はじめに
初心者がWEBを支える技術を読むにあたり、単語の意味とそれが何を示してるのかわからないので
読んで進めていても理解しにくい。自分なりに理解し、アウトプットする事で、理解を深めていく。
WEBとは何か?(第1章)
大きく3種類に分類される。
WEBサイト
一番イメージしやすい。グーグルのページとか。
どうやって表示しているのか、どうやって処理しているのかをイメージしなくても
ユーザーが使えるのがWEBの魅力である。
ユーザインタフェースとしてのWeb
見た目を整えて、ブラウザの設定をしたりする。
昔はハードのリモコンボタンでしていたが、今はブラウザ上で設定するのがほとんど。
端的に言えば、フロントエンドエンジニアが関わる領域。
プログラム用APIとしてのWeb
本書では、ややこしいのでWebAPIと呼ぶ。
端的に言えば、バックエンドエンジニアが関わる領域。
APIはプログラム用のインタフェース。ってイメージ。
データフォーマットにはXML(ExtensibleMarkupLanguage)
JSON(JavaScriptObjectNotation)を使う。
XMLについて詳細 https://www.graffe.jp/blog/2911/
JSONについて詳細 https://www.json.org/json-ja.html
WEBを支える根幹の技術
HTTP(URLとHTMLをやり取りする為する取り決め)
URL(WEB住所)
HTML(WEB文字)
HTMLはXMLを基にした汎用の言語。
ハイパーメディアと分散型システム
WEBを支える技術の根幹にある。
ハイパーメディア
リンクでデーターを結びつける事。
書籍などで目次を確認する以外だと"ドラえもんの生態"のページを探すには先頭から読むしかなかったが
リンクを結びつける事で"ドラえもん"と検索するだけで対象ページが見つかるようになった。
分散システム
一箇所にあるコンピューターで処理するのでなく、世界中に散りばめられたサーバーにアクセルする事で多数のコンピューターで処理ができる。
様々なパソコンが同時にアクセスし処理ができるのは、HTTPのプロトコルが簡単だから。
WEBの歴史(第2章)
インターネットの始まりなどは割愛。
RPCは分散システムを実現する為に必要な技術(昔は)
ただ、問題があり、大規模分散システムとはならない。
1990年にバーナーズリーガWEBを発明。サーバーとブラウザを公開。
最初流行ったブラウザはモザイク。
RPCと違い、HTTPのプロトコルが簡単だから流行った。誰でもアクセルできるって感じかな。
ロイフィールディングがWEBのアーキテクチャを決定付けた(構造)
このアーキテクチャをRESTと名付けた
ハイパーメディアの複雑化
情報のやり取りがHTMLだけだと対応できなくなって新たな仕組みが生まれた。
microformats
RSS
JSON
今後学習する上で必要なら上記言葉の意味を理解するにとどめる。
文書を読むためのWEBからプログラムを実行するためのWEBへ
アマゾンが2002年に自社で扱う書籍のデーターをWEBを通じてプログラムで取得する技術を開発した。
これにより、WEBを使って処理するのが素晴らしいと世の中が便利さに気づき始める。
RPCの技術を発展させたプロトコルも出てはいたが、複雑さと政治的な理由から現在のWEBの技術にインターネットが飲み込まれ始める。
RESTというアーキテクチャスタイル(第3章)

アーキテクチャスタイルとはRESTその物の事をさす。
実装を一つ抽象度をあげたものをアーキテクチャと呼び更に抽象度をあげたものをアーキテクチャスタイル(REST)と呼ぶ。
RESTを構成する重要な概念を順に紹介する。
リソースとは
RESTの重要な概念の一つ。WEB上に存在するありとあらゆる名前を持った情報の事。
リソースの名前とはURLの事です。
このURLがもつリソースの情報を簡単に指し示す事のできる性質を<アドレス可能性>よーするにURLにちゃんとした名前をつけておけば、プログラムを作成しやすくなります。一つの情報は複数のURLを持つ事ができる。サーバーとクライアントの間でやり取りするデーターを<リソースの表現>と呼ぶ。
サーバーとクライアント(アーキテクチャスタイルその1)
HTTPプロトコル。プロトコルとは手順や約束事。HTTPプロトコルに準じて、サーバとクライアントがやり取りをする。
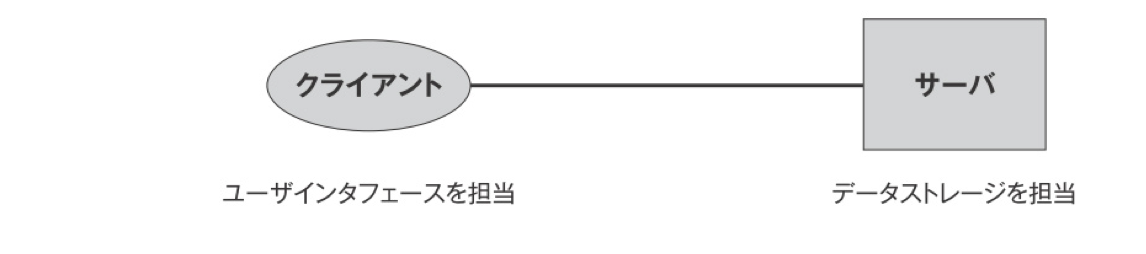
この仕組みのメリットはクライアントとサーバを分離し処理ができる。だからクライアントをマルチプラットフォームにできる。よーするにWEBは携帯からPCゲームまでなんでもやり取りができる。しかもUIはクライアント側の仕事のため、サーバーはデーターストレージとしての機能をもつだけで良い。 (ストレージ 記憶装置)
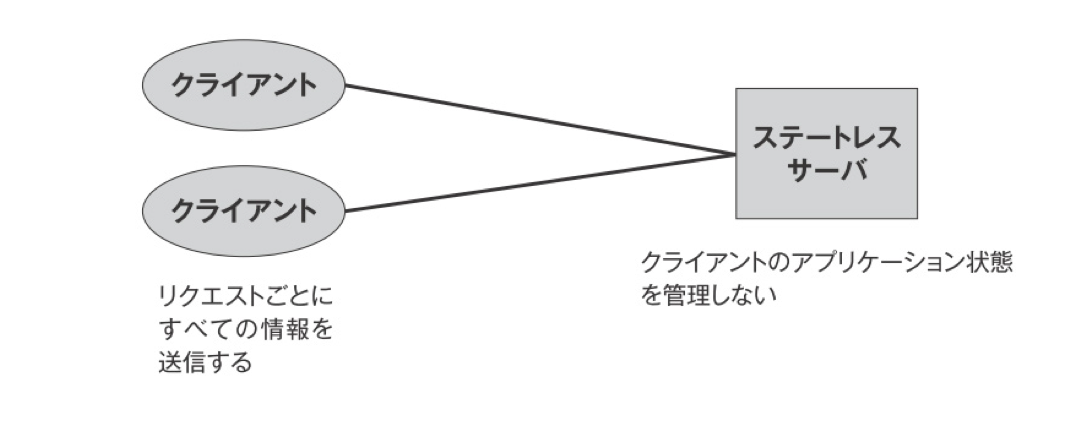
ステートレスサーバー(アーキテクチャスタイルその2)
クライアントのアプリケーションの状態をサーバーで管理しない事。これによりサーバーの実装を簡素化できる。ただ現実にはCookieを使ったセッション管理などあえてステートレスではない処理をしているケースもある。あくまでの必要最低限の実装にする理解で留めておく。
キャッシュ(アーキテクチャスタイルその3)
一度取得したリソースをクライアント側で使い回す事。
メリットはサーバーの通信を減らすことで負担減となる。
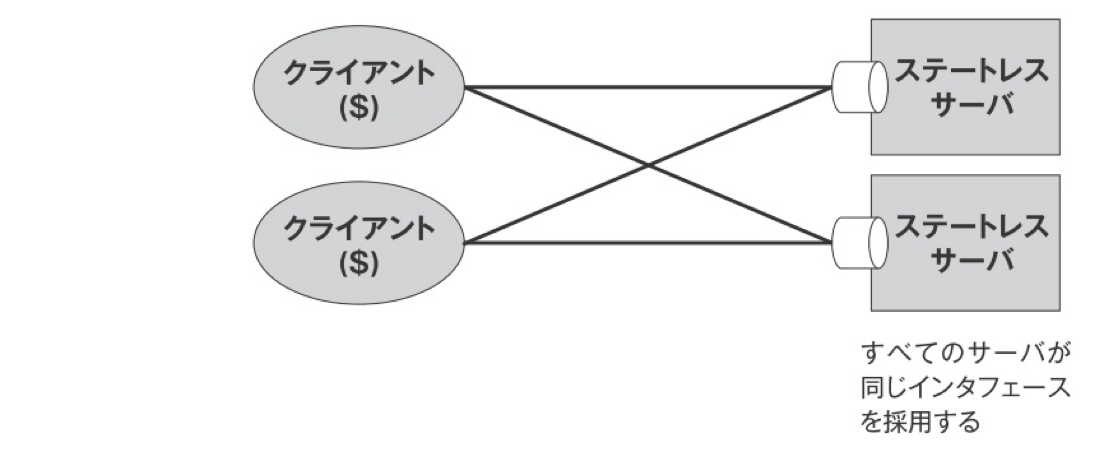
統一のインターフェイス(アーキテクチャスタイルその4)
限定した8個のメソッドで処理をする。これ以上メソッドを拡張出来ない制限を加えることで、シンプルなアーキテクチャを実現した。この統一インターフェイスがRESTを印象づけるアーキテクチャです。
階層化システム(アーキテクチャスタイルその5)
統一UIを採用していることで階層化システムを採用しやすくなっている。
サーバーの負荷分散のためにプロキシを設置してアクセスを制限したりする。
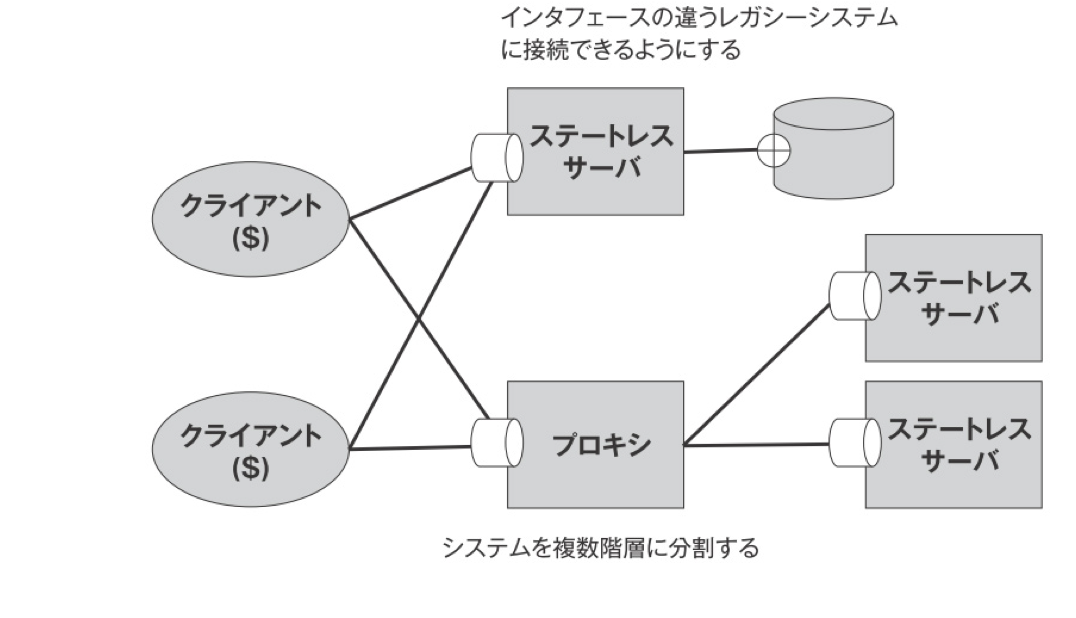
プロキシとは
直訳は代理。統一したUIのおかげで、クライアントはプロキシに繋がろうが、サーバーに繋がろうが、意識することはない。
サーバーに対しては、クライアントの情報を受け取る。クライアントに対してはサーバーの情報をサーバーの働きをする。
コードオンデマンド(アーキテクチャスタイルその6)
サーバーからプログラムコードをDLしてクライアントで実行するアーキテクチャスタイル。
メリットはクライアントを後からいくらでも拡張できる事。HTTPアプリケーションプロトコルに従って通信している間はリソースは明白なのに対して、DLしクライアントで実行してしまうので、可視性は低下する。
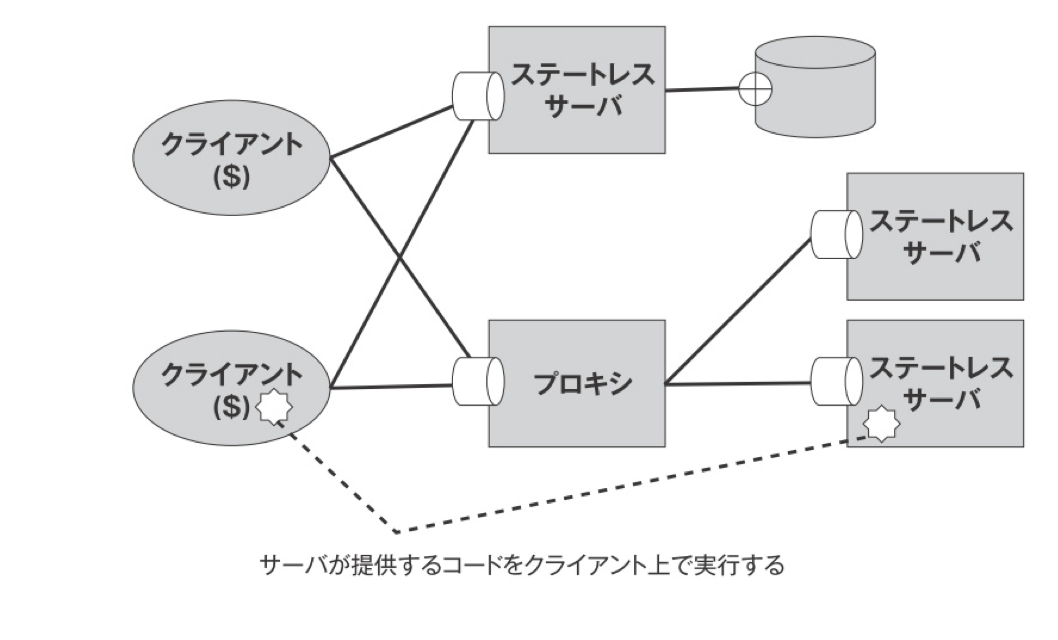
RESTのアーキテクチャスタイルのまとめ
この6つを組み合わせたアーキテクチャスタイルをRESTと呼ぶ。
1クライアント/サーバーをで分けて、ユーザーインターフェイスと処理を分離する事
2ステートレスサーバー(サーバー側でアプリケーションの状態を持たない)
3キャッシュ(サーバーとクライアントの通信を減らす)
4統一インターフェイス
5階層化システム
6コードオンデマンド
アプリケーション状態エンジンとしてのハイパーメディア
WEB上のリソースが持つリンクを辿ってその作業をいくつか実施することで一つのアプリケーションを実現すること
この考え方は接続性とも呼ばれる。
RESTful
RESTの制約に従って、RESTらしい設計をする事
URLの設計と実装について(第4章)
URLは日本語で言い換えると、リソースを統一的に認識するID。つまりURLさえあれば、WEB上にあるリソースを全て指し示す事が出来る。
URLを構成するパーツの例(簡単な構成バージョン)
http://blog.example.jp/entries/1
まずリソースにhttpでアクセスすると宣言。://をつけるのがルール。
ホスト名は必ず被らない名前かIPアドレスを使う。そのホストの中でリソースが被らないように階層パスが続く。
・URIスキーム:http ・ホスト名:blog.example.jp ・パス:/entries/1
URLを構成するパーツの例(複雑バージョン)
http://yohei:pass@blog.example.jp:8000/search?q=test&debug=true#n10
ユーザー名とパスワードは<:>で区切ります。
HTTPのポート番号のデェフォルト値は80番です。
クエリパラメーターはクライアントから動的にURLを生成します。(いまいちわからん)
URIフラグメントはクエリパラメメーターで指定したURLのさらに細かいリソースを指定するときに使用する。
例えば、それがHTML文だった場合はod属性値がn10である要素となる。
・URIスキーム:http ・ユーザ情報:yohei:pass ・ホスト名:blog.example.jp ・ポート番号:8000・パス:/search ・クエリパラメータ:q=test&debug=true ・URIフラグメント:#n10
相対URIと絶対URI
絶対URIは階層全て記載するイメージ。
http://example.jp/foo/bar
相対URI
URIスキームやホスト名を除く。
/foo/bar
見てわかるように、相対URIだけではクライアントが場所を認識できない。
相対URIでもURIを認識するようにしなければならない。
その為に絶対から相対にURIを変える事を相対URIを解決するという。
相対URIを解決する手段
HTMLの場合、
に情報を加え、明示的にする。%エンコーティング
URIで対応していない文字列を変換し表示すること。

URI長さ制限
IEが2038バイトまでしか対応していないので、それ以下の容量とする。
URI実装で気をつける事
相対URIを解決する事。
%エンコーティングの扱いでUTF-8を使用する事。
URIとURLの違い簡単に説明
URIはURLとURNの総称。
URLはドメインを更新しない時やサーバーが何かしらの障害で変更になったときにアクセス出来なくなる仕組み。
その保険的なイメージでURNとはドメイン名とは独立してリソースに恒久的にID(名前)をつける事。
但し、URNは取得ができない。WEBの価値が向上し、URLで十分永続的に接続出来るようになっている。
URIの設計(第5章)
クールなURLは変化しないのが前提にあり、付け方の法則的なのがある
こんな感じで特定の言語に依存する書き方や、サーブレットコンテナのパスを入れるようなのはNG。変化する可能性が高いから
http://example.jp/servlet/LoginServlet
- URIにプログラミング言語依存の拡張子を利用しない(.pl、.rb、.do、.jspなど)
- URIに実装依存のパス名を利用しない(cgibin、servletなど)
- URIにプログラミング言語のメソッド名を利用しない
- URIにセッションIDを含めない
- URIはそのリソースを表現する名詞である
ユーザビリティの高いシンプルなURIが良いよね
http://example.jp/login
URIを変更するとき
リダイレクトちゃんと設定しようね
HTTP/1.1 301MovedPermanently
Location:http://example.jp/new
URIの不透明性
Webにおけるリソース操作は、HTMLなどのリソース中に出現するリンクをたどって行います。つまりクライアントは、あくまでもサーバが提供するURIをそのまま扱うだけです。URIの内部構造を想像して操作したり、クライアント側でURIを構築したりしてはいけません。なぜなら、サーバ側の実装でURIの構造を変更したとたんにシステムが動かなくなってしまう、いわゆる密結合状態になるからです。このように、URIをクライアント側で組み立てたり、拡張子からリソースの内容を推測したりできないことを、「URIはクライアントにとって不透明(Opaque)である」と言います。
URIを意識して設計しましょう
- URIはリソースの名前である
- URIは寿命が長い
- URIはブラウザがアドレス欄に表示する
HTTPの基本(第6章)
インターネットのプロトコルは階層型
4つの層に分かれている。

ネットワークインターフェイス層
一番下の物理的なケーブルやアダプタに相当する部分。
インターネット層
この層を担当するのが、IPです。IPではデーターの通信単位をパケットと呼ぶ。
パケットとは指定したIPアドレスをパケット単位で通信している。
送り出したデーターが最終的な送り先まで届くかは保証しない。
トランスポート層
IPが保証しなかったデーターの転送を保証する。TCPが相当する。
保証の仕方は、コネクションを使って漏れをチェックする。どのアプリケーションに渡るのかを決定するのがポート番号。
アプリケーション層
HTTPやメールやDNSを実現する層です。
HTTPのバージョンについて
今は1、1で後継のバージョンも議論されている。
ただ、現在ではRESTアーキテクチャスタイルに価値を見出しており、HTTP1.1を有効に活用できる開発をしていく流れとなっている。
リクエストとレスポンスについて
HTTPはクライアントが出したリクエストをサーバーで処理してレスポンスを返します。
クライアントはレスポンスが返るまで待機します。
クライアントで行われる事
1.リクエストメッセージの構築
2.リクエストのメッセージの送信
3.(レスポンスが返るまで待機)
4.レスポンスメッセージの受信
5.レスポンスメッセージの解析
6.クライアントの目的を達成するために必要な処理
サーバーで行われる事
1.(リクエストの待機)
2.リクエストのメッセージの受信
3.リクエストメッセージの解析
4.適切なアプリケーションプログラムへの処理の委譲
5.アプリケーションプログラムから結果を取得
6.レスポンスメッセージの構築
7.レスポンスメッセージの送信
HTTPメッセージ
リクエストメッセージとレスポンスメッセージをまとめた言い方。
HTTPのメッセージの構造

スタートライン
- リクエストメッセージの場合はリクエストライン。
- レスポンスメッセージの場合はステータスライン。
ヘッダ
ヘッダ各行の改行はCRLFです。※CRLFとは、テキスト(文字)データの中で改行を指示する特殊な文字コードの組み合わせ
ヘッダの終了は空行で識別します。ヘッダは省略できます
空行
ボディ
テキストとバイナリデータ(コンピュータさんが見て分かるデータのこと)記載。
省略可能
ステートフルとステートレスについて
RESTの設計の重要なアーキテクチャである。
ステートレスなサーバー設計ですが、意味を完結に表すなら、ステートレスはくどい会話になる。
一見ステートフルがいいように見えるが、無数のクライアントのリクエストを受けるサーバーにおいて、処理しきれない問題が生じる。
ステートフルの欠点
クライアントが増えた時にスケールアウトしづらい
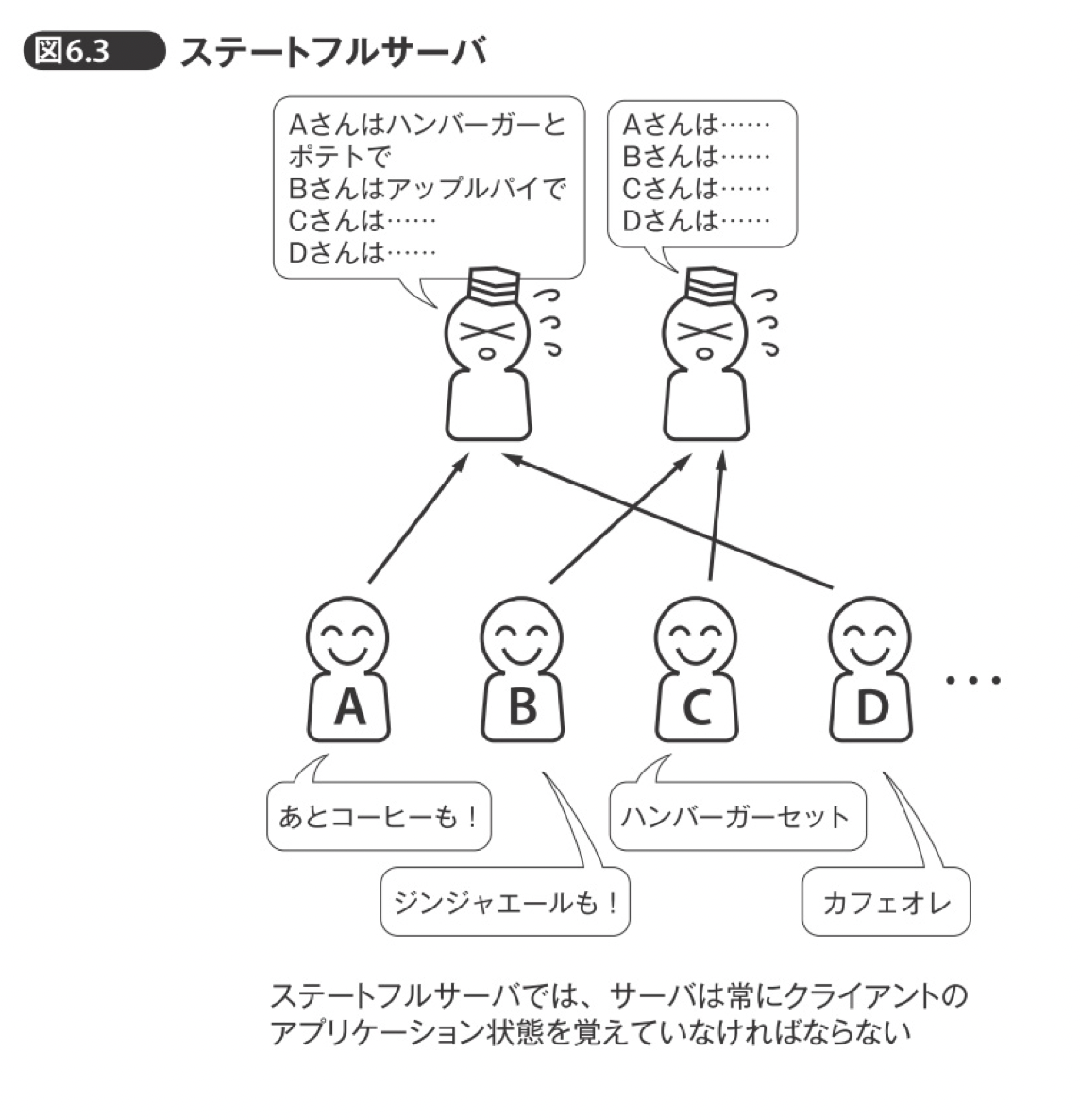
ステートレスの欠点
送信するデーター量が多くなる。
リクエストを重複してレスポンスを返す恐れがある。
HTTPメソッド(第7章)
通常のプログラミング言語の感覚からすると、HTTPでは非常に少ない数のメソッドしか定義していません。しかしこれこそが、RESTの統一インタフェース制約です。メソッドを限定して固定したからこそプロトコルがシンプルに保たれ、Webは成功しました。GETに隠された安全性、PUTとDELETEのべき等性、そしていざとなったらなんでもできるPOST。HTTPはそれぞれのメソッドに合った性質と拡張性を備えた、優れたプロトコルです。

このメソッドを正しく使用するのが重要である。
上記メソッドの中でCURDと呼ばれる
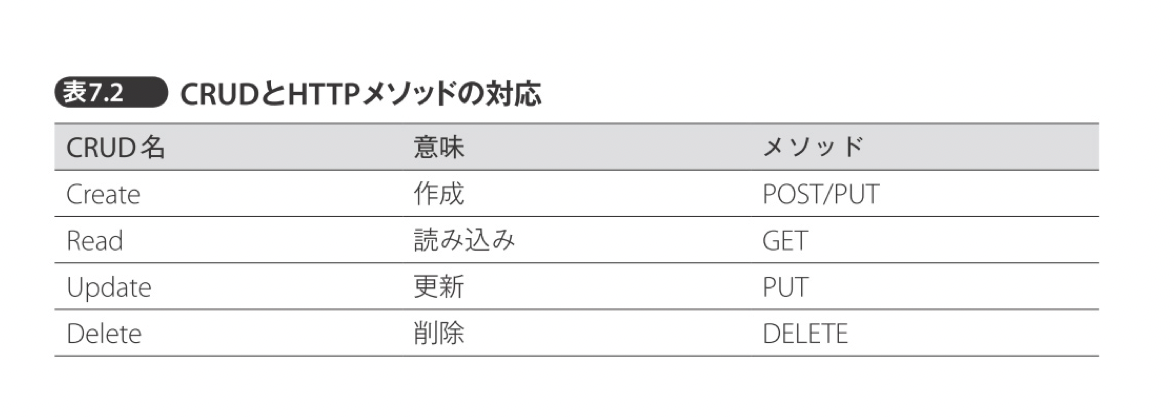
が代表的なメソッドである。
POSTとPUTの使い分け
- POSTでリソースを作成する場合、クライアントはリソースのURIを指定できない。URIの決定権はサーバ側にあります。たとえばTwitterのようにつぶやきのURIをサーバ側で自動的に決定するWebサービスの場合は、POSTを用いるのが一般的
- PUTでリソースを作成する場合、リソースのURIはクライアントが決定します。Wikiのようにクライアントが決めたタイトルがそのままURIになるWebサービスの場合は、PUTを使うほうが適しているでしょう。
べき等と安全性

ステータスコード(第8章)
- 1xx:処理中処理が継続していることを示す。
- 2xx:成功リクエストが成功したことを示す
- 3xx:リダイレクト
- 4xx:クライアントエラークライアントエラーを示す。
- 5xx:サーバエラー
よく使われるコード
200 OK リクエスト成功
201 リソースの新規作成
301 リソースの恒久的な移動
303 別のURIの参照
400 リクエストの間違い
401 アクセス権不正
404 リソースの不在
500 サーバ内部エラー
503 サービス停止
ステータスの具体的な実装方法は使われるフレームワークやWEBサーバで異なる。
HTTPヘッダ(第9章)
ヘッダは、メッセージのボディに対する付加的な情報、いわゆるメタデータを表現します。クライアントやサーバはヘッダを見てメッセージに対する挙動を決定します。メディアタイプや言語タグなど、フレームワークではなく実装者が具体的に設定しなければならないヘッダも多くあります。また、リソースへのアクセス権を設定する認証や、クライアントとサーバの通信回数と量を減らすキャッシュなどのHTTPの機能はヘッダで実現します。認証やキャッシュなどの機能は、ヘッダをメソッドやステータスコードと組み合わせて初めて実現できます。メソッドやステータスコードと並んでHTTPの重要な構成要素です。
日時
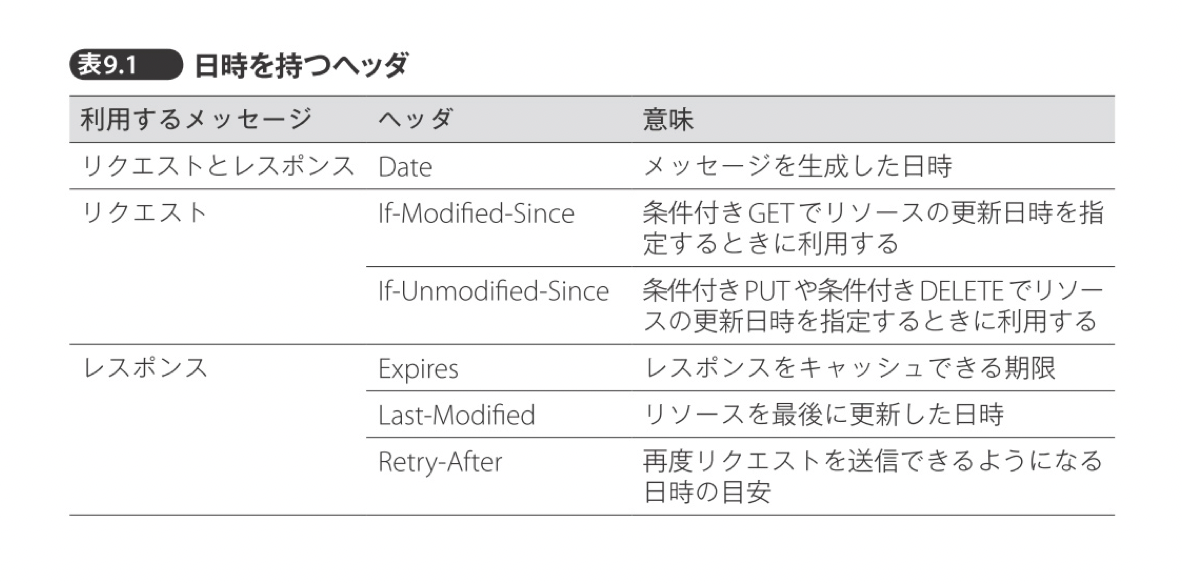
HTTPでは日時はすべてGMTで記述することになっています。これにより、サマータイムなどの複雑な問題を回避できます。
MINEメディアタイプ

ContentType:application/xhtml+xml;charset=utf8

chartsetパラメータ
省略可能だが、コンテンツタイプがテキストの時は注意が必要。
、textタイプのデフォルト文字エンコーディングはISO88591と認識する。なので、日本語を扱う時は、フォーマットを指定したあげる
ContentType:application/xhtml+xml;charset=utf8
こんな感じで。
言語タグ
charsetパラメータは文字エンコーディング方式を指定するものでしたが、リソース表現の自然言語を指定するヘッダも存在します。それがContentLanguageヘッダです。ContentLanguageヘッダの値は「言語タグ」(LanguageTag)と呼ばれる文字列です。これはRFC4646(言語タグ)とRFC4647(言語タグの比較方法)が定義しています。例を見てみましょう。
ContentLanguage:jaJP
Accept
クライアントが自分の処理できるメディアタイプをサーバに伝える場合は、Acceptヘッダを利用します。次の例を見てください。
Accept:text/html,application/xhtml+xml,application/xml;q=0.9
ContentLengthとチャンク転送
ボディの要素で送るサイズを指定する。静的ファイルなどで使用
ContentLength:5538
認証
Basic認証
ユーザ名とパスワードによる認証。Authorizationヘッダに情報を載せている
暗号化されている様に見えるユーザ名とパスワードだが、簡単に解析できてしまう。なので、Basic認証を行う際は当該環境がどの程度セキュアなのかを意識して使用する
Digest認証
Basicよりもセキュア。
WSSE認証
キャッシュ用ヘッダ
- Pragma キャッシュを制御する
- Expries キャッシュの有効期限を示す
- Cache-contorl
これらの使い分け
- キャッシュをさせない場合は、PragmaとCacheControlのnocacheを同時に指定する
- キャッシュの有効期限が明確に決まっている場合は、Expiresを指定する
- キャッシュの有効期限を相対的に指定したい場合は、CacheControlのmaxageで相対時間を指定する
ヘッダを活用するにあたり
ヘッダはメソッドやステータスコードと組み合わせて、認証やキャッシュなどのHTTPの重要な機能を実現します。電子メールや言語タグ、文字エンコーディングなど、ほかの標準を積極的に活用しているのもHTTPヘッダの特徴です。したがってHTTPヘッダを学ぶためには多様な知識が必要になります。電子メールや文字エンコーディングはWebよりもさらに長い歴史を持っているため、バッドノウハウのかたまりです。HTTPヘッダを上手に使うためには、これらの歴史と実際のサーバやブラウザの実装を調査する能力が必要となります。
HTML(第10章)
HTMLはHypertextMarkupLanguageの略です。マークアップ言語(MarkupLanguage)とは、タグ(Tag)で文書の構造を表現するコンピュータ言語です。マークアップ言語でマークアップした構造を持った文書のことを「構造化文書」(StructuredDocument)と呼びます。
xmlの木構造
HTMLを理解するにはメタ言語であるxmlの理解が必須
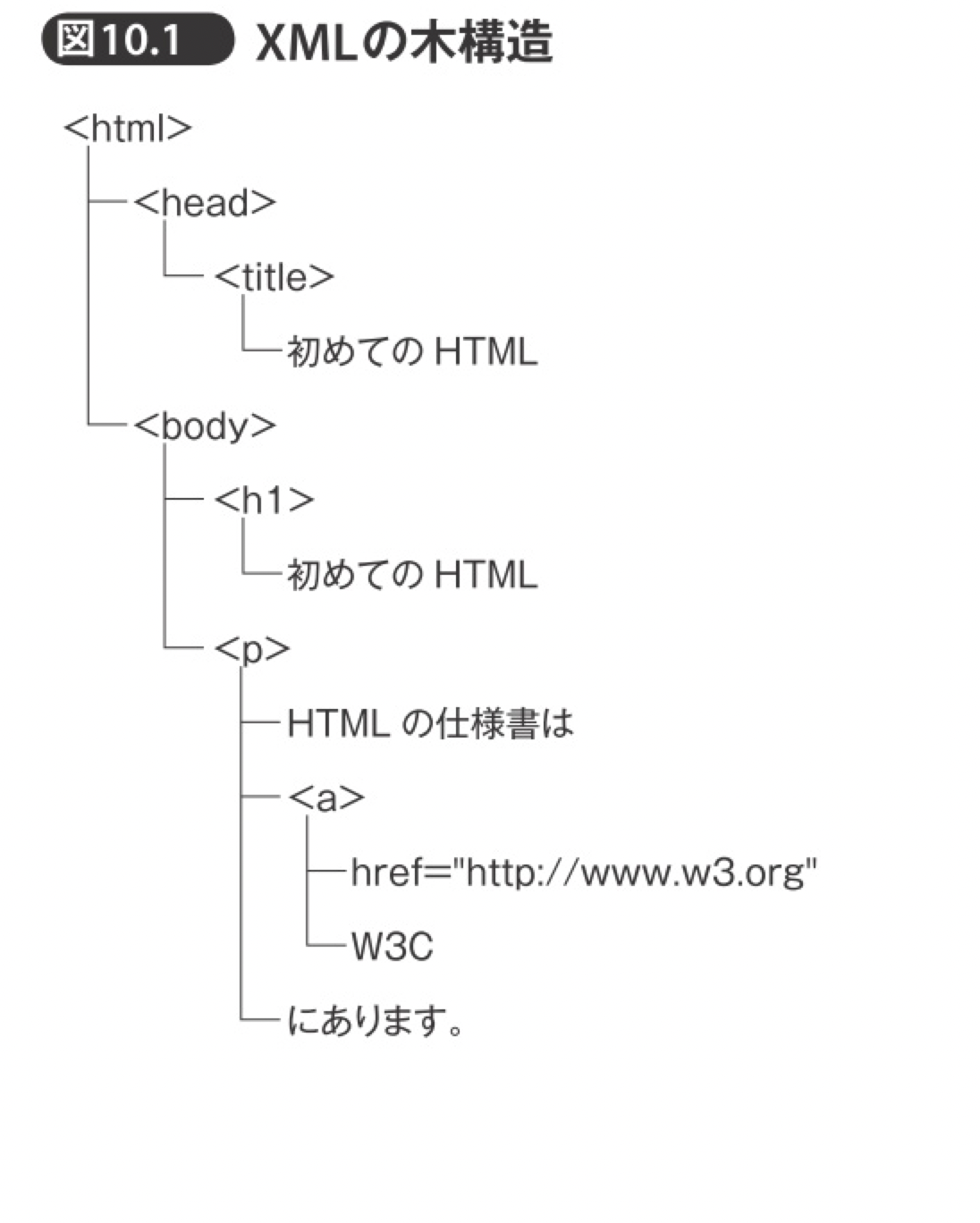
htmlの構成要素
ヘッダ

ボディ

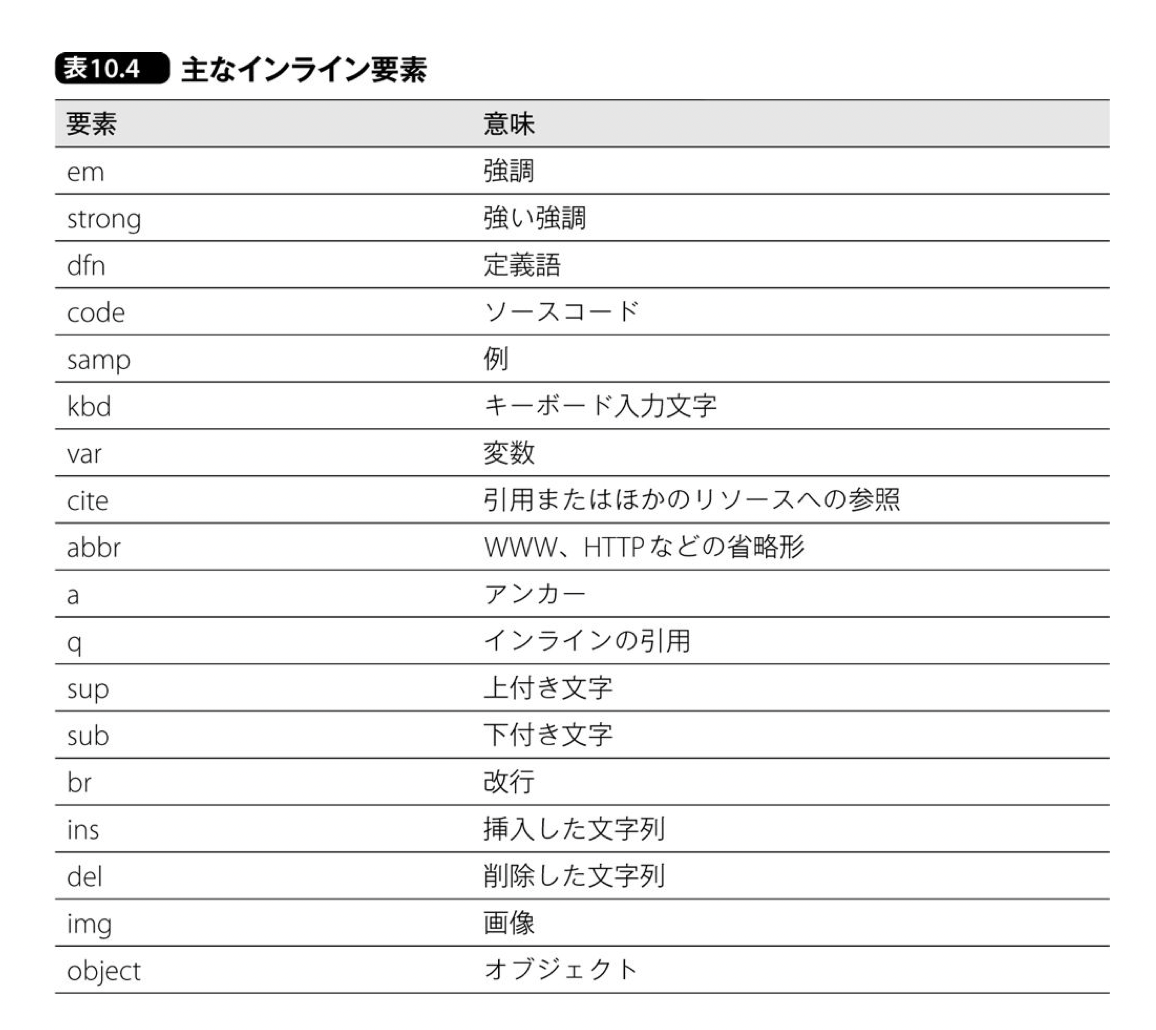
- インライン要素とはブロックレベル要素の中に入る要素
オブジェクトの埋め込み
HTMLはハイパーメディアですので、テキストだけではなく画像や映像なども埋め込めます。歴史的経緯により、一般的には画像の埋め込みには要素を、それ以外のオブジェクトの埋め込みには要素を利用します
LINK
WEBが想定しているリンク

microformats(第11章)
ちょいむずいのか?
Atom(第12章)
AtomSyndicationFormatは、RFC4287が規定するXMLフォーマットです。通常はAtomと略して呼ばれます。Atomの目的の一つには、RSSの仕様(0.91、1.0、2.0)が乱立し混乱をきたしたため、拡張性のあるフィードの標準フォーマットを策定しようとしたことがあります。RSSは主にブログの新着情報を伝えるフィードの目的で利用されていましたが、Atomはブログだけでなく検索エンジンや写真管理などさまざまなWebサービスのWebAPIとして利用できます。
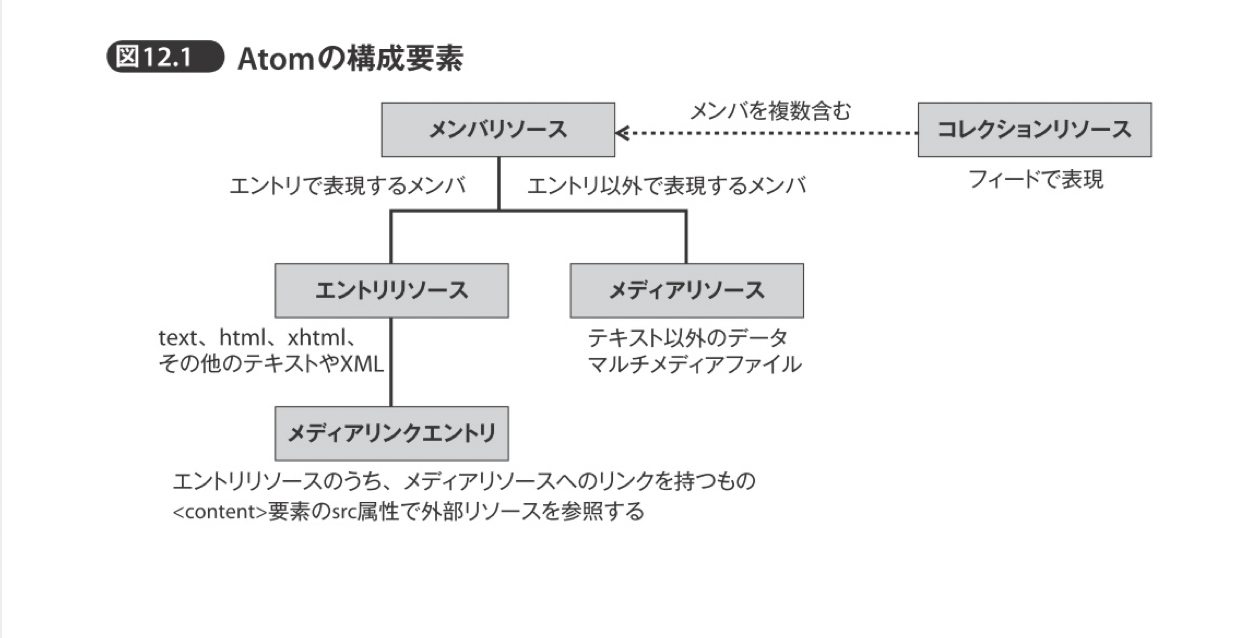
- メンバリソース 最小単位 ブログなら1つ1つの記事を指す
- メディアリソース 画像などテキストでは表現できないリソース
- コレクションリソース 複数のメンバリソース 階層化不可
Atomを活用する
Atomはタイトル、著者、更新日時といった基本的なメタデータを備えたリソース表現のためのフォーマットです。タイトル、著者、更新日時のメタデータ3点セットは、ブログ以外のコンテンツでも有用なことが多いでしょう。Atomは多様なアプリケーション用の拡張が用意されたフォーマットでもあります。この拡張性により、Atomはブログ以外の用途にも用いられています。たとえばポッドキャストによる音楽配信や、写真管理、検索エンジンなどです。これらのアプリケーションはXMLの名前空間のしくみを使ってAtomに独自の要素を追加しています。また、Atomは次章で解説するAtomPubと組み合わせることで、リソースの表現だけでなくHTTPを活用した操作もできるようになる
Atom Publishing Protocol(第13章)
本章ではAtomPublishingProtocolについて解説します。このプロトコルを採用すると、ブラウザ以外のWebクライアントからブログを投稿したり、システム同士を連携したりといったことが簡単にできるようになります。
AtomPubに向いているWebAPI
- ブログサービスのAPI・検索機能を持つデータベースのAPI
- マルチメディアファイルのリポジトリのAPI・タグを使ったソーシャルサービスのAPI
AtomPubに向いていないWebAPI
- Cometを利用するような、リアルタイム性が重要なAPI
- 映像のストリーム配信など、HTTP以外のプロトコルを必要とするAPI
- データの階層構造が重要なAPI
- 「タイトル」「作者」「更新日時」など、Atomフォーマットが用意するメタデータが不要なAPI
JSON(第14章)
HTML、microformats、AtomというXML系のリソース表現を解説してきました。最後に紹介するフォーマットは、より軽量なデータ表現形式であるJSONです。JSONはXMLのように文書をマークアップすることには向いていませんが、ハッシュや配列といったプログラミング言語から扱いやすいデータ構造を記述できることが特徴です。
JSONで用意されている型
- オブジェクト
- 配列
- 文字列
- 数値
- ブーリアン 小文字
- null 小文字
オブジェクト
{
"name": {
"first": "Yohei",
"last": "Yamamoto"
},
"blog": "http://yoheiy.blogspot.com",
"age": 34,
"interests": [
"Web",
"XML",
"REST"
]
}