概要
データエンジニアやデータ整備をやっている方はデータの不整合見るときにいろいろなツールを使って調べたり、SQLで叩いて調べたりすると思います。
最近自分もそのようなことをすることが多いです。特に新しいデータの連携とかが始まった時などはデータの内容を見ることが多いです。そんな時にpandas_profilingは役に立ちます。
インストール方法
pip install pandas-profiling[notebook]
使い方
import pandas_profiling as pdp
from sklearn.datasets import load_boston
data = load_boston()
df = pd.DataFrame(data.data, columns=data.feature_names)
profile = pdp.ProfileReport(df, {'correlations': None})
profile.to_file("profile.html")
私は単純にデータの分布が知りたいことが多いので相関の計算などはしないようにオプションを追加しています。
また他の方への共有などをするためにhtmlに出力しています。
結果
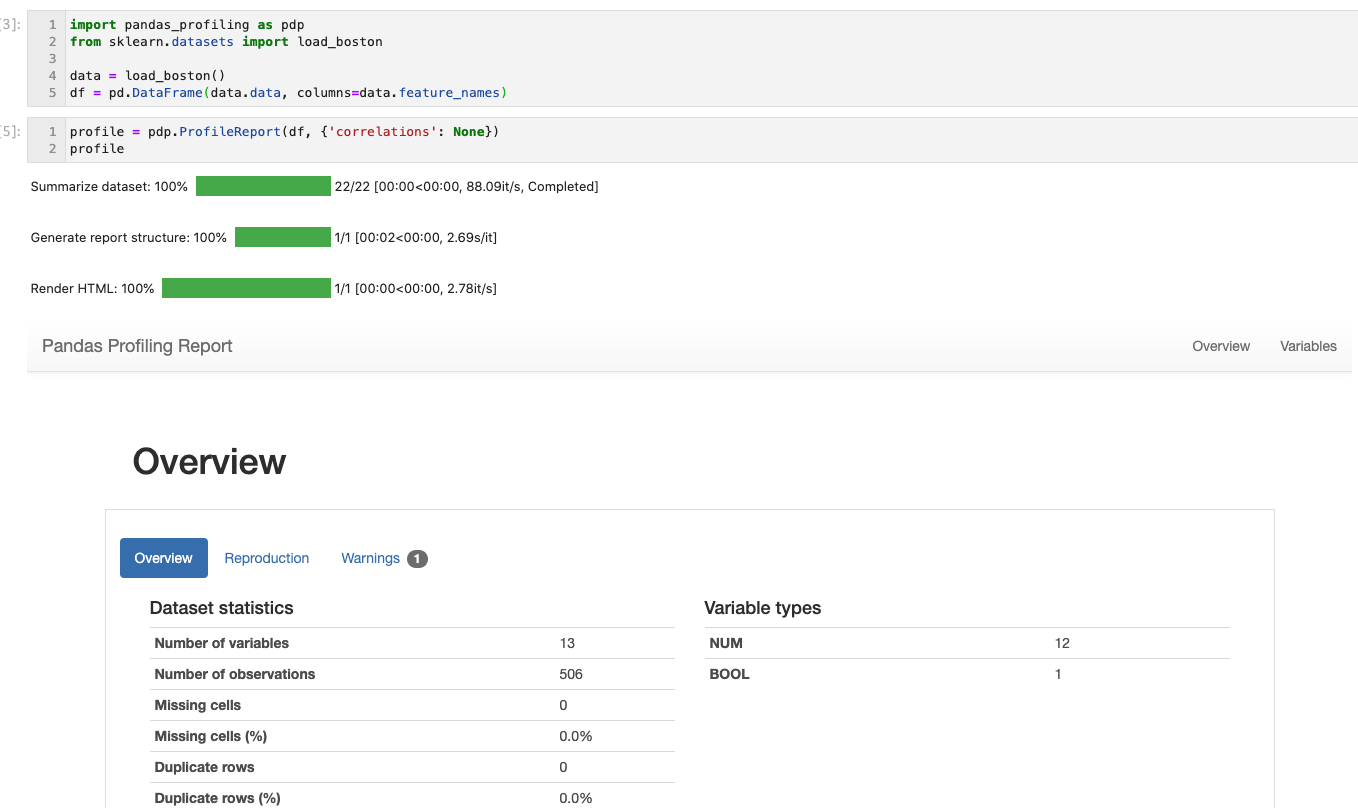
Jupyter notebook上で実行すると下図のようにプロセスバーが表示され、処理されている状態がわかります。
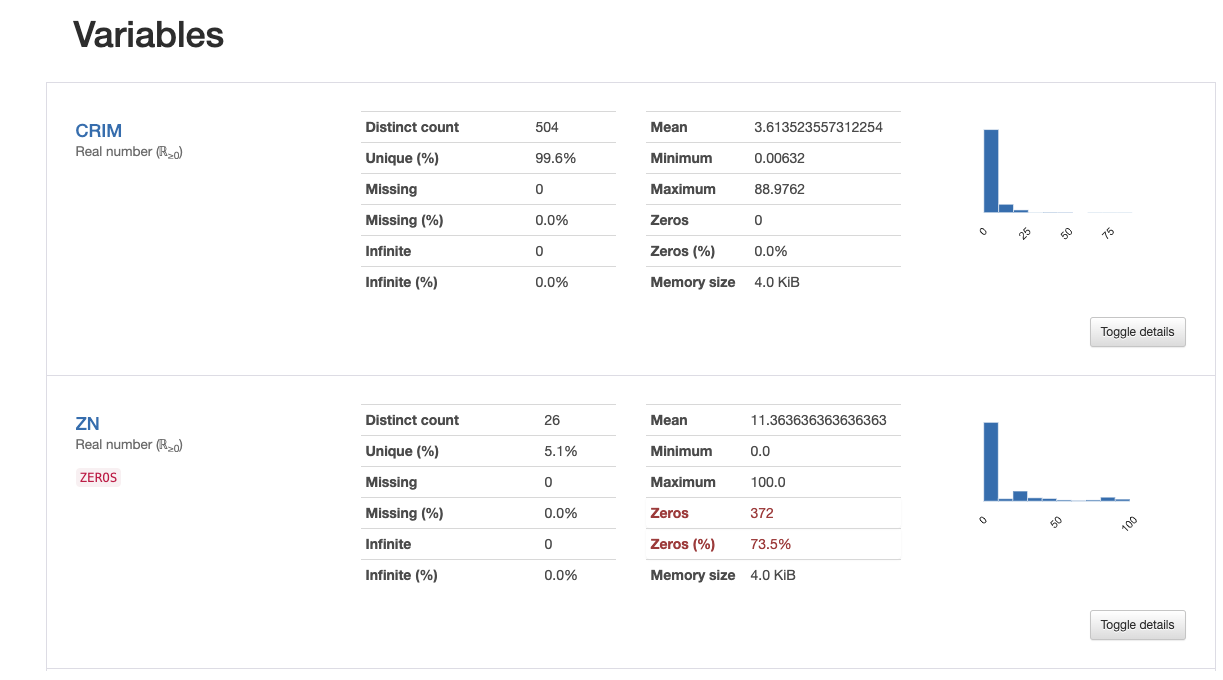
各項目のデータの状態がわかります。特に私が気にかけているのは欠損値で、欠損値の数や割合が表示されるのでとても便利です。