0. はじめに
2017/02/18 名古屋マークアップ勉強会 で発表させていただきました。
ありがとうございます。
Web業界で変化しないものは?
変化が速いWeb業界。最新の技術だけでなく「変化しないないもの」の勉強も重要
- HTTP
- Unixコマンド
- HTML
- デザインのセオリー
- 文字コード(⇒これを話します)
目次
- 文字コード概論
- Unicode, UTF-16, UTF-8
- サロゲートペア、BOM
- 文字コードの自動判別
文字コードを学ぶきかっけになればと思います。
参考図書
矢野啓介『プログラマのための文字コード技術入門』(技術評論社,2010)
このスライド内の引用文・図は、特に指定がない場合この本から引用しています。

1. 文字コードの概論
「文字コード」とは?
文字集合を定義し、その集合の各文字に対応するビット組み合わせを一意に定めたものが文字コードです。
たとえば、[A]は1000001、[B]は1000010にするというルール。
符号化文字集合と符号化方式
「文字コード」という言葉は意味が広いので、以降のスライドでは「符号化文字集合」、「符号化文字方式」という言葉を使います。
符号化文字集合の定義
符号化文字集合 (coded character set) ,符号 (code) 文字集合を定め,かつ,その集合内の文字と ビット組合せとを 1 対 1 に関係付ける,あいまいでない規則の集合
※JIS X 0201-1997から引用
- JIS X 0201(ラテン文字と片仮名)
- JIS X 0208(日本語の2バイト文字)
- ISO/IEC 10646(≒Unicode)(世界中の文字)
文字符号化方式の定義
文字符号化方式(もじふごうかほうしき、英: character encoding scheme、CES)とは、符号化文字集合で文字に対応付けた非負整数値を、実際にコンピュータが利用できるデータ列(通常、バイト列)に変換する符号化方式。
※Wikipedia 文字符号化方式から引用
ファイル保存やHTTPで指定する文字コードは「文字符号化方式」
- Shift_JIS
- EUC-JP(Unix系OS)
- ISO-2022-JP(電子メール)
- UTF-8
- UTF-16
符号化文字集合と符号化方式の関係
「規格」と「実装」の関係
| 符号化方式 | JIS X 0201 | JIS X 0208 | Unicode |
|---|---|---|---|
| EUC-JP | ○(片仮名) | ○ | - |
| ISO-2022-JP | ○(ラテン文字) | ○ | - |
| Shift_JIS | ○ | ○ | - |
| UTF-8 | - | - | ○ |
| UTF-16 | - | - | ○ |
文字集合の組み合わせも可能
2. Unicode,UTF-8, UTF-16
Unicodeの前に、まずはASCIIの説明
American Standard Code for Information Interchangeの略
最も基本的な文字コード。1960年代に開発。
ISO/IEC 646国際基準版と同等
ASCIIの構造
7bitで128文字収録
0x00~0x1Fは制御文字(タブや改行など)
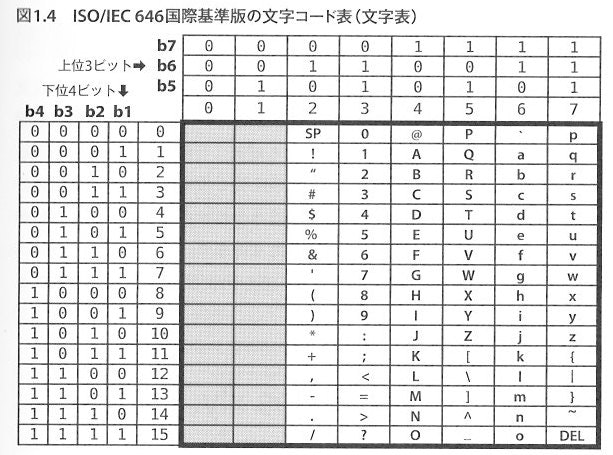
Unicodeとは?
世界中の文字を扱えるようにした文字コード。
従来は国や地域ごとに、文字コードを切り替える必要があった。
たとえば、Shift_JISでは[é]のようなアクセント記号を表せない。
ISO/IEC 10646と同等。1993年制定された。
Unicode(UCS-4)の構造
4バイト符号。
各バイトが、郡、面、区、点に対応する。
面、区、点は00~FF(256)まで、郡は00~7F(128)まで。最大(2^31)文字。
実際には郡00の面10までしか割り当てられていない(UTF-16で表現可能な範囲)。
Unicode(UCS-4)の構造
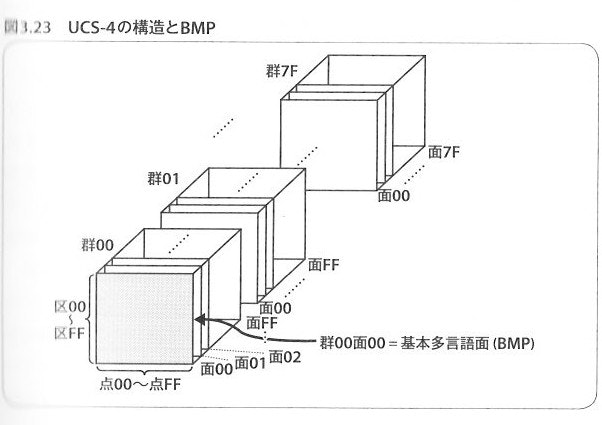
基本多言語面(BMP)
Basic Multilingual Planeの略。郡00面00と同じ。
使用機会の多い、多くの言語が含まれている。
先頭128位置はASCIIと同等。
基本多言語面(BMP)の構造

UTF-16
Unicodeの符号を16bit単位で表す。
BMPは2byte、それ以外は4byte。
Javaの文字列表現など、内部的な表現として使われる。(ファイルやネットワークは外部的表現)
- [あ]: U+3042(BMP) : 0x3042
- [A] : U+0041(BMP) : 0x0041
- [𩸽] : U+29E3D(面02) : 0xD867 DE3D
BMP以外の面は、「サロゲートペア」という仕組みでビットを決めている。
後のスライドで説明。
UTF-8
Unicodeの符号を8bit単位で表す。
1byteから4byte。
ASCII互換。
- [あ]: U+3042(BMP) : 0xE3 81 82
- [A] : U+0041(BMP) : 0x41
- [𩸽] : U+29E3D(面02) : 0xF0 A9 B8 BD
UTF-8の計算方法
「あ」(U+3042)をUTF-8で符号化しましょう!

- U+3042=U+00003042は、3行目の範囲(3byte)
- 16進の3042は、2進の0011 0000 0100 0010
- ビット列を[x]の列にあてはめる。 11100011 10000001 10000010
- すなわち16進の E3 81 82
ASCII文字以外は2byte以上で表す。
1byte目になる値は、他の位置(2~4byte)に現れないので、文字の区切りの誤認がない。
ASCII互換の符号化方式
- ASCII互換
- EUC-JP
- ISO-2022-JP
- Shift_JIS
- UTF-8
- 非ASCII互換
- UTF-16
[A]という文字はASCII互換では0x41、UTF-16では0x0041。
ASCII互換であるメリット
ASCII前提のプログラム(HTTP, SMTPなど)で利用できる。
HTTPで文字コードを指定する文字は、どんな文字コードか分からない!
Content-Type: text/html; charset=UTF-8
ASCII互換の符号化方式ならば利用可能。
UTF-16は指定できない。
HTML5の文字コード宣言
HTML文書がBOMで開始せず、かつそのエンコーディングがContent-Typeメタデータによって明示的に与えられず、かつ文書がiframe srcdoc文書でない場合、使用される文字エンコーディングはASCII互換文字エンコーディングでなければならず、エンコーディングはcharset属性をもつmeta要素またはエンコーディング宣言状態のhttp-equiv属性をもつmeta要素を用いて指定されなければならない。
【まとめ】Unicode, UTF-8, UTF-16の違い
Unicodeは「符号化文字集合」という規格
UTF-8, UTF-16はUnicodeを実装した「符号化方式」
UTF-8は8bit単位でASCII互換
UTF-16は16bit単位で、非ASCII互換
【補足】Unicode, UTF-8, UTF-16の違い混乱のもと
かつてUnicodeは16bit固定長(UTF-16と同等)を目指していた。
2byteでは足りないことが判明したので、4byteに拡張。
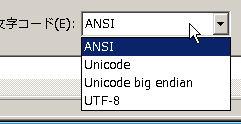
Windowsメモ帳には「Unicode」という項目がある。UTF-16と同じ。
サロゲートペア
UTF-16で、BMP以外の文字を表すための仕組み。
BMPのサロゲート領域2個を使う。
UTF-16の計算方法
n: 符号化対象(BMP以外)
n' = n - 0x10000
n' = yyyy yyyy yyxx xxxx xxxx (20bit)
w1 = 1101 10yy yyyy yyyy (U+D800~U+DBFF : 上位サロゲート)
w2 = 1101 11xx xxxx xxxx (U+DC00~U+DFFF : 下位サロゲート)
[𩸽]をUTF-16で符号化しましょう!
符号位置はU+29E3D(面02)
n' = 0x29E3D - 0x10000 = 0x19E3D
n' = 1 1001 1110 0011 1101
w1 = 1101 1000 0110 0111 (0xD867)
w2 = 1101 1110 0011 1101 (0xDE3D)
UTF-16のバイト順
UTF-16はバイト順を決めていない。
- ビッグエンディアン : 上位8bitが先頭
- リトルエンディアン : 下位8bitが先頭
データの先頭にBOM(Byte Order Mark)を付けて、ビッグエンディアン/リトルエンディアンを区別する。FE FFがビッグエンディアン、FF FEがリトルエンディアン。
「あ」(U+3042)をファイル保存する場合、
- ビッグエンディアン :
FE FF 30 42 - リトルエンディアン :
FF FE 42 30
BOM付きUTF-8
UTF-8は8bit単位なのでバイト順は関係なく、BOMは不要。
「UTF-8」という印になるという考えもある。
UTF-8のBOMはEF BB BFで、ASCIIでない。
ASCII前提のプログラムで問題が起こるかもしれない。
UTF-8はBOMなしがベター
文字コードの自動判別
テキストファイルには文字コードを判別する仕組みがない(BOMを除く)。
「XXというバイトは、文字コードYYYにしか出現しないから、文字コードはYYYだ!」という判別方法。
文字列が短いと判別に失敗しやすい。
自動判別は確実ではない
昔、私が勘違いしていたこと
「abc」という文字をUTF-8でファイル保存したのに、文字コードを判定すると[Shift_JIS]だった。なぜ?
文字コードに関して話さなかったこと
- Shift_JIS, EUC_JPの構造
- 包摂基準(「騨」と「驒」は同じかどうか。歴史的、政治的な要素を含みややこしい)
- 結合文字(文字と濁点・半濁点の組み合わせ。「セ゜」)
- 文字コードによる問題
- 波ダッシュ問題
- 円記号問題
- 全角半角問題
参考サイト