環境
- JDK 1.8.0_162
- Apache POI 3.15
- Excel2016
dependencies {
compile group: 'org.apache.poi', name: 'poi', version: '3.15'
compile group: 'org.apache.poi', name: 'poi-ooxml', version: '3.15'
}
やりたいこと
Apache POIで、Excelファイルを読み込み、セル内の数式の結果を取得したいです。
コードは、以下の通りです。
public class SampleApachePoiUtil {
/**
* セル内の数式を計算し、結果をStringとして返す。
* @param formulaCell 数式を含むセル
* @return 数式の結果(String)
*/
public static String getStringFormulaValue(Cell formulaCell) {
Workbook book = formulaCell.getSheet().getWorkbook();
CreationHelper helper = book.getCreationHelper();
FormulaEvaluator evaluator = helper.createFormulaEvaluator();
CellValue value = evaluator.evaluate(formulaCell);
//【注意】Stringであること前提
return value.getStringValue();
}
public static void sample(File file) throws IOException, InvalidFormatException {
Workbook workbook = WorkbookFactory.create(file);
Sheet sheet = workbook.getSheet("main");
//数式を含むセル("main"シートのA1セル)
Cell formulaCell = sheet.getRow(0).getCell(0);
//数式を計算する
String result = getStringFormulaValue(formulaCell);
System.out.println("result = " + result);
workbook.close();
}
}
参考サイト
- https://poi.apache.org/apidocs/org/apache/poi/ss/usermodel/FormulaEvaluator.html
- https://poi.apache.org/spreadsheet/eval.html
問題
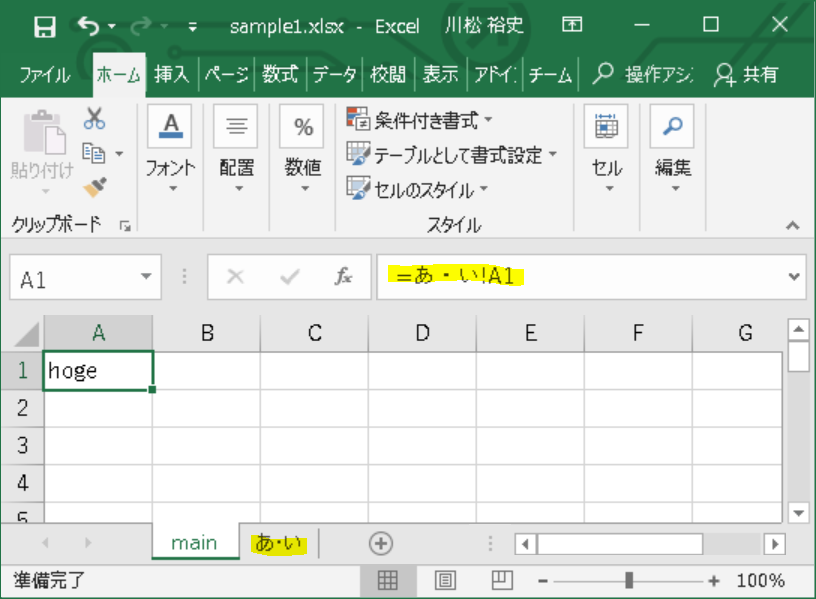
"あ・い"というシートのセルを参照する数式、=あ・い!A1の結果を取得しようとしたら、FormulaParseExceptionが発生しました。
Exception in thread "main" org.apache.poi.ss.formula.FormulaParseException: Specified named range 'あ' does not exist in the current workbook.
at org.apache.poi.ss.formula.FormulaParser.parseNonRange(FormulaParser.java:898)
at org.apache.poi.ss.formula.FormulaParser.parseRangeable(FormulaParser.java:490)
at org.apache.poi.ss.formula.FormulaParser.parseRangeExpression(FormulaParser.java:311)
at org.apache.poi.ss.formula.FormulaParser.parseSimpleFactor(FormulaParser.java:1509)
at org.apache.poi.ss.formula.FormulaParser.percentFactor(FormulaParser.java:1467)
at org.apache.poi.ss.formula.FormulaParser.powerFactor(FormulaParser.java:1454)
at org.apache.poi.ss.formula.FormulaParser.Term(FormulaParser.java:1827)
at org.apache.poi.ss.formula.FormulaParser.additiveExpression(FormulaParser.java:1955)
at org.apache.poi.ss.formula.FormulaParser.concatExpression(FormulaParser.java:1939)
at org.apache.poi.ss.formula.FormulaParser.comparisonExpression(FormulaParser.java:1896)
at org.apache.poi.ss.formula.FormulaParser.intersectionExpression(FormulaParser.java:1869)
at org.apache.poi.ss.formula.FormulaParser.unionExpression(FormulaParser.java:1849)
at org.apache.poi.ss.formula.FormulaParser.parse(FormulaParser.java:1997)
at org.apache.poi.ss.formula.FormulaParser.parse(FormulaParser.java:170)
at org.apache.poi.xssf.usermodel.XSSFEvaluationWorkbook.getFormulaTokens(XSSFEvaluationWorkbook.java:85)
at org.apache.poi.ss.formula.WorkbookEvaluator.evaluateAny(WorkbookEvaluator.java:315)
at org.apache.poi.ss.formula.WorkbookEvaluator.evaluate(WorkbookEvaluator.java:259)
at org.apache.poi.xssf.usermodel.BaseXSSFFormulaEvaluator.evaluateFormulaCellValue(BaseXSSFFormulaEvaluator.java:65)
at org.apache.poi.ss.formula.BaseFormulaEvaluator.evaluate(BaseFormulaEvaluator.java:101)
at SampleApachePoiUtil.getStringFormulaValue(SampleApachePoiUtil.java:21)
at SampleApachePoiUtil.sample(SampleApachePoiUtil.java:33)
at Main.main(Main.java:7)
「あ」という名前のセル範囲が、存在しないと言われました。
どうやら、シート名が正しく解析できず、なぜか「セルの名前」と判断されたようです。
原因調査
問題が発生するパターン
参照しているシート名と、ファイルの拡張子を変えて、エラーが発生するかどうかを確認しました。
| 拡張子 | 数式が参照しているシート名 | 結果 |
|---|---|---|
| xlsx | あ・い | NG |
| xlsx | あい | OK |
| xlsx | ・ | NG |
| xlsx | あ〒い | NG |
| xls | あ・い | OK |
非ASCII文字が原因ではなく、「・」や「〒」などの特殊な文字?が原因のようです。
以下は、シート名が"・"のときのスタックトレースです。
シート名が"あ・い"のときと、メッセージが異なっていました。
Exception in thread "main" org.apache.poi.ss.formula.FormulaParseException: Parse error near char 0 '・' in specified formula '・!A1'. Expected cell ref or constant literal
at org.apache.poi.ss.formula.FormulaParser.expected(FormulaParser.java:262)
at org.apache.poi.ss.formula.FormulaParser.parseSimpleFactor(FormulaParser.java:1514)
at org.apache.poi.ss.formula.FormulaParser.percentFactor(FormulaParser.java:1467)
at org.apache.poi.ss.formula.FormulaParser.powerFactor(FormulaParser.java:1454)
at org.apache.poi.ss.formula.FormulaParser.Term(FormulaParser.java:1827)
at org.apache.poi.ss.formula.FormulaParser.additiveExpression(FormulaParser.java:1955)
at org.apache.poi.ss.formula.FormulaParser.concatExpression(FormulaParser.java:1939)
at org.apache.poi.ss.formula.FormulaParser.comparisonExpression(FormulaParser.java:1896)
at org.apache.poi.ss.formula.FormulaParser.intersectionExpression(FormulaParser.java:1869)
at org.apache.poi.ss.formula.FormulaParser.unionExpression(FormulaParser.java:1849)
at org.apache.poi.ss.formula.FormulaParser.parse(FormulaParser.java:1997)
at org.apache.poi.ss.formula.FormulaParser.parse(FormulaParser.java:170)
at org.apache.poi.xssf.usermodel.XSSFEvaluationWorkbook.getFormulaTokens(XSSFEvaluationWorkbook.java:85)
at org.apache.poi.ss.formula.WorkbookEvaluator.evaluateAny(WorkbookEvaluator.java:315)
at org.apache.poi.ss.formula.WorkbookEvaluator.evaluate(WorkbookEvaluator.java:259)
at org.apache.poi.xssf.usermodel.BaseXSSFFormulaEvaluator.evaluateFormulaCellValue(BaseXSSFFormulaEvaluator.java:65)
at org.apache.poi.ss.formula.BaseFormulaEvaluator.evaluate(BaseFormulaEvaluator.java:101)
at SampleApachePoiUtil.getStringFormulaValue(SampleApachePoiUtil.java:21)
at SampleApachePoiUtil.sample(SampleApachePoiUtil.java:33)
at Main.main(Main.java:7)
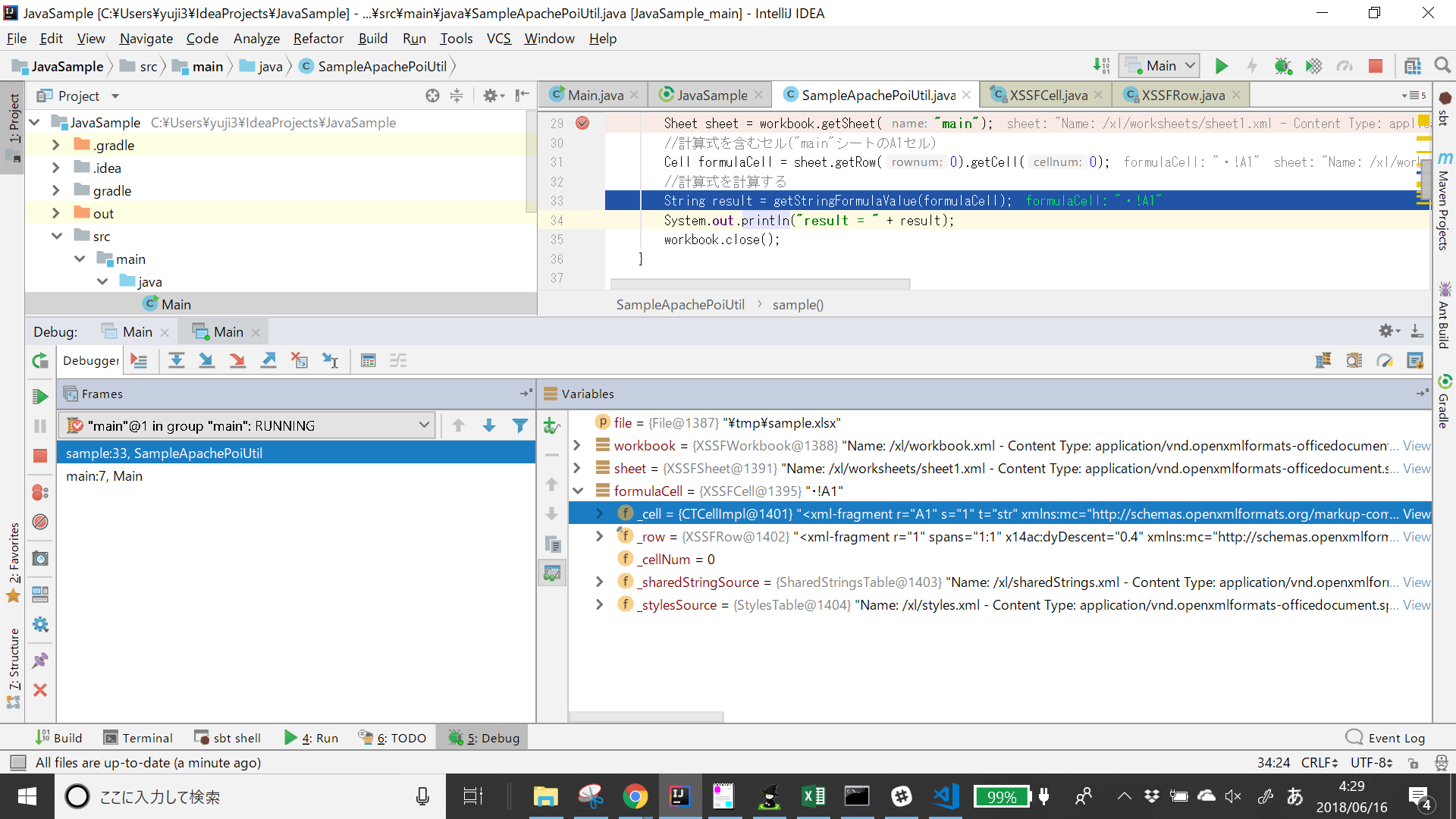
数式のセルをデバッガで確認
デバッグで、formulaCell._cellの中身を確認しました。
<xml-fragment r="A1" s="1" t="str" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:x14ac="http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac" xmlns:xr="http://schemas.microsoft.com/office/spreadsheetml/2014/revision" xmlns:xr2="http://schemas.microsoft.com/office/spreadsheetml/2015/revision2" xmlns:xr3="http://schemas.microsoft.com/office/spreadsheetml/2016/revision3" xmlns:main="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
<main:f>あ・い!A1</main:f>
<main:v>hoge</main:v>
</xml-fragment>
<main:f>には数式、<main:v>には数式の結果が格納されていました。
格納されている値は期待した通りなので、Excelファイルの読み込みは問題なさそうです。
※たぶん、"f"は formula, "v"は valueのこと
※<main:v>に格納されている値は、Apache POIが計算した値ではなく、Excelファイルに格納されている値。計算結果はキャッシュされるらしい。
The Excel file format (both .xls and .xlsx) stores a "cached" result for every formula along with the formula itself.
https://poi.apache.org/spreadsheet/eval.html 引用
「・」について
- 日本語読み:中点
- ユニコード:U+30FB
- 10進数だと
12539
- 10進数だと
- ユニコード名:KATAKANA MIDDLE DOT
https://www.fileformat.info/info/unicode/char/30fb/index.htm
https://ja.wikipedia.org/wiki/%E4%B8%AD%E9%BB%92
解決
Apache POIのバージョンを3.15から3.16(厳密には3.16-beta2)に上げたら、エラーは出なくなり、期待した通りの動きになりました。
以下は関連するバグ報告です。こちらは、「・」を含むシート名に対してshiftRowsメソッドを実行したら、エラーになったそうです。
Partial support for unicode sheet names
エラーの原因
FormulaParser.javaのisUnquotedSheetNameCharメソッドが、直接的な原因でした。
数式に含まれているシート名は、org.apache.poi.ss.formula.FormulaParser.javaのparseSheetNameメソッドで取得します。
private SheetIdentifier parseSheetName() {
//...
// unquoted sheet names must start with underscore or a letter
if (look =='_' || Character.isLetter(look)) {
StringBuilder sb = new StringBuilder();
// can concatenate idens with dots
while (isUnquotedSheetNameChar(look)) {
sb.append(look);
GetChar();
}
NameIdentifier iden = new NameIdentifier(sb.toString(), false);
SkipWhite();
if (look == '!') {
GetChar();
return new SheetIdentifier(bookName, iden);
}
// See if it's a multi-sheet range, eg Sheet1:Sheet3!A1
if (look == ':') {
return parseSheetRange(bookName, iden);
}
return null;
}
//...
parseSheetNameメソッドで呼んでいるisUnquotedSheetNameCharメソッドの定義です。
/**
* very similar to {@link SheetNameFormatter#isSpecialChar(char)}
*/
private static boolean isUnquotedSheetNameChar(char ch) {
if(Character.isLetterOrDigit(ch)) {
return true;
}
switch(ch) {
case '.': // dot is OK
case '_': // underscore is OK
return true;
}
return false;
}
isUnquotedSheetNameCharメソッドの戻り値は、以下の結果になります。
| 文字 | UnicodeのCategory | isUnquotedSheetNameCharの戻り値 |
|---|---|---|
| あ | Letter, Other [Lo] | true |
| ・ | Punctuation, Other [Po] | false |
| い | Letter, Other [Lo] | true |
isUnquotedSheetNameCharメソッドに・を渡すとfalseを返すので、シート名を正しく取得できず、エラーになりました。
isUnquotedSheetNameCharメソッドの修正版(Apache POI 3.16 beta2)
/**
* very similar to {@link SheetNameFormatter#isSpecialChar(char)}
* @param ch unicode codepoint
*/
private static boolean isUnquotedSheetNameChar(int ch) {
if(Character.isLetterOrDigit(ch)) {
return true;
}
// the sheet naming rules are vague on whether unicode characters are allowed
// assume they're allowed.
if (ch > 128) {
return true;
}
switch(ch) {
case '.': // dot is OK
case '_': // underscore is OK
return true;
}
return false;
}
変更点は、以下の2つです。
- ユニコード対応
- 非ASCII文字は、常にtrueを返す
「・」もtrueを返すようになりました。
まとめ
- Apache POI 3.15で、以下の条件を満たす数式を計算すると、
FormulaParseExceptionが発生する- XLSX形式
- シート名に「・」などの文字を含むシートのセルを、参照している
-
Character.isLetterOrDigitメソッドがfalseを返す文字
-
- Apache POI 3.16では、上記の問題が解決されている
補足
Excelの数式のBNE
https://github.com/apache/poi/blob/trunk/src/java/org/apache/poi/ss/formula/FormulaParser.java 引用
This class parses a formula string into a List of tokens in RPN order.
Inspired by
Lets Build a Compiler, by Jack Crenshaw
BNF for the formula expression is :
<expression> ::= <term> [<addop> <term>]*
<term> ::= <factor> [ <mulop> <factor> ]*
<factor> ::= <number> | (<expression>) | <cellRef> | <function>
<function> ::= <functionName> ([expression [, expression]*])
For POI internal use only
- RPN(Reverse Polish Notation, 逆ポーランド記法)順で、トークンリストを作っている
-
Let's Build a Compiler, by Jack Crenshawにインスパイアされた
「・」のUnicodeカテゴリ
Apache POIとは関係ない話です。
「・」のカテゴリは「Punctuation, Other [Po]」ですが、Unicode4.1より前では「Punctuation, Connector [Pc]」でした。
http://www.unicode.org/reports/tr44/tr44-4.html#Change_History
この関係で、「Java6ではメソッド名に『・』が使えたのに、Java7で使えなくなった」、という問題があったそうです。
恐ろしい。。。
分からなかったこと
XLS形式(Excel 2003形式)では、エラーが起きなかった理由
デバッガを用いて、以下のことが分かりました。
-
FormulaParserのparseSheetNameメソッドは通らない -
org.apache.poi.ss.formula.WorkbookEvaluatorが利用される
WorkbookEvaluatorのJavaDocには、「計算結果のキャッシュを保持する」と書いてあります。
For performance reasons, this class keeps a cache of all previously calculated intermediate cell values.
https://poi.apache.org/apidocs/org/apache/poi/ss/formula/WorkbookEvaluator.html 引用
計算結果のキャッシュを参照しているから、エラーにならなかったんですかね?