
この記事の紹介動画
NoLang で 生成した 30秒紹介動画です。
はじめに
Stable Diffusion 3(SD3 Medium) が公開されて Generative AI Age には無限といってもよい時間が流れましたがいかがお過ごしでしょうか?
我が友である Nvidia RTX2060 6GB という太古の遺物にはSD3はかなり荷が重いモデルです。24GB近い VRAM が必要です。
クラウドなら OCI のGPU搭載仮想マシン・シェイプ の VM.GPU.A10(GPU:1xA10)は VRAM 24GB、ベアメタル・シェイプならもっと大きな VRAM 搭載のシェイプもあるので楽勝ですが、VRAM が16GB の廉価な仮想マシン VM.GPU2.1(GPU: 1xP100) や VM.GPU3.1(GPU: 1xV100) でも動くと嬉しいですよね。
SD3のGPU VRAM消費量が大きい理由は実はテキストで書かれたプロンプトをビジョンモデルが理解できるエンベディング形式に変換するテキストエンコーダーにあります。SD3 は3つの異なるテキストエンコーダーを使用しているのですが、この中でパラメータ数が多い T5-XXL(4.7B)がメモリ消費量増大に大きく貢献しています。これを外してしまって 残りの2つのCLIP だけで生成するというのが常套手段のようです。複雑なプロンプトの理解を除けば生成画像の品質の差も小さいようです。この方法なら ComfyUI でも使えます。
でも!せっかく巨大なテキストエンコーダーが使えるんだから使いたいというのが人情ですよね?(本当は Hugging Face Diffusers で遊びたいだけでしょ、という声は聞こえません!)
T5-XXL を外してしまう方法以外では 共有VRAM と Model Offloading 、8ビット量子化の 3つの VRAM 最適化手法があるようです。今回は、共有VRAM と Model Offloadingを較べる実験をしてみました。
コードはこの記事の中でも紹介していますが、Github でも公開しています。
VRAM 最適化
公式はメモリ最適化と呼んだいるようですが CPU (のメモリコントローラにぶらさがっている)側のメモリと混同しそうなのでここでは VRAM 最適化と呼びます。 VRAM 最適化には以下のような方法があるようです。
共有 GPUメモリ
Windows の機能ですね。他の OS だとどうなんでしょう? Perplexity に聞けばすぐ教えてくれそうですがほっときます。
Windows のタスクマネージャーのパフォーマンス・モニタを見ると下の方にこんな表示があります。
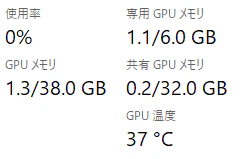
我が愛機の GPU は 6GB の VRAM を搭載していて、6GB からあふれた場合には CPU 側のメモリ から 32GB 借りてきて合計 38GB までをあたかも GPU の VRAM であるかのように使えるということを意味しています。仮想メモリのスワップ領域のように CPU 側のメモリを使うわけですけど圧倒的に遅いですよね。どのくらい遅いかというと Perplexity に聞けば...以下省略。
NVIDIA の GPU の場合、ドライバーが古すぎなければ NVIDIA コントロールパネルで意図的に "System Memory Fallback" を無効化していない限り自動的に使われるので設定は不要です。
T5-XXL を外してしまう
今回は対象外にします。T5-XXL を使うにはどうしたらいい?という観点ですので。
ちなみに、ComfyUI で T5-XXL なしで CLIP だけをテキストエンコーダとして使って軽量化したい場合は下記の Hugging Face Hub から sd3_medium_incl_clips.safetensors をダウンロードして ComfyUI/models/checkpoints フォルダに置くだけですね。
T5-XXL の 8ビット量子化
これは多少 T5-XXL によるプロンプトの理解力が下がるだけだと思いますので今回の目的上もありですが、Model Offloading では不十分だったときのオプションに取っておきます。
(やり方はこちら)
Model Offloading
Hugging Face Diffusers で使える方法です。モデル全体を GPU VRAMにロードするのではなく、推論中に必要なタイミングで必要なコンポーネントだけを GPU にロードして、その時以外は CPU 側メモリに置いておくものです。共有VRAMと似ていなくもないのですが OS レベルの共有VRAMよりもDiffusers の方がモデルの中のどのコンポーネントがいつ必要なのかをよりよく判断できると思いますので効率が良さそうです。
実験
ということで、共有GPUメモリ におまかせする場合と Model Offloading した場合を Diffusers を使ったコードで実験して較べてみました。機材は Nvidia RTX 2060 6GB VRAM マシンです。
Diffusers の Stable Diffusion 3 Medium の詳細については下記の公式サイトを参照してください。
プロンプト
Photorealistic graphics of a girl with long blue hair stands in front of a spaceship
window, gazing outside. The scene captures her back view, emphasizing her contemplative
posture as she admires the vastness of space.
She is wearing a large white hat and a white dress. Outside the window, a vibrant galaxy
is visible, filled with colorful stars and cosmic phenomena. The scene captures her back
view, emphasizing her contemplative posture as she admires the vastness of space.
The interior of the spaceship is simply constructed in metallic colors, and her figure
floating in the dimness is impressive. The walls of the ship have a metallic sheen
and glow dully in the dim light.
日本語に翻訳するとこんな感じです。
長い青い髪の少女が宇宙船の窓の前に立ち、外を見つめているフォトリアリスティックなグラフィック。
彼女の後ろ姿をとらえたこのシーンは、広大な宇宙を眺める彼女の瞑想的な姿勢を強調しています。
彼女は大きな白い帽子をかぶり、白いドレスを着ている。窓の外には、色とりどりの星々と宇宙現象に
満ちた、活気に満ちた銀河が見える。このシーンでは彼女の後ろ姿が捉えられており、広大な宇宙に
感嘆する彼女の瞑想的な姿勢が強調されている。宇宙船の内部はメタリックカラーでシンプルに構成され、
薄闇の中に浮かぶ彼女の姿が印象的だ。船内の壁はメタリックな光沢を放ち、
薄明かりの中で鈍く光っている。
推論パラメータ
- num_inference_steps : 28
- guidance_scale : 3.5
- height : default(1024)
- width : default(1024)
実験結果
| 共有GPUメモリ | Model Offloading | 推論(生成)時間 |
|---|---|---|
| あり | 無効 | 725.09秒 |
| あり | 有効 | 144.40秒 |
ということで、Model Offloading の方が圧倒的に高速でした。
なお、目視で確認する限り画像のクオリティに差はないようです。
 |
 |
| Model Offloading 無効 | Model Offloading 有効 |
コード
import torch
from diffusers import StableDiffusion3Pipeline
import os
import png
import time
def create_pipe(offload = True):
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16
)
if offload:
pipe.enable_model_cpu_offload()
else:
pipe.to("cuda")
return pipe
def inference(pipe, seed):
generator = torch.Generator("cuda").manual_seed(seed)
image = pipe(
prompt = prompt,
prompt_3=prompt_3,
num_inference_steps=28,
guidance_scale=3.5,
generator=generator
).images[0]
return image
def make_text_chunk(keyword, text):
# PNG のテキストチャンクを組み立てる
return keyword.encode('latin-1') + b'\0' + text.encode('utf-8')
def save_image_with_metadata(image, base_filename, prompt=None, prompt_3=None, seed=1):
# 出力ディレクトリを作成
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
# 連番のファイル名を生成
i = 1
while True:
filename = os.path.join(output_dir, f"{base_filename}_{i:03d}.png")
if not os.path.exists(filename):
break
i += 1
# 画像を保存
image.save(filename)
# テキストチャンクを作成
text_chunks = []
if prompt:
text_chunks.append((b'tEXt', make_text_chunk('prompt', prompt)))
if prompt_3:
text_chunks.append((b'tEXt', make_text_chunk('prompt_3', prompt_3)))
if seed:
text_chunks.append((b'tEXt', make_text_chunk('seed', str(seed))))
if text_chunks:
# PNGファイルを読み込み、テキストチャンクを追加して再保存
reader = png.Reader(filename=filename)
chunks = reader.chunks()
chunk_list = list(chunks)
# IHDRチャンクの直後にテキストチャンクを挿入
insert_pos = 1
for chunk in text_chunks:
chunk_list.insert(insert_pos, chunk)
insert_pos += 1
with open(filename, 'wb') as output:
png.write_chunks(output, chunk_list)
if __name__ == "__main__":
# 繰り返し回数を指定
n = 1
# モデルオフロードを有効にするかどうか (True or False)
offload = True
# シード値のベース
seed_base = 123456789012
prompt = "Photorealistic graphics of a girl with long blue hair stands in front of a spaceship window, gazing outside. The scene captures her back view, emphasizing her contemplative posture as she admires the vastness of space."
prompt_3 = "She is wearing a large white hat and a white dress. Outside the window, a vibrant galaxy is visible, filled with colorful stars and cosmic phenomena. The scene captures her back view, emphasizing her contemplative posture as she admires the vastness of space. The interior of the spaceship is simply constructed in metallic colors, and her figure floating in the dimness is impressive. The walls of the ship have a metallic sheen and glow dully in the dim light."
# パイプラインを作成
pipe = create_pipe(offload=offload)
total_time = 0
if offload:
print("モデルオフロードが有効です")
else:
print("モデルオフロードが無効です")
for i in range(n):
start_time = time.time()
image = inference(pipe, seed_base+i+1)
end_time = time.time()
inference_time = end_time - start_time
total_time += inference_time
save_image_with_metadata(image, "sd3_generated", prompt=prompt, prompt_3=prompt_3, seed=seed_base+i+1)
print(f"{n}枚中 {i+1}枚目の画像が生成され、保存されました")
print(f"推論時間: {inference_time:.2f}秒")
average_time = total_time / n
print(f"\n平均推論時間: {average_time:.2f}秒")
モデルのロード
-
create_pipe()でモデル(stable-diffusion-3-medium-diffusers)を読み込んで Diffusers のパイプラインを生成しています。Diffusers のStableDiffusion3Pipelineクラスのfrom_pretrainedメソッドを使用しています - Model Offloading する場合は、
enable_model_cpu_offload()メソッドを呼びます。Model Offloading せずにモデルを GPU(共有GPUメモリを含む) へ転送する場合は、to("cuda")を呼びます
推論(画像生成)
inferenceが実際に画像を生成している関数です。
-
torch.Generator("cuda")で、CUDAデバイス(GPUメモリ)上に乱数生成器を作成しています。これにより、GPUを使用して乱数を生成することができます -
manual_seed(seed)で生成器のシード値を手動で設定します。シード値を指定することで、同じシード値を使用すれば常に同じ乱数列が生成されるため、結果の再現性が確保されます - Diffusers のパイプライン(
pipe)に推論(SD3の画像生成)パラメータを渡して画像生成を行います
テキストチャンク
save_image_with_metadata() で PNG ファイルにプロンプトと seed 値をテキストチャンクとして埋め込んでいます。これは今回の実験とは関係がありません。作成中の画像検索アプリで生成画像を管理したいと思っているのでそれに合わせて埋め込んでいます。AUTOMATIC1111版の Stable Diffusion Web UI でテキストチャンクを活用しているのを見て真似てみました。画像ファイルにプロンプトが埋め込まれているのは便利ですよね。
作成中の画像検索アプリはこちら↓で記事にしています。Japanese Stable CLIP で特徴ベクトルを生成して、ベクトルデータベースを使ってテキストから画像を検索したり、画像から類似画像を検索することができるアプリケーションです。よかったらこちらにもお立ち寄りください。
テスト条件の指定
mainで画像生成の条件を設定しています。
- 繰り返し回数
- Model Offload を有効化するか無効化するか
- 初期seed値
- プロンプト
-
prompt: CLIP のプロンプト。2つの CLIP で共通にしています。Diffusers のStableDiffusion3Pipelineの仕様上は、2つの CLIP にそれぞれ独立したプロンプトを与えることができますが、ここでは共通にしています。分ける場合は、prompt_2というパラメータを渡してあげるだけです。prompt_2を指定していない場合は、promptと同じプロンプトが使われます。prompt、prompt_2の最大トークン長は 77 トークンです。これを超えるプロンプトを与えた場合はトランケートされます -
prompt_3: T5-XXL のプロンプト。最大トークン長はデフォルトでは 256 トークンです。max_sequence_length パラメータを指定することで小さくすることも大きくすることもできます。最大は 512 トークンです。このパラメータを指定しない場合は、promptと同じプロンプトが使われます。長いプロンプトを使用すると推論時間が長くなり消費メモリが大きくなります。
-
実行方法
- PyTorch をインストールします
GPU、CUDAバージョン、PyTorchバージョンの組み合わせに注意して、CUDA対応の PyTorchをインストールする必要があります。こちらを参考にしてみてください
- ライブラリをインストールします
pip コマンド
# pip install transformers diffusers accelerate sentencepiece protobuf pypng
- テストコードの以下の部分をテストケースに合わせて修正します
テストケース毎に変更する部分
if __name__ == "__main__": # 繰り返し回数を指定 n = 1 # モデルオフロードを有効にするかどうか offload = True
- 実行
実行コマンド
python SD3_ModelOffloading_test.py
えっと、あとがきです
半年ぶりくらいに Diffusers で遊んでみましたがやっぱり楽しいですね。
Model Offloading を使うと Nvidia RTX 2060 6GB VRAM マシンでもなんとか耐えられるくらいの生成時間になりました。text2image の次は image2image や In-painting を試したいところですがテキストエンベディングをあらかじめ用意しておいて推論時のパラメータで渡すということもできるようなのでどんなことができるか試してみたい気もします。
終わりだよ~(o・∇・o)
おまけ
他にもいろいろ記事を書いていますので良かったらお立ち寄りください。