Java, JavaScript(ES5)経験者が、Pythonでハマったこと、分からなかったことを書いていきます。
Python
暗黙の型変換
以下のように文字列+数値を行うとエラーになります。
x = 1
print("x=" + x)
#TypeError: must be str, not int
インデックス[::2]は、2ステップごと
In [15]: b = [1,2,3,4,6,7]
In [16]: b[::2]
Out[16]: [1, 3, 6]
//は整数の除算(切り捨て)
In [18]: 10//3
Out[18]: 3
In [19]: 10 /3
Out[19]: 3.3333333333333335
文字列リテラルを並べると、結合される
In [1]: "a" "b"
Out[1]: 'ab'
In [2]: "a""b"
Out[2]: 'ab'
便利な機能なんですがこのおかげで、「末尾カンマを忘れてもエラーが出ない」という現象が発生します。
In [478]: a = [
...: "a",
...: "b"
...: "c"]
In [479]: a
Out[479]: ['a', 'bc']
itertools.groupby
pandasを使わなくてもgroupbyすることができます。
ただソート済である必要があります。
In [43]: data = ["a","b","b","b", "a"]
...: data = sorted(data)
...: for key, group in itertools.groupby(data):
...: print(key, len(list(group)))
...:
a 2
b 3
正規表現にマッチした文字列を取得
m.group(0)はマッチした文字列全体を表す。
m = re.search(r"([a-z]+)\s*=\s*([0-9]+)", "index = 123")
if m:
print(m.group(0)) # -> "index = 123"
print(m.group(1)) # -> "index"
print(m.group(2)) # -> "123"
listのindexメソッドで、要素が見つからないとValueErrorを返す。
Java, JavaScriptだと要素が見つからない場合、-1を返します。
末尾にカンマがあってもよい
リストや辞書を宣言する際、末尾にカンマがあってもエラーになりません。
l = [1,2,]
d = {"a":1,}
base64でエンコードして文字列に変換
In [1]: encoded = base64.b64encode(b'data to be encoded')
In [2]: type(encoded)
Out[2]: bytes
In [3]: encoded.decode("ascii")
Out[3]: 'ZGF0YSB0byBiZSBlbmNvZGVk'
https://docs.python.jp/3/library/base64.html 参考
type関数の戻り値の型
type({"a":1}) == dict # True
type({"a":1}) == "dict" # False
オブジェクトの型の判定には、 isinstance() 組み込み関数を使うことが推奨されます。これはサブクラスを考慮するからです。
https://docs.python.jp/3/library/functions.html#type 引用
2次元配列を[[0]*2]*2のように宣言するのは良くない
a = [[0]*2]*2
print(a)
# [[0, 0], [0, 0]]
a[0][1] = 1
print(a)
# [[0, 1], [0, 1]]
# a[1][1]も更新されている?
http://delta114514.hatenablog.jp/entry/2018/01/02/233002 参照
fileobject#readlineは改行文字が終端に残る
with open('sample.txt') as f
l = f.readline()
f.readline() はファイルから 1 行だけを読み取ります。改行文字 (\n) は読み出された文字列の終端に残ります。
IPython
-
?でのドキュメント閲覧、??でソースの閲覧 -
%xmode Verboseで、詳細なトレースバックを表示 -
%timeit: 複数回実行して測定してくれる。
モジュールを自動リロード
「pyファイルをエディタで修正⇒ipythonで確認」を繰り返すとき、欲しい機能です。
In [1]: %load_ext autoreload
In [2]: %autoreload 2
https://ipython.org/ipython-doc/3/config/extensions/autoreload.html
http://sandmark.hateblo.jp/entry/2017/10/22/180000
https://qiita.com/Accent/items/f6bb4d4b7adf268662f4
matplotlib
(WIP) 日本語を使う場合
ipython起動時の処理(よく使うimport文など)を設定
ipythonプロファイルを生成する。
$ ipython3 profile create
c.InteractiveShellApp.exec_lines = [
'import numpy as np',
'import matplotlib.pyplot as plt',
'import pandas as pd',
'%load_ext autoreload',
'%autoreload 2'
]
Jupyter Notebook起動時に、インポート・matplotlibの設定を自動実行する - Qiita
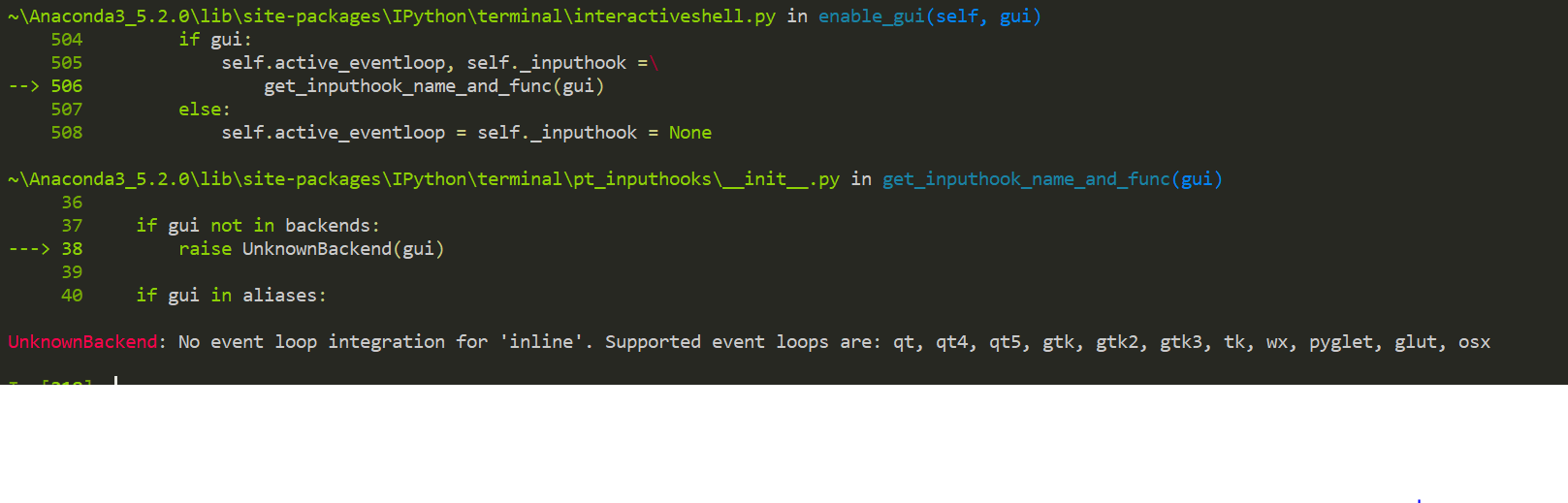
%matplotlib inlineでエラー
画像を表示できないコンソール(Windows Cmder)で実行すると、以下のエラーが発生しました。
原因は、画像が表示できない環境で実行したからです。
In [1]: %matplotlib inline
UnknownBackend: No event loop integration for 'inline'. Supported event loops are: qt, qt4, qt5, gtk, gtk2, gtk3, tk, wx, pyglet, glut, osx
numpy
配列要素にNoneが含まれていると、sum()でエラー
In [5]: vals1 = np.array([1, None, 3,4])
In [6]: vals1.sum()
TypeError: unsupported operand type(s) for +: 'int' and 'NoneType'
Pandas
pivot_tableメソッドのvaluesオプションにlistを渡すと、列方向のMultiIndexが生成される
valuesに文字列(列名)を渡した場合
In [33]: import seaborn as sns
...: titanic = sns.load_dataset("titanic")
...: p = titanic.pivot_table("survived", index="sex", columns="class")
...: p
Out[33]:
class First Second Third
sex
female 0.968085 0.921053 0.500000
male 0.368852 0.157407 0.135447
In [36]: p.columns
Out[36]: CategoricalIndex(['First', 'Second', 'Third'], categories=['First', 'Second', 'Third'], ordered=False, name='class', dtype='category')
In [37]: p["First"]
Out[37]:
sex
female 0.968085
male 0.368852
Name: First, dtype: float64
valuesにlist(列名のlist)を渡した場合
In [38]: p2 = titanic.pivot_table(values=["survived"], index="sex", columns="class")
In [39]: p2
Out[39]:
survived
class First Second Third
sex
female 0.968085 0.921053 0.500000
male 0.368852 0.157407 0.135447
In [40]: p2.columns
Out[40]:
MultiIndex(levels=[['survived'], ['First', 'Second', 'Third']],
labels=[[0, 0, 0], [0, 1, 2]],
names=[None, 'class'])
In [41]: p2["survived"]["First"]
Out[41]:
sex
female 0.968085
male 0.368852
Name: First, dtype: float64
1個のファイルに複数のDataFrameを出力する
with open("sample.csv", mode="w") as f:
f.write("title1\n")
df1.to_csv(f)
f.write("title2\n")
df2.to_csv(f)
※pandas 0.23.1 では、正しく動かない(リグレッションバグ)。
https://github.com/pandas-dev/pandas/issues/21471
辞書のlistからDataFrameを作ったとき、列の順番は保証されない
そもそも辞書型は順序が保証されないので、当然ではありますが。。。
l = [{"b":1,"a":2}]
df = pd.DataFrame(l)
print(df.columns)
# Index(['a', 'b'], dtype='object')
NaNが含まれているDataFrameをto_csvで出力すると、デフォルト空文字
l = [{"b":1,"a":np.NaN}]
df = pd.DataFrame(l)
# NaNは空文字でCSV出力
df.to_csv("sample1.csv")
# NaNは0でCSV出力
df.to_csv("sample2.csv", na_rep=0)
$ less sample1.csv
,a,b
0,,1
$ less sample2.csv
,a,b
0,0,1
na_rep : string, default ''
Missing data representation
Jupyter Notebookで最大業出力
Pytest
標準出力と標準エラー出力を表示する
pytest -s
https://pytest.readthedocs.io/en/reorganize-docs/new-docs/user/commandlineuseful.html#s-capture-no