はじめに
この記事は、NTTテクノクロス Advent Calendar 2021 の10日目です。
こんにちは、NTTテクノクロスの広瀬です。普段は三次元点群や画像認識分野でAIの研究&開発を行っています。
さて、データサイエンティストではない方が、ビジネスで機械学習を使いたいという場面では、使用するアルゴリズムの数学的な理解よりも、手元のデータがそもそも使えるのかどうかや、どれくらいの性能が出るのかが知りたいのではないでしょうか。
そんな忙しいビジネスマンの強い味方がAutoML(機械学習の自動化)です!
本記事では、AutoMLによるローコード機械学習のご紹介 & 機械学習知識を使って性能向上に挑戦の二本立てでお送りします。
概要
機械学習を使ったシステムを考えていくと、図のように様々な工程が存在します。
| データ分析業務に必要な工程 |
|---|
 |
データ取得からとりあえず学習して評価するまでに、各工程でそこそこコードを書く必要があり、普段コードを書き慣れてない人からすると100行ちょっとでも大変な重労働になるのではないでしょうか。
データを読み込むためにpandasを覚えて、
前処理で何をする必要があるかを覚えて、ライブラリがなければ実装して
学習させるためにscikit-learnを覚えて、
可視化するためにmatplotlibを覚えて...
機械学習を勉強したいのにフレームワークの使い方を覚えるのに四苦八苦するよりも、混合行列の見方や性能の上げ方を学んだほうが有益だと思いませんか?
そこで本記事では、AutoMLツールの一つであるpycaret1を使ってKaggleのデータセットを捌きながら、その便利さをご紹介します。
それだけではつまらないので、多少データサイエンスを理解すると精度にフィードバックできるという、知識の重要さを示す意味でも、性能向上を狙ってデータやモデルをいじってみようと思います。
ローコード機械学習実践
とりあえずpipでpycaretと、Kaggleデータを扱うためにopendatasetsをインストールしましょう
pycaretは[full]オプションを付けてインストールすると、xgboostが使えるようになりますが、あれやこれや大量に依存するので、そこそこ時間がかかります。
$pip install pycaret[full] opendatasets
データの前処理
データをダウンロードして、前処理を行っていきます。
今回使用するのは、Kaggleの心不全推定のデータセットを使っていきます 2
import pandas as pd
from pathlib import Path
import opendatasets as od
# データ取得(要KaggleのID&PW)
od.download("https://www.kaggle.com/andrewmvd/heart-failure-clinical-data")
# CSVファイルをPandasのデータフレームに格納
dataset_dir = Path("heart-failure-clinical-data/heart_failure_clinical_records_dataset.csv")
datasets = pd.read_csv(str(dataset_dir))
読み込んだデータに対して前処理をしていきます。
目的変数の設定、データのシャッフル、Train,Test用のデータ分割、交差検証用の分割、乱数シードの固定etc...
from pycaret.classification import setup
_ = setup(data=datasets, target="DEATH_EVENT", train_size=0.8, session_id=0, silent=True)
おしまいです。
他にもデータの正規化やPCAによる次元圧縮、One-hot Encoding、データクラスタリングなどなどいろんな前処理がこの関数一つで実施できます。
便利ですねぇ。。。
モデルの選択、チューニング
じゃぁ、どんなモデル使って行こうかなーというのも、お任せすることが出来ます。
更にハイパーパラメータチューニングもおまかせ出来ます。
いろんなモデルで推論 & 精度比較
from pycaret.classification import compare_models,tune_model
# 上位3つを使うことにする
models = compare_models(n_select=3)
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT(Sec) | |
|---|---|---|---|---|---|---|---|---|---|
| rf | Random Forest Classifier | 0.8493 | 0.8985 | 0.6768 | 0.8223 | 0.7224 | 0.6241 | 0.6432 | 0.3180 |
| ada | Ada Boost Classifier | 0.8453 | 0.8906 | 0.7196 | 0.7739 | 0.7343 | 0.6279 | 0.6376 | 0.0630 |
| catboost | CatBoost Classifier | 0.8409 | 0.8958 | 0.6607 | 0.7830 | 0.7017 | 0.5989 | 0.6120 | 0.9860 |
| ridge | Ridge Classifier | 0.8373 | 0.0000 | 0.7018 | 0.7639 | 0.7084 | 0.6012 | 0.6165 | 0.0060 |
| lr | Logistic Regression | 0.8288 | 0.8545 | 0.6071 | 0.8118 | 0.6745 | 0.5658 | 0.5874 | 0.0180 |
精度が高かったもの更にチューニング
一番Random Forestが良さそうです。
チューニングしたいモデルを選択したら、チューニング & 10Fold Cross Validationをしていきますが、たった1行で完了です。 Accuracyは0.8493 → 0.8536にちょっと上がりました。
tuned_model = tune_model(models[0], tuner_verbose=False)
| Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | |
|---|---|---|---|---|---|---|---|
| 0 | 0.9167 | 0.9244 | 0.8571 | 0.8571 | 0.8571 | 0.7983 | 0.7983 |
| 1 | 0.7917 | 0.8025 | 0.2857 | 1.0000 | 0.4444 | 0.3617 | 0.4699 |
| … | |||||||
| Mean | 0.8536 | 0.8594 | 0.6786 | 0.8321 | 0.7208 | 0.6291 | 0.6511 |
| SD | 0.0677 | 0.0751 | 0.2288 | 0.0980 | 0.1575 | 0.1873 | 0.1676 |
可視化(Visualize)
チューニング結果を可視化してみるのも簡単です。
matplotlibで頑張る必要はありません。
from pycaret.classification import plot_model
plot_model(tuned_model, plot="feature")
plot_model(tuned_model, plot="auc")
plot_model(tuned_model, plot="confusion_matrix")
| 特徴量重要度 | RoC Curves | 混合行列 |
|---|---|---|
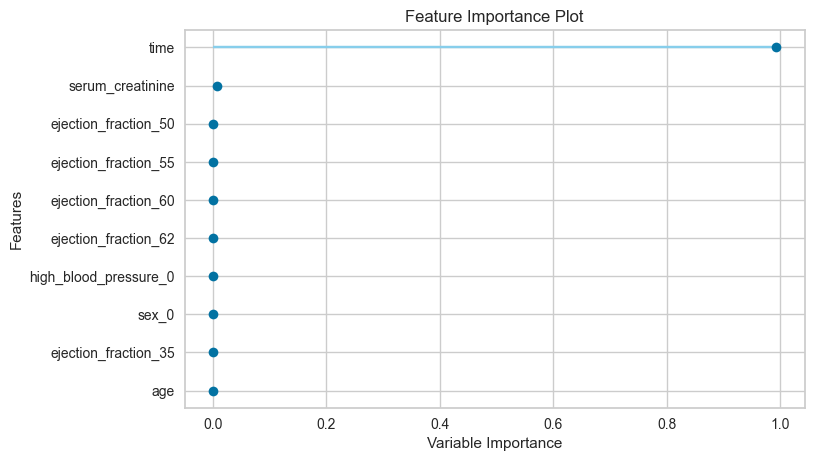 |
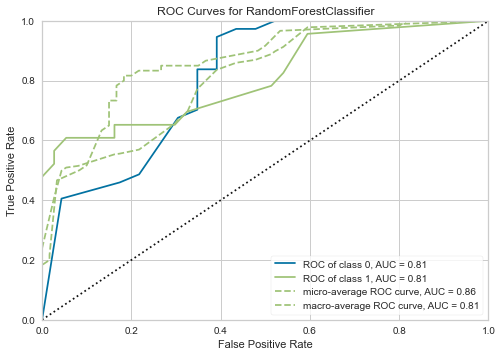 |
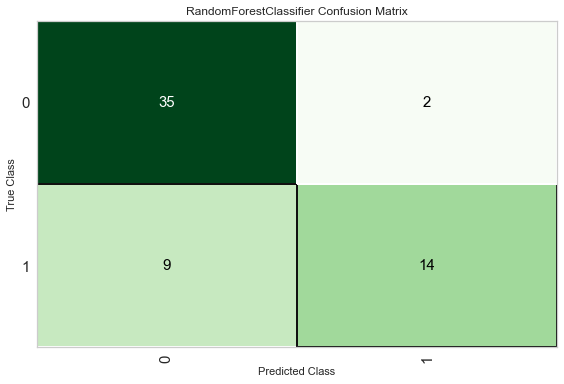 |
ここからが本番!更にチューニング!
データセットを読み込んだら、importを除いた5行くらいで前処理から可視化まで終わってしまいました。
簡単すぎて薄っぺらい内容になってしまったので、知識を導入して性能向上を狙いましょう。
結果だけ気になる方は↓まで飛ばしてOKです!
前処理の追加
特徴量の選択
特徴の重要度を可視化ところ、殆どの特徴が決定に大きな影響を与えていなさそうだったので、思い切って削除してしまいましょう。
念の為目的変数との相関を確認して見ましたが、5個ぐらいの変数が残っていれば良さそうです。
| CatBoostで試した重要度 |
|---|
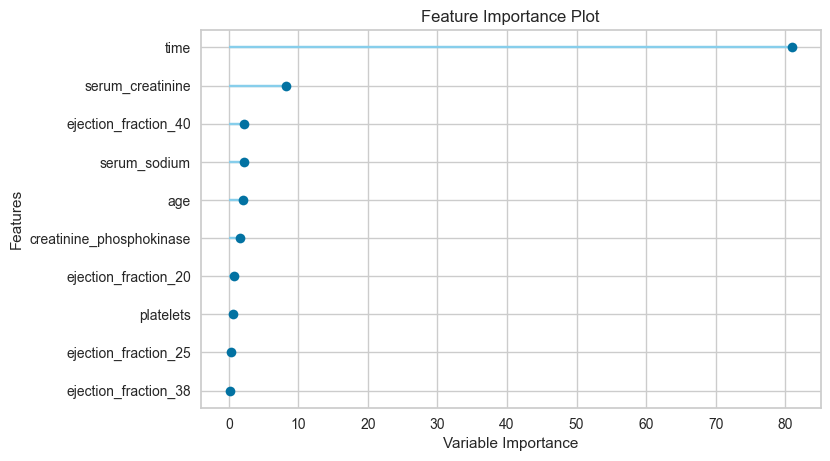 |
# 目的変数との相関もチェック
corr_sr = datasets.corr().DEATH_EVENT[:-1]
corr_sr[corr_sr.abs() > 0.1]
| age | ejection_fraction | serum_creatinine | serum_sodium | time |
|---|---|---|---|---|
| 0.253729 | -0.268603 | 0.294278 | -0.195204 | -0.526964 |
おまかせにしていた前処理の内容チェック
変数を削除してsetup関数を通し直したら、ejection_fractionがカテゴリカル変数となっていました。
ejection_fractionは駆出率という割合を表す値なので、カテゴリカル変数は適切ではありません。Numericにしましょう。
値を正規化していくことを考えると、変数ageの40歳が0になってしまうとやや気持ち悪いので、こちらはCategoricalにしましょう。
| Data Type(修正前) | Data Type(修正後) | |
|---|---|---|
| age | Numeric | Categorical |
| ejection_fraction | Categorical | Numeric |
| serum_creatinine | Numeric | Numeric |
| serum_sodium | Numeric | Numeric |
| time | Numeric | Numeric |
datasets_df = datasets[["time", "serum_creatinine", "ejection_fraction", "serum_sodium", "age", "DEATH_EVENT"]]
setup(data=datasets_df, target="DEATH_EVENT", train_size=0.8, use_gpu=True, session_id=0, normalize=True, numeric_features=["time","serum_creatinine", "ejection_fraction", "serum_sodium"], categorical_features=["age"], verbose=False, fold=5)
モデルの選択
KaggleといえばXGBoost!なところもあるので、流行に乗っかってこいつをチューニングしていきます。
自動に任せたらバギングなRandom Forestが選択されたので、対抗してブースティングを使うアルゴリズムで性能を超えていきましょう。
Random Forestはチューニングしても少ししか上がりませんでしたが、xgboostは0.03以上の精度向上が出来なければ勝てません。
||Model|Accuracy|AUC|Recall|Prec.|F1|Kappa|MCC|
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
|rf|Random Forest Classifier|0.8536|0.8594|0.6786|0.8321|0.7208|0.6291|0.6511|
|xgboost|Extreme Gradient Boosting|0.8201|0.8860|0.6533|0.7477|0.6722|0.5527|0.5737|
いざ、チューニング!
まずは、チューニングのイテレーション数がデフォルト10は少なすぎるので300に増やしていき、過学習を防ぐ為にearly stoppingを有効化します。
パラメータ探索アルゴリズムがデフォルトではランダムグリッドサーチとなっているので、scikit-optimizeで拡張してベイズ最適化を適用することにしました。
from pycaret.classification import create_model
xgboost = create_model("xgboost")
xgboost = tune_model(xgboost, n_iter=300, early_stopping="Hyperband", early_stopping_max_iters=30, search_library="scikit-optimize", search_algorithm="bayesian", tuner_verbose=False)
チューニング結果は?
大幅に性能が向上して、無事にRandom Forestを抜くことが出来ました👏
||Model|Accuracy|AUC|Recall|Prec.|F1|Kappa|MCC|
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
|rf|Random Forest Classifier|0.8536|0.8594|0.6786|0.8321|0.7208|0.6291|0.6511|
|xgboost|Extreme Gradient Boosting|0.8787|0.9292|0.8333|0.8060|0.8090|0.7209|0.7319|
更にチューニング
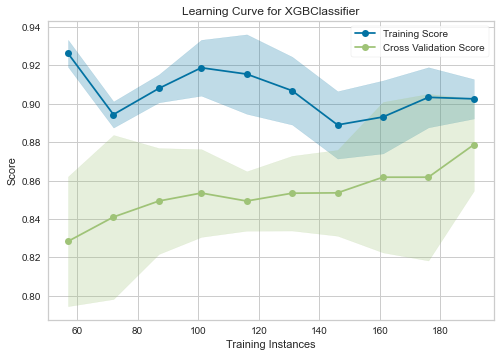
性能が上がり満足したのでチューニングをお終いにしてよいかを確認するために、pycaretの可視化機能で学習曲線を描いてみましたが、もう少し改善の兆しがありそうです。
年齢の変数をどうするか迷ってCategoricalにしていたのですが、影響度も低かったのでいっそのこと省いてみましょう。これで変数は4つ、全てNumericな値となりました。
| XGBoostの学習曲線 |
|---|
 |
ignore_age_df = datasets_df[["ejection_fraction", "serum_creatinine", "serum_sodium", "time", "DEATH_EVENT"]]
ignore_age_prepare = setup(data=ignore_age_df, target="DEATH_EVENT", train_size=0.8, use_gpu=True, session_id=0, normalize=True, numeric_features=["ejection_fraction", "serum_creatinine", "serum_sodium", "time"], verbose=False, fold=5, silent=True)
# 実験としてcatboostも試してましたが、初期値はcatboostのほうが上でした。全部numericな値なのに。。。
ignore_age_model = compare_models(["xgboost", "catboost"], n_select=2)
ignore_age_xgboost = tune_model(ignore_age_model[1], n_iter=300, early_stopping="Hyperband", early_stopping_max_iters=30, search_library="scikit-optimize", search_algorithm="bayesian", tuner_verbose=False)
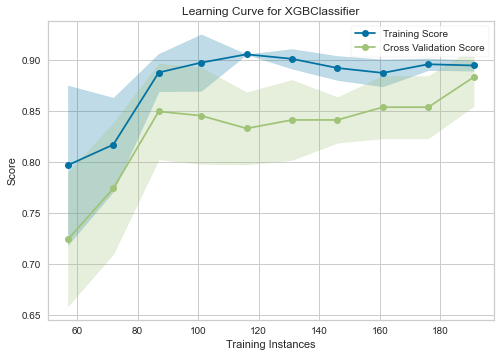
さらなるチューニング結果
狙い通りAccuracyが上がったので、さらなるチューニングは成功です!
何も考えずに機械学習を扱えるのは非常に便利ですが、やはり精度への寄与はデータサイエンティストによるハンドリングが大切ですね!!!
||Model|Accuracy|AUC|Recall|Prec.|F1|Kappa|MCC|
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
|xgboost(Before)|Extreme Gradient Boosting|0.8787|0.9292|0.8333|0.8060|0.8090|0.7209|0.7319|
|xgboost(After)|Extreme Gradient Boosting|0.8828|0.9183|0.7924|0.8323|0.8014|0.7191|0.7290|
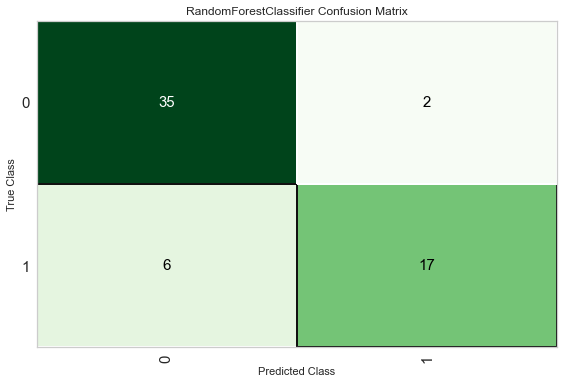
| 学習曲線 | 混合行列 |
|---|---|
 |
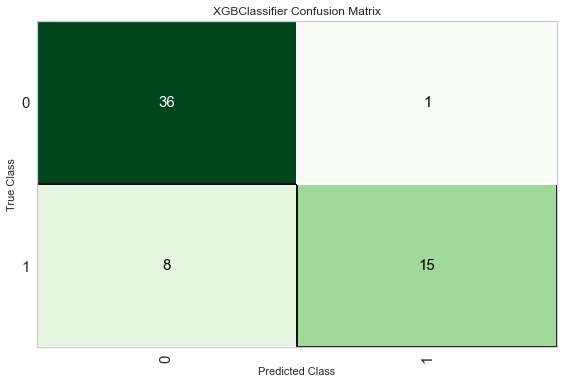 |
おまけ
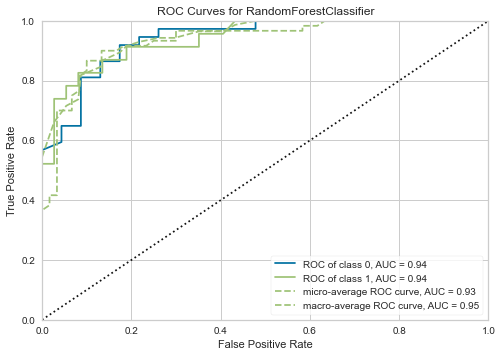
前処理をちゃんとして、Random Forestでチューニングしたらどうなるかは↓のとおりです。
もちろんこちらもぐいっと精度が上がりましたが、ほとんどXGBoostと変わりませんね。どちらも決定木系のアルゴリズムなので、このあたりがこのデータでの行き着くゴールということでしょうか。
||Model|Accuracy|AUC|Recall|Prec.|F1|Kappa|MCC|
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
|xgboost(After)|Extreme Gradient Boosting|0.8828|0.9183|0.7924|0.8323|0.8014|0.7191|0.7290|
|rf(After)|Random Forest Classifier|0.8827|0.9058|0.7781|0.8314|0.7978|0.7157|0.7218|
| RoC Curves | 混合行列 |
|---|---|
 |
 |
おわりに
AutoMLのちからによって、非常に少ないコード量で手元のデータに機械学習を適用できることがご理解いただけたでしょうか。
一方で、事前処理やモデルの選択などはエンジニアがしっかりと知識をつけてハンドリングしないと十分な性能が出せない事もご理解いただけたかと思います。
AutoMLは、現在自動化出来ていない選択の部分までも自動化することを目標に日々研究が進んでいる分野です。
今はまだ我々人間の手が必要不可欠となっていますが、自己再生・自己増殖・自己進化の未来も遠くないのかもしれません。
本記事はここで終了です。
明日は@kn-tomによるPostgreSQLに関する記事をお送りします。引き続きNTTテクノクロスアドベントカレンダーをお楽しみください。