AIではない選択 - 過去を見つめ、未来を変える画像処理
はじめに
この記事は、この記事はNTTテクノクロス Advent Calendar 2023の22日目です。
こんにちは、NTTテクノクロスの広瀬です。
医療関連やメディア処理を中心としたデータサイエンスの研究開発や、講演や講師活動を通じてPythonの啓蒙活動などをしています。
さて、ディープラーニングと大規模言語モデル(LLM)の進化は画像処理技術の進化とも密接に関連しています。その中でも近年の CLIP(Contrastive Language-Image Pre-Training) のような技術は、画像とテキストを組み合わせた強力なモデルを生み出し、Computer Visionの世界を新たな次元に引き上げました。
この先進的な技術は、フレームワークやAPIの整備が短期間で進み、公開とほぼ同時に利用可能になったことで、ディープラーニングから画像処理を学び始めた技術者であっても非常に高性能なシステムを構築することができるようになっています。
さらに一歩先の技術者を目指すにあたって、画像処理の基本的な概念を身につけることで、より複雑なタスクの解決のための洞察が得られるのではないでしょうか。
そこでこの記事では、AI(機械学習)ではなくルールベースの画像処理手法はどのようなことをしていくのかに触れていきたいと思います。
ルールベース手法は、教師データが不要というメリットが有り、結果の解釈性や厳密性が求められる場合などにおいては第一の選択肢となります。
さらに、ディープラーニングと対象的に特徴量設計を手動で行う必要があることから、データがどのような特徴を持っているかを探索する際には、基礎技術を身に着けておくことがアイディアの幅を広げる術の1つになるのではと思います。
物体検出(ペンと鉛筆を見つける)
処理対象として、机の上にペンと鉛筆を転がしてみました。
機械学習やディープラーニングを使わずにこのペンと鉛筆を見つけるにはどうすればよいでしょうか。
| サインペンと鉛筆をどう見つける? |
|---|
 |
今回は背景が格子状なのと色味が特徴的なので、色を特徴としていきましょう。
赤っぽい部分は鉛筆!
青っぽい部分はサインペン!
やや無理やりですが、今回はこれでルールを作っていきます。
このように、ディープラーニングを使用しない場合は何を特徴として判断していくのかを、人間が考えて設定する必要があります。手間がかかる反面、なぜそれをペンだと思ったのか(なぜ間違えたのか)が理解しやすいのがポイントですね。
赤色とは?
では、ルールベースの手法なので、赤っぽさを定義していきましょう。
赤っぽさとは何でしょうか。
画像データは基本的にRGBの3つが0~255(8bit)の情報を持つように表現されています。
この組み合わせがどうなったときに赤と呼びましょうか。ちょっと複雑なルールになりそうですね。
| どうなったら赤と判定する? |
|---|
 |
色相
画像処理においてRGBで色を扱うのは非常に難しいので、HSVの色空間で扱うようにします。
RGB色空間では、色は赤(Red)、緑(Green)、青(Blue)の3つの基本色の組み合わせによって作られます。しかし、RGBでは色と明るさが密接に結びついており、色の調整が直感的でなく、特定の色の範囲を指定するのが難しいことがあります。たとえば、RGB値を均等に変更しても、色の変化が均等に見えない場合があります。
これに対して、HSV色空間は「色相(Hue)」、「彩度(Saturation)」、「明度(Value)」の3つの軸で色を表現します。HSV色空間の大きな利点は、色を直感的に指定できることです。たとえば、「赤色の範囲」を指定する場合、単に色相の特定の範囲(例:0°から30°)を指定するだけで済みます。このように、HSV色空間は色の調整や特定の色の範囲を選択する際に非常に便利です。
| 色相と定義する色の範囲 |
|---|
 |
色相が0-10度 + 170-180度は鉛筆!
色相が110-130度はサインペン!
改めて、↑のようなルールを設定します。
実装編
サインペンの検出
では、実際に検出を行ってみましょう。
ここまで赤色の話をしてきましたが、まずは今回のデータでは比較的簡単な青色からトライします。
image: MatLike = cv2.imread(image_path)
# 表示用
image_rgb: MatLike = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
def color_mask(image: MatLike, lower_color_threshold:MatLike, upper_color_threshold:MatLike):
"""
指定された色閾値に基づいて画像から特定の色範囲のマスクを作成し、マスク内の小さな隙間や穴を埋める関数。
:param image: 入力画像(BGR形式)
:param lower_color_threshold: 色範囲の下限値(HSV形式)
:param upper_color_threshold: 色範囲の上限値(HSV形式)
:return: 作成されたマスク画像(白黒)
"""
# 画像をHSV色空間に変換
hsv_image: MatLike = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 指定された色範囲に基づいてマスクを作成
mask: MatLike = cv2.inRange(hsv_image, lower_color_threshold, upper_color_threshold)
# モルフォロジー変換(防縮処理)を適用してマスク内の隙間を埋める
mask = cv2.dilate(mask, np.ones((5, 5), np.uint8), iterations=1)
return mask
# 色相110~130までの範囲を青色と設定
lower_blue = np.array([110, 150, 50])
upper_blue = np.array([130, 255, 255])
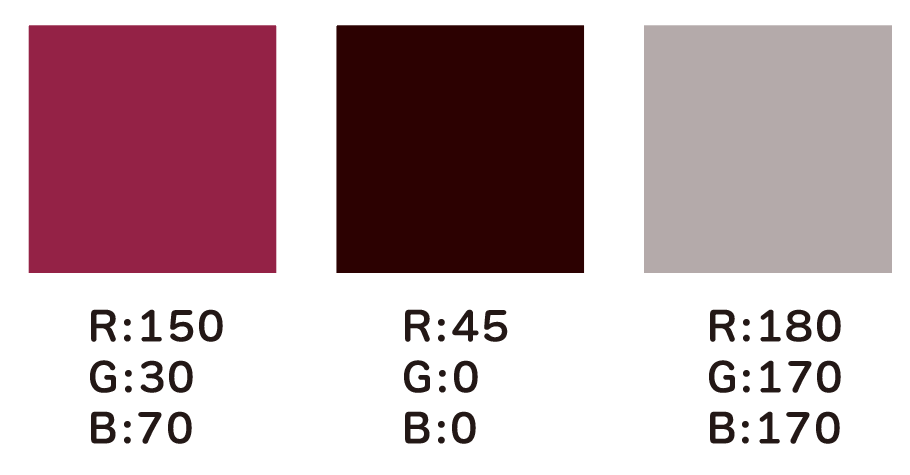
blue_mask = color_mask(image, lower_blue, upper_blue)
| サインペンのマスク画像 |
|---|
 |
非常に単純な処理ですが、いい感じに抜けましたね。
まだ「1ピクセルずつ青色っぽいかどうかを判断した結果」でしかないので、続いてどの座標にあるかを見ていきます。
これにはBlob処理(検出)を行います。Blobと呼ばれる画像内で互いに接続している同色のピクセル群を見つける処理になります。サインペンを表す白いマスクの塊が、画像中の度の座標にあるかを見つけていきます。
def draw_bounding_box_on_image(image, mask, color):
"""
マスク画像から輪郭を検出し、それらを結合して一つのバウンディングボックスを作成し、
元の画像に描画する関数。
:param image: 入力画像(BGRまたはRGB形式)
:param mask: マスク画像(白黒)
:param color: バウンディングボックスの色(BGR形式の色指定)
:return: バウンディングボックスが描画された画像
マスク画像から輪郭を検出し、すべての輪郭を結合して一つの大きなバウンディングボックスを作成します。
このバウンディングボックスは、元の画像に指定された色で描画されます。
"""
# マスクから輪郭を検出
contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 全ての輪郭を結合して一つの大きなバウンディングボックスを作成
all_contours_combined = np.vstack(contours)
x, y, w, h = cv2.boundingRect(all_contours_combined)
# バウンディングボックスを描画
output_image = image.copy()
cv2.rectangle(output_image, (x, y), (x + w, y + h), color, 3)
return output_image
Blobを検出してそれを囲うバウンディングボックスを描画しました。(画像はわかりやすく輪郭線も書いてあります)
たったこれだけの処理で、画像からサインペンの位置を見つけることができました。
| サインペンの検出結果 |
|---|
 |
鉛筆の検出
赤色の鉛筆もやることは同じです。
赤色の場合は、両端(0度と180度)が繋がっているのでそれぞれの端の色を指定して、マスクのorで結合します。
lower_red1 = np.array([0, 150, 50])
upper_red1 = np.array([10, 255, 200])
lower_red2 = np.array([170, 150, 50])
upper_red2 = np.array([180, 255, 200])
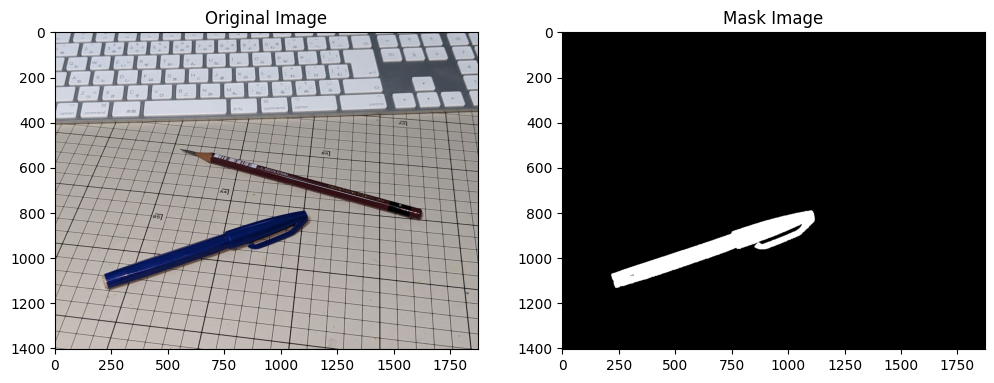
red_mask = cv2.bitwise_or(color_mask(image, lower_red1, upper_red1), color_mask(image, lower_red2, upper_red2))
red_mask = cv2.dilate(red_mask, np.ones((13,13), np.uint8), iterations=1)
バーコードの白い部分や鉛筆の硬さを表す部分の黒などがあるので、サインペンと違ってやや検出が甘いですね。
ラベル付けの精度を求められるケースでは厳しいですが、鉛筆の位置を取りたいだけなら十分でしょう。
| 鉛筆のマスク画像 |
|---|
 |
最終結果
機械学習を使用せず、赤い鉛筆と青いサインペンを検出することができました。
今回は色を使用したルールベース手法を使用しましたが、細長い物体なので形状や面積などを特徴として検出することも出来そうですね。
この様に、この物体を見つけるためにどのような特徴を使ってルール設定をしていくか考えていくのが、難しくもあり楽しい部分でもあります。
| 検出された最終結果 |
|---|
 |
おわりに
ディープラーニングから画像処理を始めた方にとっては、色相という考え方は新しいものだったのではないでしょうか。
ディープラーニングなどの先端技術は、複雑なタスクに対して驚異的な性能を示す可能性を持っています。しかし、基本的かつ古典的な手法も、ケースによっては効率的かつ効果的な解決策をもたらすこともあります。
技術選択においては、目的と状況に応じた適切なバランスを見極めることが重要です。単純な手法が適切な場合もあれば、複雑な技術が必要な場合もあります。
AI時代の技術力のポイントは、手段としての技術の選択ではなく、目的に合致した解決策を選ぶことができることなのだと思います。
技術力の新しさはそれ自体が価値となるべきではなく、どの様にそれを活用して価値を産み出すかが鍵となるのではないでしょうか。
明日は、@ntttx-suzuki-kyoheiによるAWSとMomentoの組み合わせに関する記事となっています。
引き続きNTTテクノクロスアドベントカレンダーをお楽しみください。