないし、スプレッドシートで管理はしないだろうなーと思ったので不要でした(感想文はノートで記録するか、書くなら本のキーワードぐらいでいいかな)。Webスクレイピングもダルイし、簡単な方法ないかなーって感じ。
簡単な方法ありました。
※プログラミングとか全然わからない人いたら「最後に」のところだけ読んでください。
完成図
読書メーターの記録をスプレッドシートへ移行できました~。

必要事項
- 環境:Python 3.7.4
- 読書メーターの情報
- 読了日
- タイトル
- 著者名
- ページ数
準備:読書メーターの情報の入手
1.「読んだ本」→「テクストのみ」にしてそのままコピーします。
これが意外と盲点だったこと。「テキストのみ」の機能使ったことなかったんですが、「めっちゃ使えるじゃん!」って思いました。
この記事の最大のポイントです。あとはコピペで終わり。楽勝。あなたの発想力で煮るなり焼くなりできると思います。
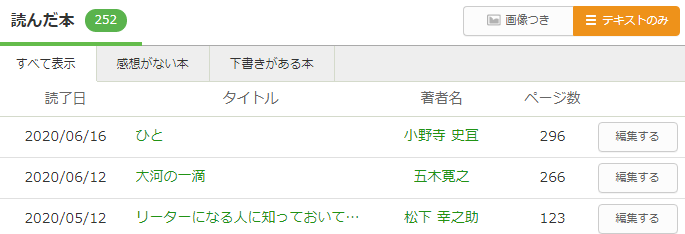
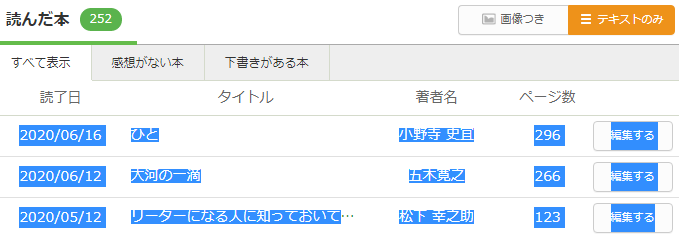
2.Excelにすべてをそのまま張り付ける

※実は張り付け方もっといい方法あるんですかね?これがよく分からなかったのでPythonで整地したんですけど。よくわからなかったので縦コピーになっちゃったんですよね笑。それで「どうするか」ってなって強引に弄りました。
3.不足情報を追加または修正する
たまに情報がないやつがあります(以下の画像)。タイトルと著者名が一緒のセルに入っていることもある。適宜修正してください。僕はプログラムを実行しながら修正していきました。そっちのほうが分かりやすいかも。

4.ExcelをCSVにして保存する
とりあえず名前はinput.csvにしておきます。
プログラムを実行する
アニメ見ながら脳死で書きました笑。自分用に適当に作ったのでクソ汚いです。
一回書いたら終わりの捨てプログラムだったのでお許しください。
import csv
import pandas as pd
RESULT_CSV_TITLE = 'output.csv'
date_list = []
title_person_list = []
page_list = []
df = pd.DataFrame()
with open('input.csv', mode='r', encoding='utf-8') as f:
all_row = csv.reader(f)
for row in all_row:
# 空白と余計な列を削除
if len(row) == 0 or row[0] == '編集する':
continue
# 日付
try:
if '日付不明' in row[0] :
date_list.append(row[0])
continue
date_split = row[0].split('/')
year = date_split[0]
month = date_split[1]
day = date_split[2]
date_list.append(f'{year}/{month}/{day}')
continue
except:
pass
# ページ
try:
page = int(row[0])
page_list.append(page)
continue
except:
pass
# タイトルと著者のリスト
title_person_list.append(row[0])
title_list = title_person_list[::2]
person_list = title_person_list[::-2]
# print(len(date_list))
# print(len(page_list))
# print(len(title_list))
# print(len(person_list))
person_list.reverse()
df['日付'] = date_list
df['タイトル'] = title_list
df['著者'] = person_list
df['ページ'] = page_list
print(df)
df.to_csv(RESULT_CSV_TITLE, index=False)
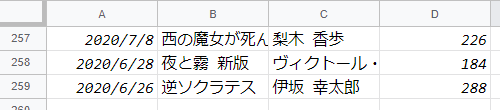
結果
PyCharmを使って結果を見ているので以下に示す画像のようになります。
日付、タイトル、著者名、ページ数って感じになりました。

あとは煮るなり焼くなりしてください。
僕はスプレッドシートにoutput.csvの中身を全コピーして、コンマ区切りで分割しました。
最後に
「プログラムも何もわからない!」って人は @yuki_imamura_ のDMにでも連絡ください。お手伝いできればします。
いや~、それにしても読書管理・記録アプリは色々使ってきたけど、どれも微妙だね。結局はGoogle スプレッドシートとかで自分で管理するのがいいのかね。
Webスクレイピングを使えば読書感想文も抽出できると思います(サービスの規約は見てません)が、今回僕は必要なかったので簡単にやりました。どうしても必要だという方がいればプログラム作るのでそれもDM飛ばしてください。
ページ数は…一個のモチベーション指標として使っていこうかな~。
てなわけで読書生活を思う存分楽しみましょう!
何かの参考になれば幸いです。