Googleのクラウドで機械学習ができる、Google Cloud Machine Learning を実装してみましたが
(2017/4/30現在)公式ドキュメントがあまりにもお粗末なので、まとめようと思います。
ただ、Google Cloud Machine Learningは現状ベータ版であり、必ず大きな更新があると予想されます。
適当な予想ですが、10月ぐらいになると、もうこの記事も使い物にならなさそうですね。
流れ
環境構築
・GCPへの登録
・APIの有効化
・ローカルへのインストール
ローカルでの実行
・ログイン
・バケットの作成
・ローカルでの訓練
・クラウドでの訓練
・バージョンの指定
・テストデータを投げる
公式ドキュメントにはいくつものトラップがあります。
お気をつけ下さい。![]()
流れは、以下の2つのサイトを参考にしており、以下のサイトでも十分わかりやすいと思います。
しかし、トラップがいくつかありますので、比較して確認してください。
Google Cloud Machine Learning : 入門編 (1)
機械学習最前線!Cloud Machine Learning を始めてみた!
環境構築
GCPへの登録
とりあえず、登録してみてください。
https://cloud.google.com/
クレジットの登録が必須ですが、トライアル期間で12ヶ月有効な$300もらえます。
1年間は$300から従量課金で減っていきます。
私自身、クラウドで計算させるほど大きなデータを扱わないのでいつもローカルで実行していますが690分使って625円って安すぎますね![]()
(※参考画像は私の料金ですが、多分来月になるとストレージの使用量とかも課金されます)
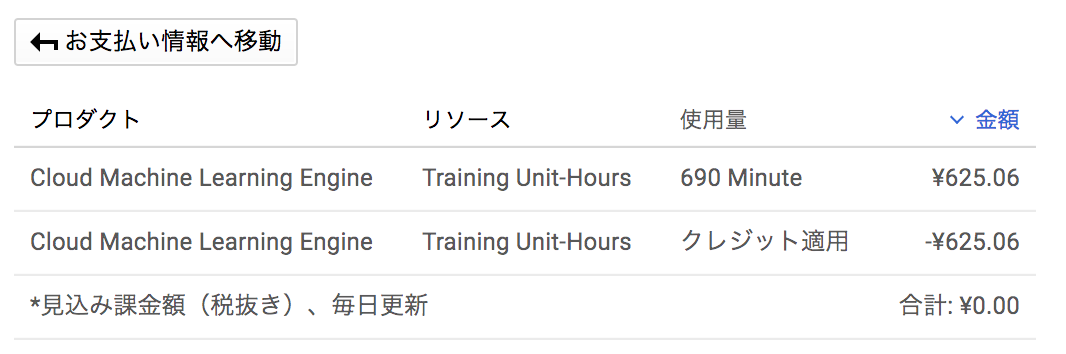
料金ですが、各サービスごとにかかります。(ストレージの使用量や機械学習の回数,時間など)
上記の画像では、Cloud Machine Learning Engineの課金が示されています。
他のサービスの料金は下記のURLから確認できますが、一旦は一ヶ月使ってみて、どれにどれくらいかかったのか確認して、余計なものは省いたりする検討をオススメします。
料金リスト
APIの有効化
このAPIが有効になっていることで、クラウドでの機械学習ができるようなります。
・Cloud Machine Learning API
・Compute Engine API
・Cloud Logging API
・Cloud Storage API
・Cloud Storage JSON API
・BigQuery API
ローカルへのインストール
基本的な流れは以下の公式ドキュメント通りです。
Google Cloud プロジェクトの設定
1~6までのは、そのまま実行して大丈夫です。
7が第一のトラップです。
# 最新のtensorflowのバージョンは1.0系です。
# 以下のコマンドですと、0.11系がインストールされしまうため、書き換えましょう。
pip install --upgrade --ignore-installed setuptools \
https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-0.11.0rc0-py2-none-any.whl
# ↓これを実行する
pip install --upgrade --ignore-installed setuptools \
https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.0.0rc0-py2-none-any.whl
何が酷いって、クラウドで0.11系のtensorflowが実行できません。
公式ドキュメント通りにインストールして、実行できないなんてあるん・・・![]()
8~13は、そのまま実行して大丈夫だと思います。
# これを実行して、Success! Your environment is configured correctly.と表示されたら成功です。
curl https://raw.githubusercontent.com/GoogleCloudPlatform/cloudml-samples/master/tools/check_environment.py | python
ローカルでの実行
ログイン
とりあえず、始める前にこれを実行しておくと良いでしょう。
# 実行場所に移動
cd ~/google-cloud-ml/samples/mnist/deployable/
# ログイン(アップデートされたら出来なくなったみたいです、このコマンドは実行しなくても出来るような気がします)
gcloud beta ml init-project
バケットの作成
バケットは最初しか作りません。
今後は、このバケットで学習結果等データのアップが行われます
# プロジェクト名を取得します。
PROJECT_ID=$(gcloud config list project --format "value(core.project)")
# バケット名を作成します。(「プロジェクト名」 + 「-ml」)
BUCKET_NAME=${PROJECT_ID}-ml
# 新しいバケットを作成します。
gsutil mb -l us-central1 gs://$BUCKET_NAME
ローカルでの訓練
それではチュートリアルを実行していきましょう。
(余談ですが、サンプルで実行する手書き文字認識のコードは、チュートリアルとして理解するにはあまりにも難しいと思います。今回の目的はクラウドでの実行、保存、テストなのでコードの中身は見ない方が良いと思います)
すぐにクラウドで実行する事も出来ますが、毎回クラウドで実行してエラーになってしまっては時間がかかり過ぎてしまうので、まずはローカルでコードが実行できるのか確認します。
実行後に、saved_modelというフォルダが完成していましたら、成功です。
# 場所は基本ここになります
cd ~/google-cloud-ml/samples/mnist/deployable/
# ローカルでのテスト
python -m trainer.task
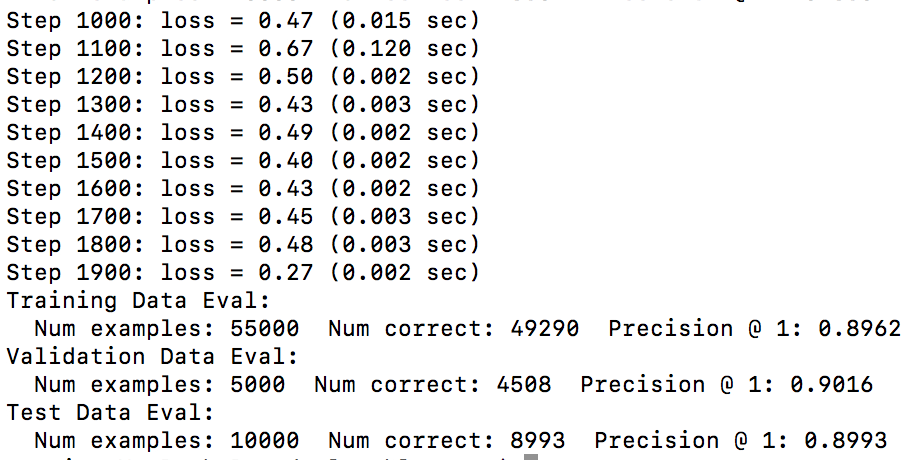
# 以下のディレクトリに新しく、saved_modelというフォルダが完成していると思います。
# 既にある場合は、「もうあるよ」みたいなエラーが出ます。フォルダを消して再実行しましょう。
cd ~/google-cloud-ml/samples/mnist/deployable/data

クラウドでの実行
いよいよ、クラウドで実行します。
# ジョブの名前を設定します。(以下はジョブ名の一例です。)
JOB_NAME=mnist_deployable_${USER}_$(date +%Y%m%d_%H%M%S)
# プロジェクト名を取得します。
PROJECT_ID=`gcloud config list project --format "value(core.project)"`
# Cloud Storageのバケットのアドレスを設定します。(「プロジェクト名」+「-ml」)
TRAIN_BUCKET=gs://${PROJECT_ID}-ml
# トレーニングデータを出力するパスを設定します。
TRAIN_PATH=${TRAIN_BUCKET}/${JOB_NAME}
# 過去のトレーニングで出力したファイルを削除します。
gsutil rm -rf ${TRAIN_PATH}
# クラウドに送信
gcloud ml-engine jobs submit training ${JOB_NAME} --module-name=trainer.task --package-path=trainer --staging-bucket="${TRAIN_BUCKET}" --region=us-central1 -- --train_dir="${TRAIN_PATH}/train" --model_dir="${TRAIN_PATH}/model"
こんな感じで、成功します。
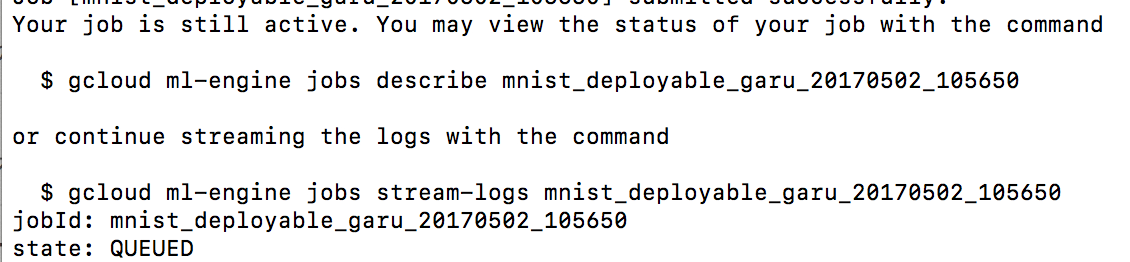
進行中のステータスを確認するコマンドが2つ現れます、上のコマンドを実行しましょう。
他にも、色々出力されますが、stateで確認できます。
これで成功です。
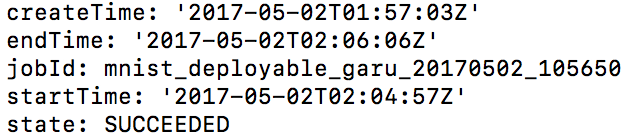
stateの流れは、私個人が知っている範囲では
QUEUE → PREPARING → RUNNING → SUCCEEDED
だったような気がします。
2時間ぐらい間が空くと、PREPATINGの時間が長くなりますが、原因はよくわかりません。
クラウドの方でも、確認してみましょう。
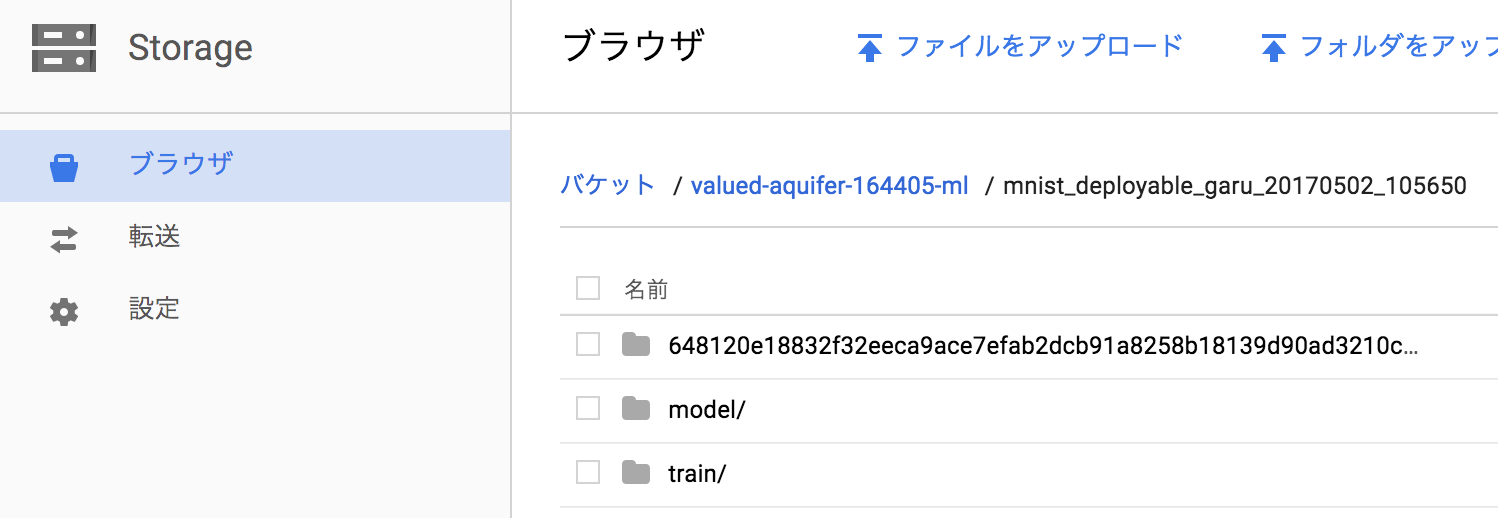
Google Cloud Pratformにアクセスして、Strageにアクセスしてください。
バケット / プロジェクト名 / トレーニングのID になっております。
model/というフォルダが完成していましたら、成功です。
クラウド実行に関するトラップ
ここでトラップを紹介しますが、実は知らなくても上記のように実行だけは可能です。
実は、公式ドキュメントではクラウドでの実行には2通り紹介されています。
予測クイックスタート
TensorFlow モデルを Cloud ML 上で処理する仕組み。
トレーニング クイックスタート
Cloud ML 上で TensorFlow モデルのトレーニング行う仕組み。分散トレーニングとハイパーパラメータ調整を含みます。
一見同じですよね。
実はどちらも、クラウドで機械学習の実行は出来ます。
ですが、トレーニングクイックスタートでは学習結果をモデル保存用のファイルが保存されず、予測クイックスタートではモデル保存用のファイルが保存されます。
テストを行うには、保存したモデル保存用のファイルにバージョンを指定してテストデータを投げる必要があるのでファイルが保存されない場合ですと、バージョンの指定ができずに困る事になります。
実は最初に紹介した、2つのサイトはGoogle Cloud Machine Learning : 入門編 (1)がトレーニングクイックスタートで、機械学習最前線!Cloud Machine Learning を始めてみた!が予測クイックスタートになります。
トレーニングクイックスタートは、色々と実行コマンドが違うので見ないことをオススメします。
バージョン指定
クラウドで保存した学習結果に、テストデータを投げるにはバージョンを指定してモデルにする必要があります。
Google Cloud Pratform側でも、バージョンを指定できますので、上記のサイトを参考にしてみてください。
# モデルの名前を作成
MODEL_NAME=mnist_${USER}_$(date +%Y%m%d_%H%M%S)
# クラウドでモデルを作成
gcloud ml-engine models create ${MODEL_NAME} --regions=us-central1
# 予測用バージョンを作成(意外と時間かかります)
gcloud beta ml-engine models versions create --origin=${TRAIN_PATH}/model/saved_model --model=${MODEL_NAME} v1
成功しました。

モデルのテスト
いよいよ、保存したモデルにテストを行います。
※オンライン予測は(4/30現在)α版で無料提供されており、急に実行できなくなる可能性があるので注意してください。
gcloud beta ml predict --model=${MODEL_NAME} --json-instances=data/predict_sample.tensor.json
こんな感じで、結果が帰ってきます。

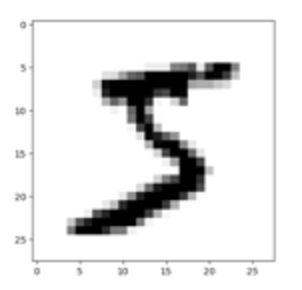
{key:0}の予測結果{prediction:3}が3だと言っています。
下記画像が入力データをピクセル上にプロットしたものですが、5なので不正解ですね。
(確かに3っぽくも見える)
でも、他のテスト結果は正解しています。
他のテストデータのピクセル画像は、下記のサイトで確認してください。
機械学習最前線!Cloud Machine Learning を始めてみた!
ちなみにですが、SCORESは各数字での確率が何%なのかを示しており、その中で一番確率の高い出力を予測結果としてしています。
配列はそれぞれ[0,1,2,3,4,5,6,7,8,9]の順番になっており、全て足すと1になります。(e-05は10^-5になります)
よく見ると、3の確率が55%で5の確率が40%になっていてますね、惜しい。
この結果を見て、人工知能可愛いと思うようになれば、もう一人前です。
最後に次回予告
次回は、公式ドキュメントで紹介されている手書き文字認識のチュートリアル(MNIST)がいかにクソなのか解説しつつ、誰でも簡単にできるニューラルネットワークを説明します。
(MNIST自体は悪くないが、チュートリアルにしてはコードが複雑すぎるということや、別にDeepLearningの説明にはなっていないこと、入力データが確認できないこと等々あると思います。個人の主観によりますが、、、)