やったこと
掲題の通りではあるのですが、1年以上ElastiCacheを運用してきて初めて遭遇したのと、実際どういう操作になったり、どういう挙動になるのかが分からなかったので、次来た時のメモとして残します。また、作業を予定しているが全貌を掴めていない方がいらっしゃった場合の一助になれば幸いです。利用クラスターエンジンはRedisです。
注意点
今回あくまでRedisの話でしてMemcachedの場合だったりすると全く異なる可能性がありますし、Redisのバージョンや設定によっては挙動が変わり得ると考えています。私が見ている範囲で安全に配慮して作業した記録、というだけですので、実際の更新にリスクがある場合は都度サポートに問い合わせるなどの対応を強く推奨致します。
結論
・Redisは数秒繋がらなくなる
・Redisのデータは消失しない
・リハーサルはしましょう
ご案内が来ます
メールで案内が届きます。
今回の更新がどういったものか、などは このあたり のドキュメントを併せて確認するとよさそうです。
どういう手順で更新するのか調べる
様子
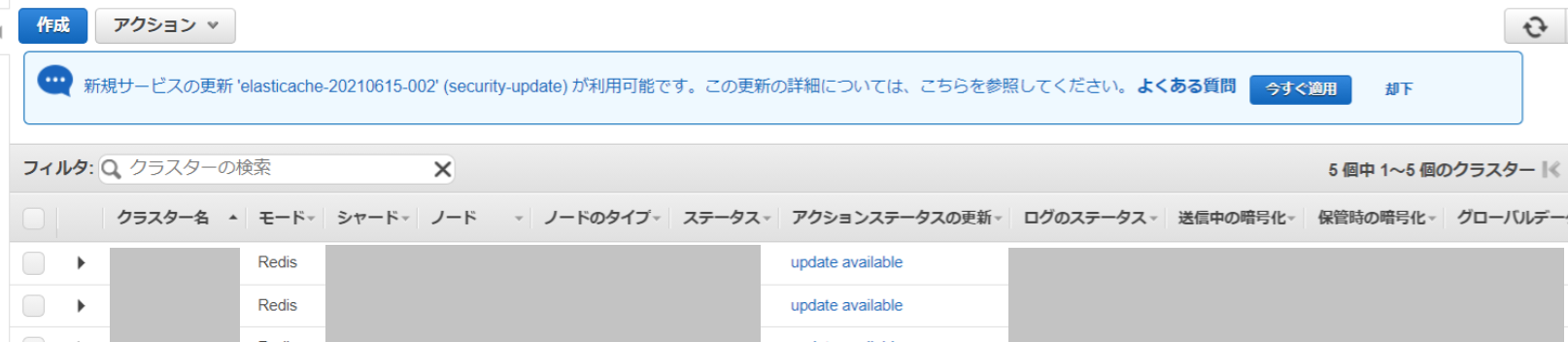
コンソール画面を開くと親切な案内が来ています。
おおーなるほど、と思う一方で、これを見て私は**「押したら確認画面なしで全クラスタアップデート走らんよな???」**と心配してしまう人類なので、いろいろ見てゆきます。
解決策
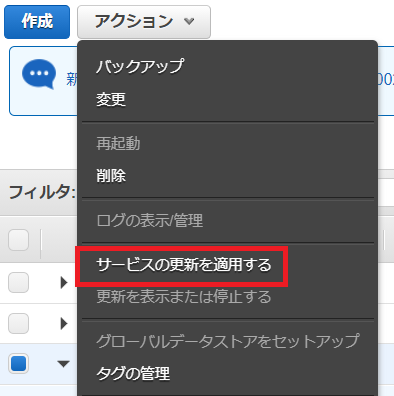
クラスターをチェックし、アクションを見ると「サービスの更新を適用する」という項目があるので、こちらから個別対応ができそうです。よかった。
影響範囲を調べる
先ほどと同じく、このあたり のドキュメントを見ます。
先ほどの更新案内に関しては、判断基準となる案内メールが英語で届くので英語版を見たほうがよく、影響範囲などは日本語版を、ただ念のため交互に見たほうが良いと感じました。
Redis クラスターは引き続きトラフィックを処理します。数秒のダウンタイムが予想されます
引き続きトラフィックを処理する、というのが文脈上少しだけ解釈に確信が持てないと感じましたが単に「データは消えないが、一時的に繋がらなくなって、その後すぐ復旧する」と受け取って先に進みます。
開発環境でリハーサルをする
操作方法と影響範囲が分かったものの、実際やってみないと流石に怖すぎます。
というわけで開発環境で実施ました。
まず、Redisのデータが消えないことを確認しました。これは一安心です。
次に、一時的に繋がらなくなる時間帯が出ることを確認できました。これも想定通りではあるのですが、イメージしていたエラーと少し違いました。確認の観点として例えばコネクションをどのように扱っているかなどがあり、アプリケーションの設計次第では挙動チェックは必須かと思います。
また、上記で解釈した通り、適用完了後は普通に接続可能となっていました。これも安心ですね。
どんな感じで適用されていくかもチェック
キャプチャを取り忘れましたが、実行前に「想定される作業時間」みたいな項目が表示されます。私が操作したものは「30分」でした。適用を開始すると「アクションステータスの更新」が「in-progress」になります。ノードに対して1つずつ適用がされてゆき、実際には20分弱で完了しました。
もちろん20分弱落ち続けるわけではなく、この20分弱の流れの中で、数秒繋がらない時間があるという形です。目視ベースだったので具体的にどのプロセス(前半、中盤、後半とか)で何回、というのは把握できておりません。
雑感
上記のような流れでサービス更新(service update)を初めてやってみました。
ちなみに冒頭で書いた「今すぐ適用」ボタンを押すと、ポップアップウインドウが現れ、そこからも更新が可能なようです。その導線から一気にやる、というより残りクラスター数の確認、みたいな感じに有用かもしれません。