SEO対策はタグの中身が大切らしい
SEO対策は色々あるけど title h1 h2 あたりに何を入れるかが大切らしい。。。
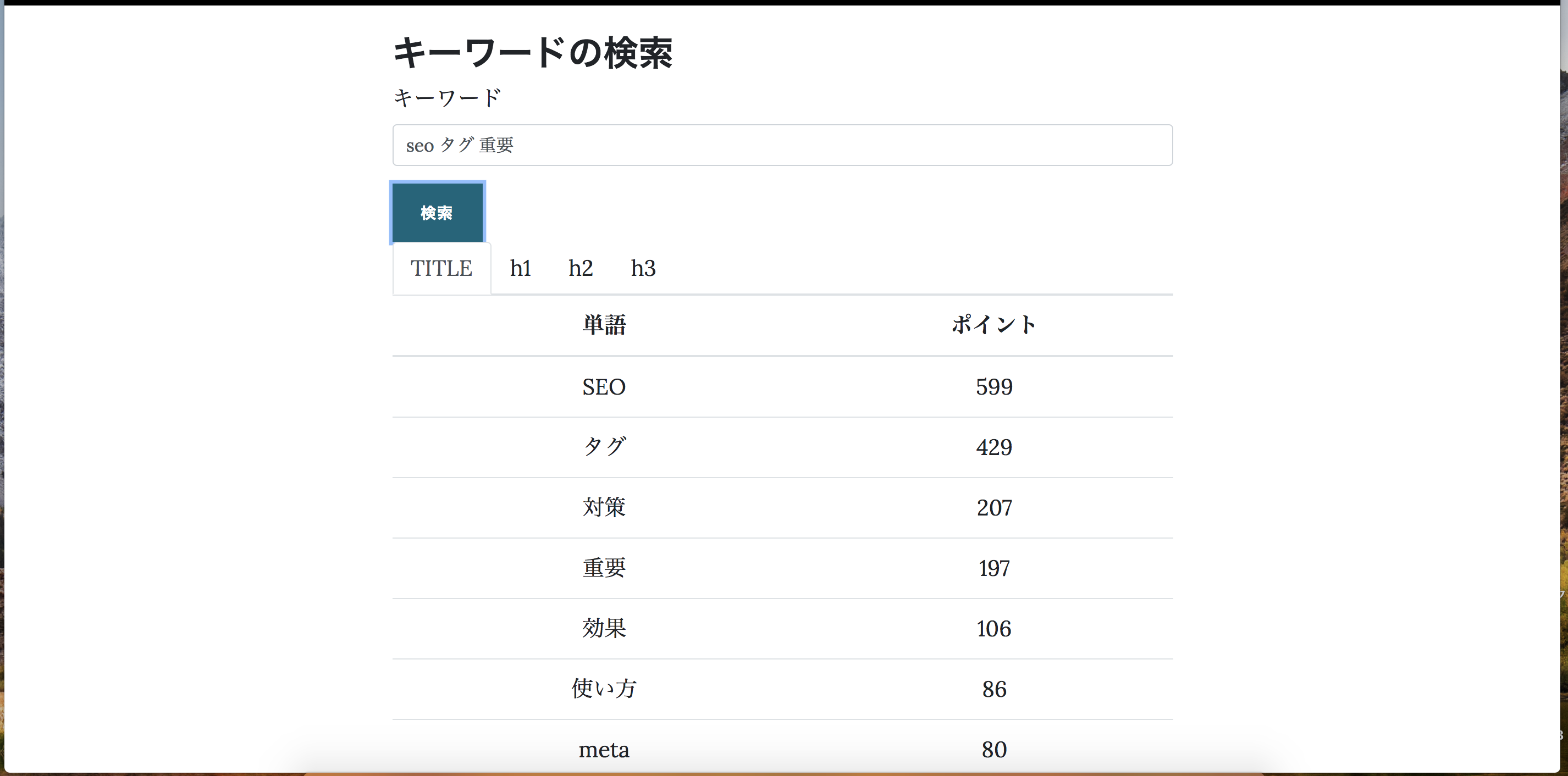
ということで上位ページクローリングしてみました!
できたもの
- キーワードに関して各タグでどの単語がよく使われているかをランキング化
- ランキング方法は上位ページに出てきた単語ほど重みをつけて集計
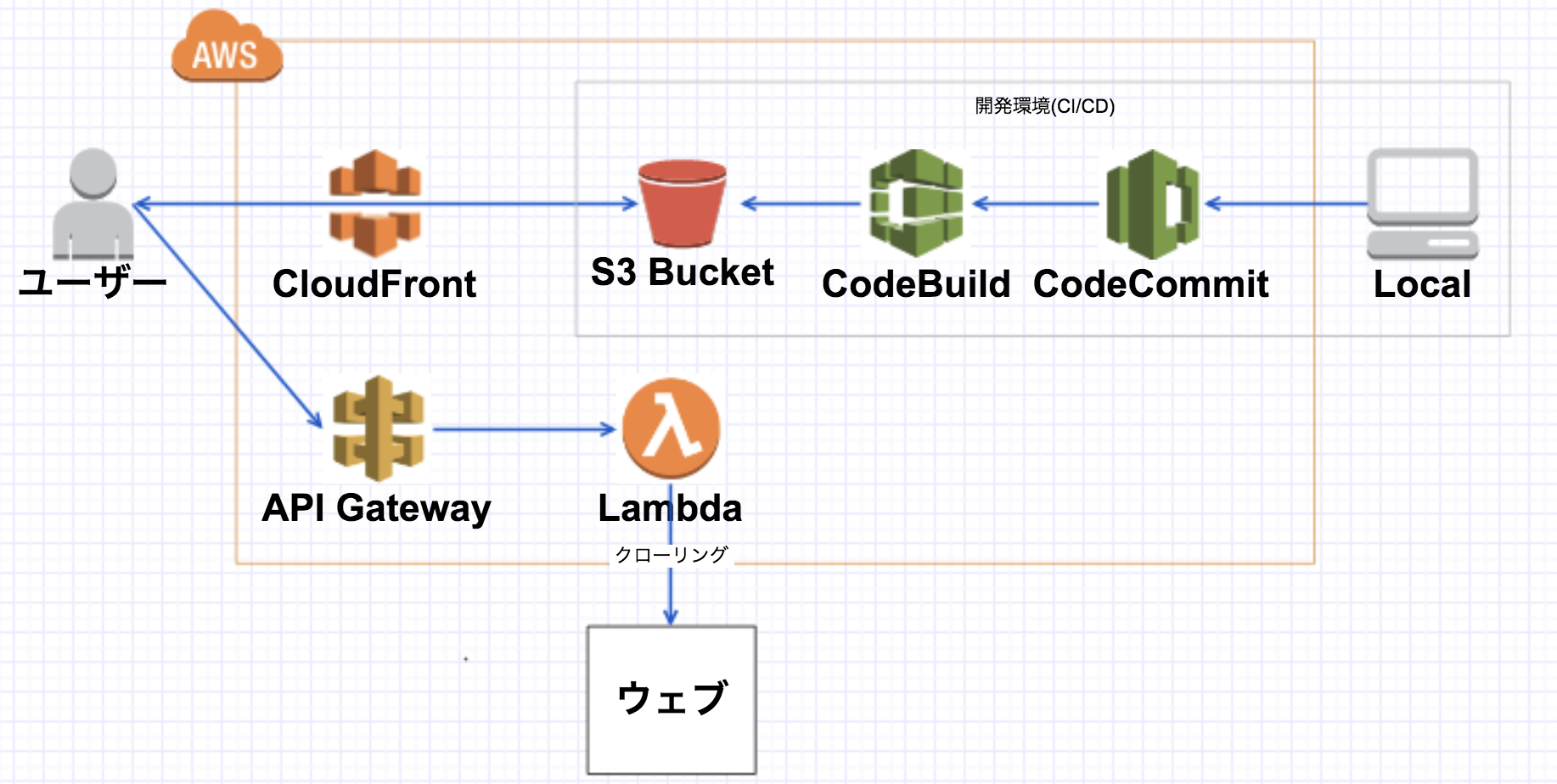
最初の設計
- CI/CDを作って開発を早くする
- S3にhtml直置きで簡単にwebサイト化
-
api gateway経由でAWS lambdaを読んでサクッと結果を返す
クローリングlambdaの中身
クローリングは以下のpythonコードを参考にさせていただきました!
また単語を取りたいので以下のサイトを参考に janome を使用
Python初心者が1時間以内にjanomeで形態素解析できた方法
結果api gateway時間短すぎて死亡
そもそもapiってそんなに待つものじゃない。。。
- クローリング+形態素分析にかかる時間10分なので今のlambdaなら大丈夫
- しかし
api gatewayは30秒ぐらいしか待ってくれない=>死亡
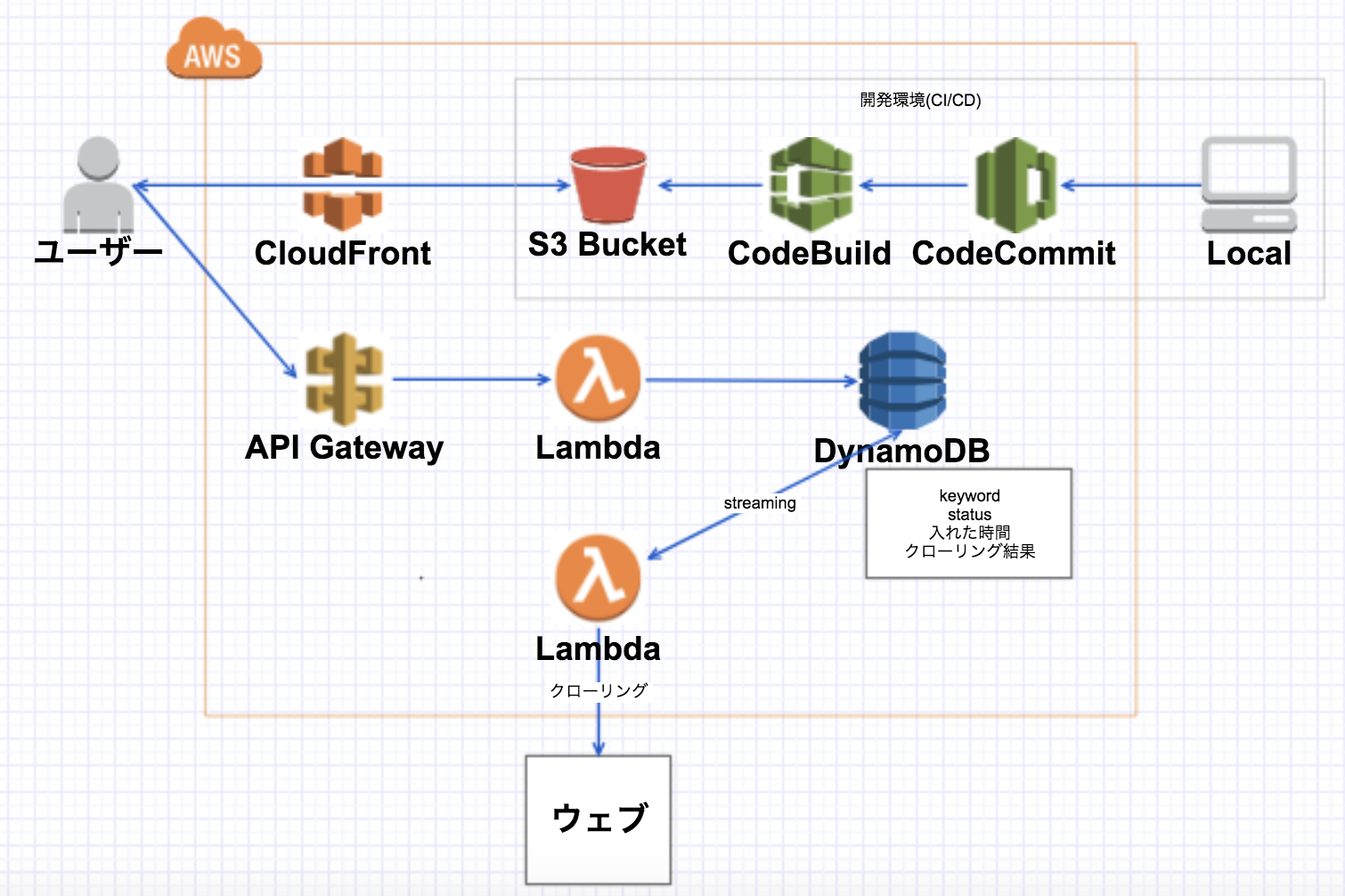
次の設計図
-
DynamoDBにキーワードを格納するキーワード入れるlambdaを作成 - 格納されたらイベント発火で
クローリングlambdaを起動 -
クローリングlambdaは結果をDynamoDBに格納 - 再度同じキーワードでみに行くと結果が見れる(ある程度時間が経ったら更新)
キーワード入れるlambdaの中身
- まずはじめに1時間以内に更新された結果がないか確認
- 結果がない場合はkeywordを新規レコードとして追加
get_result_or_put_keyword.py
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table({{TABLE_NAME}}) # DynamoDBのテーブル名
result = table.scan(
FilterExpression=Key('keyword').eq(search_url_keyword)
)["Items"]
if len(result) == 1:
if "scantime" in result[0].keys():
# 1時間以内に更新されたデータなら使う
if datetime.now() - datetime.strptime(result[0]["scantime"], '%Y-%m-%d %H:%M:%S') < timedelta(hours=1):
if "result" in result[0].keys():
return {
'statusCode': 200,
'body': result[0]['result']
}
# 使える結果がない場合はdynamodbにkeywordのレコードを入れる
param = {
"keyword": search_url_keyword,
"scantime": now.strftime("%Y-%m-%d %H:%M:%S"),
"status": 0
}
# DynamoDBへのPut処理実行
table.put_item(
Item=param
)
print("now searching ...")
return {
'statusCode': 200,
'body': "now searching ..."
}
DynamoDBから並列でlambdaを呼び出せず死亡
- 一つだとうまく行くが同じタイミングでいくつかキーワードを入れると処理しきれない
- streaming処理的に
並列lambdaはNGな感じなのかもしれない。。。
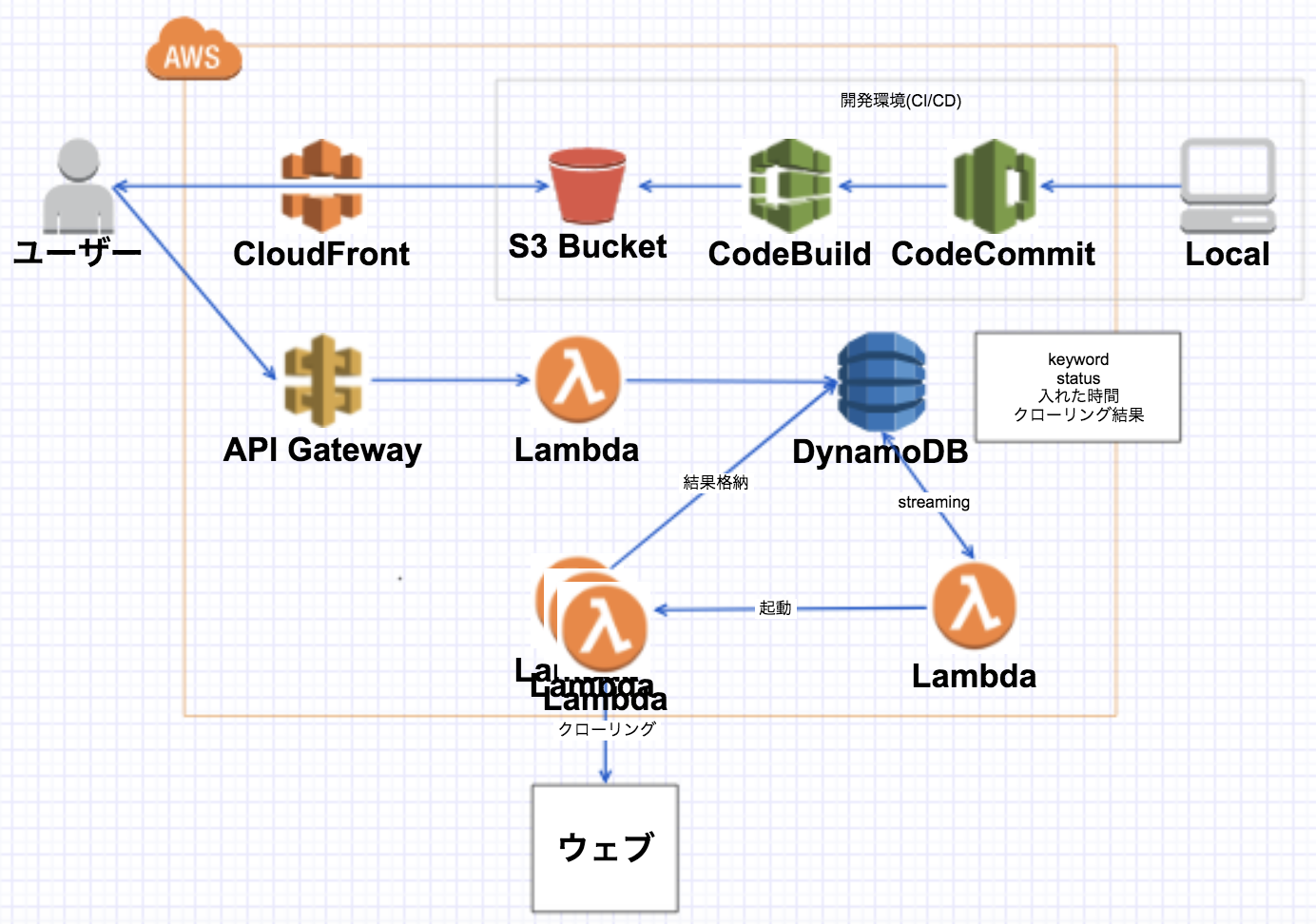
最終設計図
- streamingで呼び出される
起動lambdaを追加 - 一度に大量に来てもさばけるようになった!
肝心のSEO対策は進まず...
最初はクローリングしてSEOに活かそうとしていたのにいつの間にかハマっていたパターン。。。
肝心のSEO対策は進んでいないのでこれからやろうと思います笑
今回SEO対策を考えるきっかけとなったサイト
私もネイル
もよろしくおねがいします!