背景
昨今DXやRPAという言葉も定着してきました。
それでも分野や業務、環境によっては今もなお「エクセルにデータを貼って手動で数表を作る業務」というのは発生していそうです。
そして、、、手動で運用している以上、事故が起きることがありそうです。
「表のD38のセルだけに、、、計算式入ってなくて、、、毎回同じ値が出てました?」
「表の、、、3列目だけ、、、計算式の修正が反映されてませんでした?」
海を背景に、おまえ何やってんだよ、、、と問いかけたい気持ちになりかけます。
しかし、それは違います。
人はミスをするのです。
計算式ミスを救いたい(本ポエムの概要)
近年Google スプレッドシートが登場することが多くなっているように感じます。
履歴が残ったり共同編集が行えたりと様々なストレスがなくなり素晴らしい世界になっています。
しかし、冒頭に書いたような事故はスプレッドシートでも当然発生します。
少し整頓すると、以下のような課題点となるかと思います。
- 作成する表、変更する表の一部分だけ計算式が適用されていないことに気付けない
- 計算式の対象のセルが増えるとミスの確率が跳ね上がる
- クロスチェックしようにもつらい(体制は敷くが形骸化しがち)
つまり集計の手段が「気合と根性」になっており、そのミスをカバーする手段も「気合と根性」となってしまっているケースです。
こうした話に対する解決手段として、Google スプレッドシートの「QUERY関数」を中心として整備/設計すれば良い、ということを考え、運用に乗せてみました。
結論、QUERY関数を使えば、
- 表の列のすべてのセルで同じ計算がされていることが保証される
- レビュアーの負担軽減により品質が向上する
- 変更にも強くなり一部のセルへの計算式のミスや適用漏れがなくなる
- 誤って手入力されるような事故がなくなる
- 数値が直書きされるとエラーになるためフェールセーフな表になる
- 理解をしていないと修正ができないため、勝手に修正が行えない(良くも悪くも)
ということが達成できます。
QUERY関数を使う場合、使わない場合の比較
実際にやってみましょう
用意したデータ
沖縄に行けない思いが強すぎたため、沖縄離島方面の天気データを用意しました。from 気象庁
※内容を気にせず説明のため集計しているため、集計結果の数値は読む必要ありません
↓こんな項目で
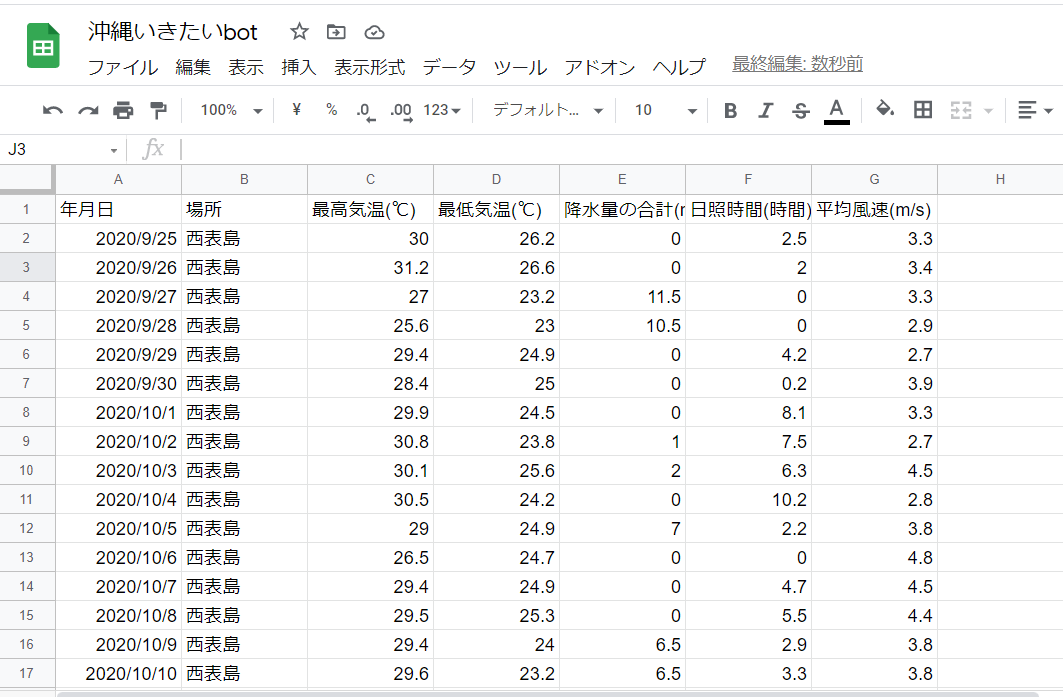
年月日
場所
最高気温(℃)
最低気温(℃)
降水量の合計(mm)
日照時間(時間)
平均風速(m/s)
↓スプレッドシートに、こんな形で張ってみました(Rawに近いデータ)。
さてここから、例えば
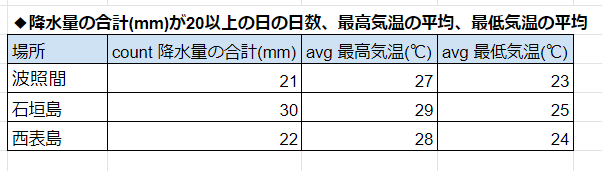
「降水量の合計(mm)が20以上の日の日数、最高気温の平均、最低気温の平均」
という表を作る作業があるとします。
↓こんな表をつくりたい
QUERY関数を使わない場合
おおよそ以下のような形になるんじゃないかと思います(ほかの方法もあるかもしれません)

特定の場所に対して、日数をカウントするために COUNTIFS発動
=countifs(B2:B2000,"波照間",E2:E2000,">20")
特定の場所に対して、特定条件の日のみでの平均を出すためのSUMIFS/COUNTIFS発動
=sumifs(C2:C2000,B2:B2000,"波照間",E2:E2000,">20")/countifs(B2:B2000,"波照間",E2:E2000,">20")
=sumifs(D2:D2000,B2:B2000,"波照間",E2:E2000,">20")/countifs(B2:B2000,"波照間",E2:E2000,">20")
試しに書いてみて少しくらくらしますが、実際こうしたスプレッドシートも世の中にはあるんじゃないでしょうか。
QUERY関数を使う場合
一方、今回推したいQUERY関数の場合、Google Visualization API クエリ言語 を利用し、以下のように書くことが可能です。

=query(A1:G2000,"select B, count(E),avg(C),avg(D) where E >= 20 and (B='西表島' or B='石垣島' or B='波照間') group by B ",1)
※ orの指定が煩雑に見えますが、実際にはマスタ的な定義セルを用意し、例えば I9:I15 の範囲に場所の指定が書かれているとすると、 B MATCHES '^("& JOIN("|",I9:I15)&")$ といった形にすると、in句のようなことができます。
参考記事: (Gスプレッドシート)QUERY関数でのIN及びNOT INの代替手段
淡々と書きましたが
「左上の1セルに入れると、右方向下方向と表のデータがデータを入れてないセルに展開される」
という挙動をしています。
この挙動は、他にはARRAYFORMULA関数なども同様です。何も書いていないはずのセルに数値が入るのです。
えっこわい
少なくとも私はこの挙動をARRAYFORMULAで初めて見たときに、これが闇魔法か、、、と思ったものです。直観的ではないと感じたのです。
しかしながら、これは光魔法だったのです。
フェールセーフ
こわいと思った理由として
「こんなの展開しようとしたセルに何か文字あったらどうするの!!!」
というものがありました。
試しに実際やってみましょう
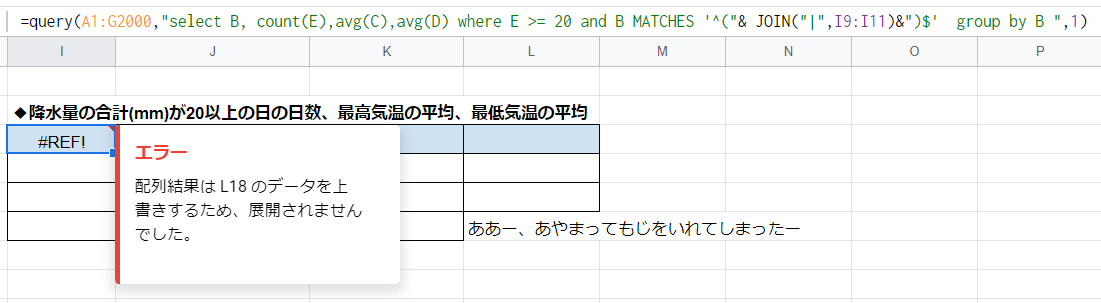
エラーになりました。
私は最初これも「ええーっ、なんかわかりづらい、ミス増えない?」と思ってしまっていました。
逆や。今では反省しています。
わかりやすい例として、従来の計算式バージョンに置き換えて考えてみましょう。
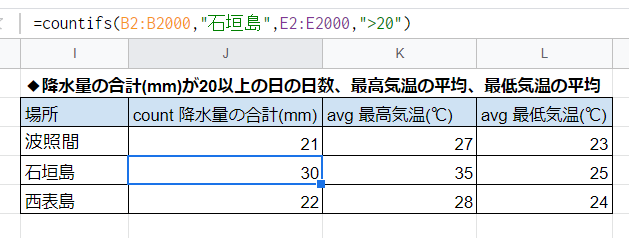
この画像においては、カーソル(計算式)をあてている1つ右の、石垣島のK列が「べた書きで35が入っている」状態です。本当の数値は計算式の計算結果で29です。実際にはこういう浸食のされ方をするケースがあります。
果たしてダブルチェック体制があったとして、こうした浸食に毎回気付けるでしょうか?
ここで、先ほどのエラーは「わかりづらい」のではなく、ただの「フェールセーフ」なのだと気付きました。
変更に対する強さ
こうした集計表というのは使っていけば、変更・改善の要望が出てくるのが自然です。
さて
- ほかの都道府県の観光地も見たいので対象の場所を100個増やしてほしい
- 天気以外も見たいので見る指標=列を3個増やしてほしい
こうした要望が来た場合、どうなるでしょうか。
QUERY関数を使わない場合、COUNTIFS, SUMIFSの式を、、、え、どうしよう、一括変換する?など、手作業で全部1つずつ入れていく訳にもいかないので、ぷちマイグレーション計画みたいな感じになると思います。また、出来たとしてもそれら増えた分のデータがすべて正しいかどうかの検証も骨が折れます。
QUERY関数を使う場合、select の対象を増やしたりするだけの変更で拡張が可能となります。これは表自体の定義を1セルで行える、ということでもあり、一度知ると戻れない魅力があります。実際QUERY関数にも限界がありますが、むしろQUERY関数で表現できる範囲に抑える、そこを超える場合はRawに近いデータセット側を変える、といった考え方にもなってきます。
クロスチェック(レビュー)に対する強さ
今回の例ですと天気ですが、実際には業務上の重要な指標が表に入るケースが多いかと思います。
QUERY関数を使わない場合の計算式について、3行3列の9セル分であればクロスチェックは可能かもしれません。しかし、これが100行5列、500セル分でもチェックはできるでしょうか?その規模の表が5つあったらどうでしょうか?
「1日かければ可能!」という説もあるかもしれません。年1回の報告なら良いかもしれません。
しかし、頻度によっては別の手段を考える必要もありそうです。
QUERY関数を使った場合、1つの表につき1つのセルのみをチェックすれば良い、ということになります。
よって「この表をチェックしてください!クエリはこれです!」という形で各種コミュニケーションツールでレビューがやり取り可能です。Gitで管理してもよいかもしれません。
そう、QUERY関数は集計表をコード化しているとも言えるかもしれません。
実際にこの運用をやるのにあたって構築したもの
前述のとおり実際に運用に乗せています。この辺の記事でやっていることの延長で実現をしています。
- BigQueryへ「ある程度集計に便利だが集計しすぎない」=データマートを出力するクエリを用意
- AWS Lambda経由でBigQueryへ実行
- 結果をgspreadでスプレッドシートに出力
- QUERY関数で集計
といった流れです。
BigQueryやAthenaなど、データレイクに近いデータをいったんデータマートに近い状態でスプレッドシートに作り、あとは柔軟に数表を作っていく、というテンプレートで運用しています。
まとめ:QUERY関数の良い点
- 表の列のすべてが同じ計算がされていることが保証される
- フェールセーフな運用ができる
- 表の変更にも強い
- クロスチェック(レビュー)も簡単になる
⇒QUERY関数を使うと計算式ミスが救われる!!!
余談:QUERY関数の導入のすすめ
もしも、すでに計算式フェスティバルのような数表がある場合、ガラッと変更するのではなく、まずは全く同じ形の表をQUERY関数バージョンでも作成し、それらを=ifなどで検証するシートを作成するとよいと思います。
別アプローチで同じアウトプットを作る、ということ自体が品質を高めるので、二度手間では決してなく、品質改善となるはずです。
雑感
いろいろ書いたのですが、エンジニア観点だとSUMIFSやCOUNTIFSといった関数を使うことは少ないとも思っています。私はそれらを最終手段としたいです。
と思っていたところで知ったのがQUERY関数でした。
さらにそもそも論としては、定型のデータの集計などはTableau Online/Server、GoogleデータポータルなどをはじめとしたBIツールでダッシュボードとして構築するのが現状ではゴールにはなるかと思います(実際そうしたアプローチも多いです)。
、、、ではあるのですが、この手の業務は部署を横断したり、時には会社組織を横断したりすることも多いです。BIツール自体がそこに存在していたとしても、実際の導入にあたっては現場1メンバーではアンコントローラブルな要素が多かったりします。そうすると個々人の取り組みとしては「スプレッドシートで共有」という手段がコントローラブルな範囲として落ち着くことが多いように感じています。そして業務レベルのことをやろうとすると、どんどん計算式が複雑になり、、、という悪い状況が起きます。
そんな悪い状況を打開する一助になれば、と思ったので、記事にもまとめてみました。