Nutanix Advent Calendar 2枚目 12/23 です。
https://adventar.org/calendars/4014
ツール紹介
背景
Nutanix Advent Calendarのひとつとして、Nuatnix Japanで開発しているツールを紹介します。
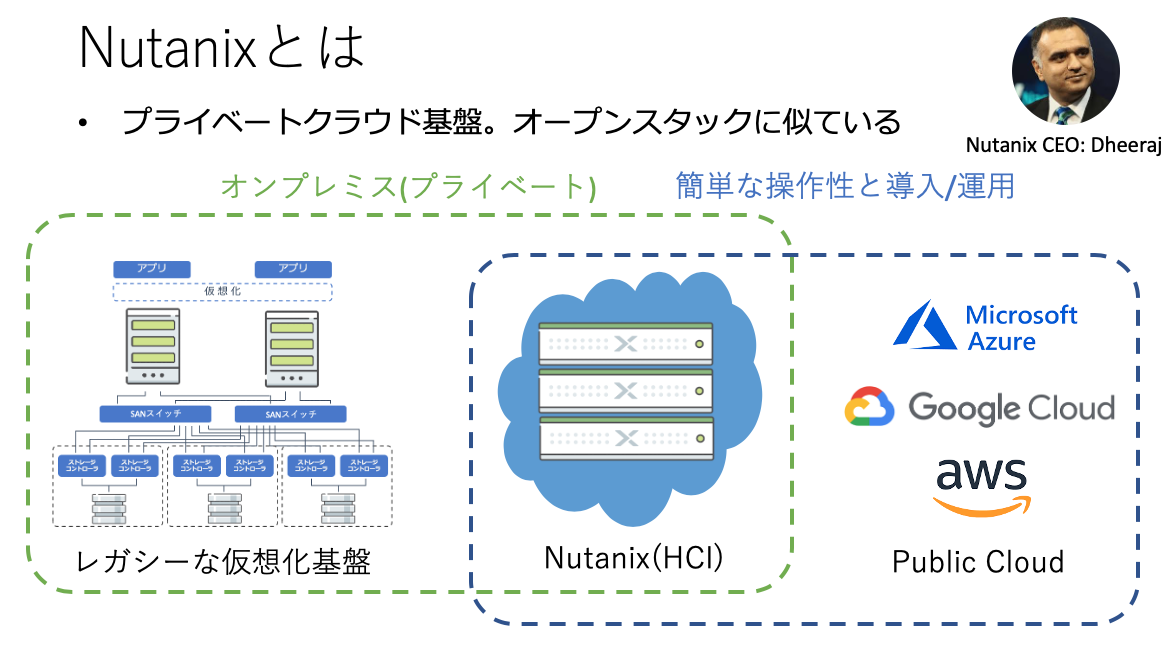
この記事を読まれているぐらいなのでNutanixについてはご存知かもしれませんが、Nutanixはオンプレミス上にクラウド基盤を構築するHCI(Hyper Converges Infrastructure)ソフトウェアです。超簡単なオープンスタックだと思ってもらえばよいかもしれません。
Nutanixの基本機能の紹介は他の記事にゆずります :)
私は仕事でNutanix Japan POC(ラボ)の設計/管理と、スペシャリストとして開発周り全般(DevOpsとAPIによる自動化、DevNet(Developer Network)や開発パートナー会社との関係構築)を担当しています。最近はパブリッククラウドの会社と連携して、ハイブリットクラウドを作れるパートナー様を増やす仕事もしています。今は開発関係が仕事の半分ですが、もともとは超インフラよりのエンジニアで「データセンターネットワーク全般(2011年4/1。Ciscoに新卒入社) -> サーバー仮想化全般(2016年1/1にNutanixに転職) -> 開発とクラウド全般(2019年8/1にポジションチェンジ)」と専門を変えてきています。
仕事の関係で「Nutanixクラスタをトレーニングなどで外部に提供するごとに、クリーンに新規構築する」ということが発生していました。操作量自体はさほど多くなくてゼロから2-3時間で完了するのですが、なにぶん回数が多くて1週間に2-3回クラスタを新規構築することなどはざらです。人間がやると超めんどいです。
そういった背景と「外部にNutanixの自動化ソリューションを紹介できるリファレンスが必要」ということで、「Nutanixのクラスタの状態を監視し、Foundationによりベアメタルからクラスタを自動構築し、安全にサーバーの電源OFF/ON(クラスタ起動まで)」できるツールをDevOpsスタイルで開発して利用しています。
他にもツールは作っているのですが、Nutanixっぽいこの「Founder」というツールを紹介し、アーキテクチャーや開発技法についても説明します。
もし、開発技法の詳細が知りたい場合は来年の春に技術評論社さんから「Docker/Kubernetesの入門本(タイトル未定)」を出版する予定なので、そちらを買ってくれるとうれしいです。Nutanixで蓄積したDockerやKubernetesの使い方や、それらを使ったDevOpsスタイルの開発技法についてがっつり書いています。開発トピックの割合がおおいので入門書ではないような気がしていますが、まぁOKでしょう。。。w
ツールについて
脱線はこのあたりにして、本題のツールの紹介です。
このツールは以下のようなUIを持っています。

詳しくはアーキテクチャー編で紹介しますが、VueというJavaScriptのフレームワークを使ったSPAの画面です。
左からクラスタ名、所属するネットワークセグメント、代表IPとなります。
続くチェックマークは左から「そのネットワークにIPMIが存在するか(MACアドレスで調査)」「ホストのIPにリーチャビリティがあるか」「クラスタにログインできるか」が続きます。赤が失敗で、グリーンが成功です。赤いのは出荷(お客さんに貸し出し)しているので物理的に存在しないか、セットアップされていないかのいずれかです。そしてクラスターのバージョンとハイパーバイザーの種別が続きます。
Actionsがメインとなる操作画面で「Start」は、電源が停止されているサーバーをIPMI経由で電源ONし、ホストとCVMがたちあがったらクラスタ起動をおこないます。
同様に「Stop」は上で動いている仮想マシンやサービスを順に停止していき、全てとめたらクラスタを停止して、CVMとホストの電源をおとして完全OFF状態にします。電気代の節約は大事です:)
最後のFoundationが少しおおがかりで選択すると以下のような画面が表示されます。

選択したクラスタをどのようなパラメーターでイメージング(初期化)するかのパラメーターを埋め、「Start Foundation」ボタンを押すとイメージングが開始されます。
イメージング作業は「NutanixのFoundation VMでベアメタルファウンデーション(IPMI経由で0からイメージング)」をおこない、それが完了してから「EULAの設定(機器の管理者や、テロなどの変なことに使いませんよというサイン)」をおこない、クラスタが使えるようになったら「言語を日本語にし、デフォルトのコンテナやネットワークを作成し、仮想マシンのイメージ(テンプレート)をアップロードする」ということを順番に勝手にやってくれます。
イメージングを開始すると、画面上部の「Tasks」よりタスクの進捗状態をチェックできます。

あとは画面の上部にあるのですが、自作のAnsible Towerのような機能もつけており、保存されているPlaybookを選択し、それを仮想マシンのIPとクレデンシャルを入力して適用するという趣味機能ものせています。
ツールアーキテクチャ
このツールはDockerのコンテナベースで作成されています。
そこそこ大きなサイズのツールですので、モノリシックなアーキテクチャで作るとメンテナンスが大変です。そのため、マイクロサービスアーキテクチャらしき構造をしています。
コンテナの役割と、コンテナ間の連携とはおおまかに以下の図のようになります。
(2019年9月に実施した.Nextというイベントで使ったDevNetの資料です)

ツールはおもに3つのコンポーネントから構成されます。
DB、アプリ、ウェブという典型的な3階層アプリです。
ホストとしてはKubernetesではなく、
1つのホスト上にDocker-Composeで定義したとおりに展開させています。
仮想マシンですので、バックアップはストレージスナップショットを別クラスタに飛ばすという簡単な手法です。
DBコンテナ
DBコンテナはPostgresのDockerの公式イメージを使っています。
特別な使い方はしておらず、データベースの内容はVolumeとしてホスト上にディレクトリとして保存されます。
そのため、VMレベルでバックアップをとれば、この領域もバックアップされます。
昔のVMを復元すればDBももとの状態にもどるという、雑ですがよくある構成です。
ウェブコンテナ
前面にあるコンテナはNGINXから構成されています。
少し面白いのは開発時は「NGINXとNode.JS」の2つのコンテナをウェブとして使っている点ですが、その理由は開発技法セクションで扱います。
NGINXは静的なページ配信にHTMLサーバー機能を使い、API(URLが/api/v1/から始まる)にたいするアクセスはリバースプロキシー機能で後ろにいるアプリケーションのコンテナ(Django)に転送します。
Vue.JSはこの時点ではビルドされ、静的なファイル(HTML,CSS,JavaScript,画像)に変換されてNGINXからHTMLサーバー機能で配信されています。
このウェブコンテナが配信するVueのコードが、さきほど紹介したツールのGUIを構築しています。
Vue内部ではajax(jQueryではなく、Axios)を使って動的にAPIをサーバーとやりとりしています。
サーバーから送られたデータを受け取り、内部データを更新するとVueのSPA機能で勝手に画面が更新されます。
アプリケーションコンテナ(コア)
図にあるようにアプリケーションサーバーはメインのDjangoコンテナと、
それに使われる小さなコンテナ群により構成されています。
これがマイクロアーキテクチャと呼ばれる構造となります。
なにも考えずにアプリケーションを作成すると、アプリケーションサーバーの仕事がどんどん増えていき内部の構造が複雑になっていきます。もちろん、プログラミングのテクニックを使うことで疎結合な設計にすることはできますが、求められる技術的な難易度は高く、開発者全員がそのレベルにいることは期待できません。
マイクロアーキテクチャを採用すると、疎結合な設計が強制されます。
どこにどうデータをもたせるかという設計は難しいところがありますが、
コアはコンポーネントとなるマイクロアーキテクチャのコンテナを呼び出す処理を実装し、
「共通データ」と「各マイクロコンテナがそれぞれ必要とするデータ」を管理するという構造を私はよく採用しています。
マイクロサービス自体にデータをもたせたほうがコアコンテナの仕事は減るというメリットはありますが、
そのような設計をとると「単純であるべきマイクロサービスが状態を持って使い捨てしたり、並列展開しにくくなる」というデメリットが発生します。
トレードオフを加味して、設計を決めてください。
弊社のツールですと、コアは以下のようにマイクロコンテナを順に呼び出しています。
(1)連携の絵

(2) イメージングステップ

(3) Eula設定ステップ

(4) クラスタ初期設定ステップ

アプリケーションコンテナ(マイクロ)
コアとなるアプリケーションサーバーは重要なコンポーネントですので、
PythonのウェブのフルスタックフレームワークであるDjangoを使っています。
認証まわりの実装などが必要な場合はフレームワークがその機能を提供できますし、
データベースなどをがっつり使うための機能は便利です。
ただ、マイクロアーキテクチャの「小さなコンテナ」はDjangoのような大きなフレームワークよりも、
Flaskのような軽量なフレームワークのほうが手軽に開発できて便利です。
テスト環境を除いて外部から直接利用されることはないので、認証機能は搭載しませんし、
外部依存をへらすために永続化やデータベースの利用などは一切使っていません。
ただ、状態としては単純ですが弊社のマイクロコンテナはそこそこ複雑なアーキテクチャーとなっており、
それは以下のようなものです。
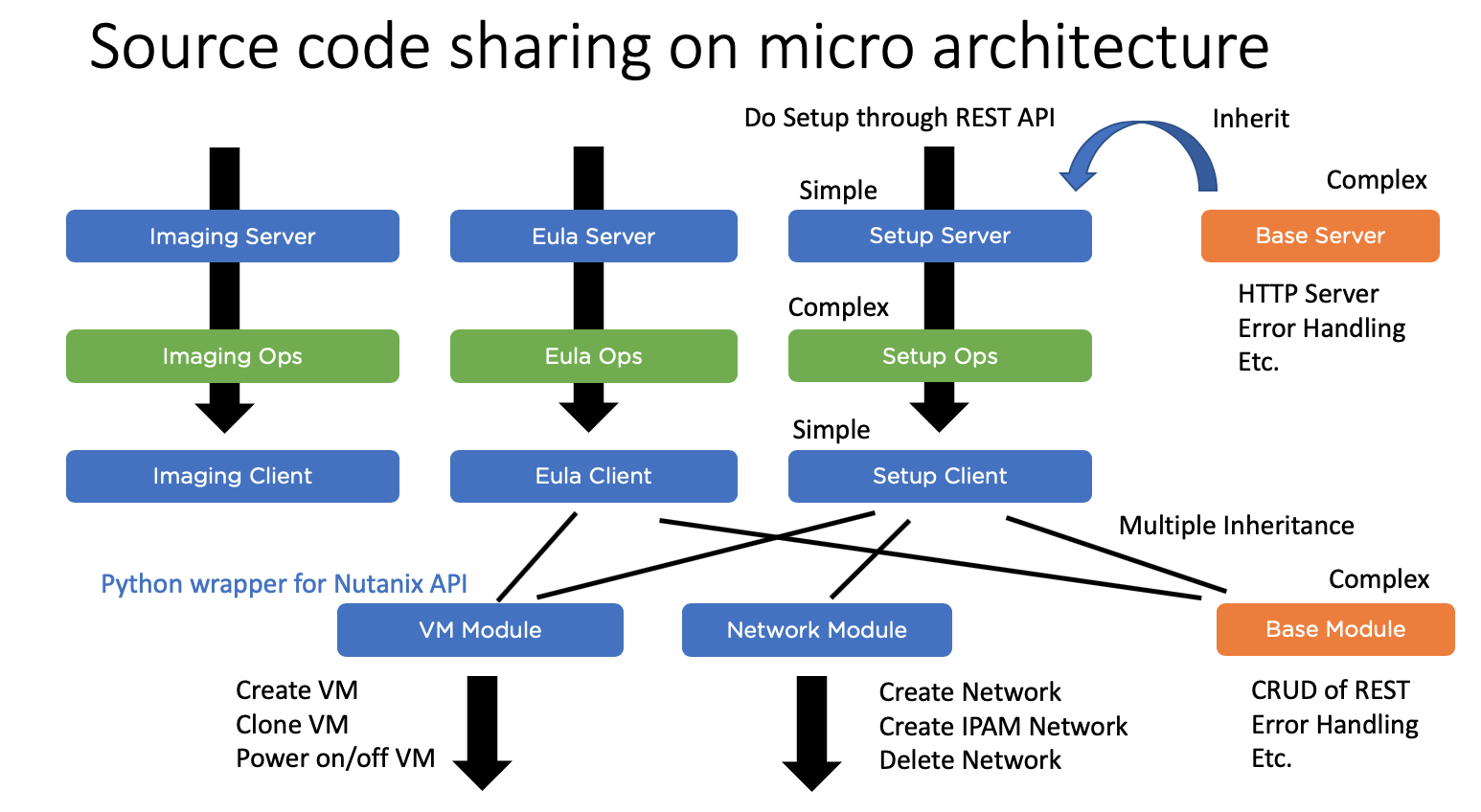
Dockerfileとソースコードの配置は以下のようなものです。
ファイル数が多いので下は見切れています。

全てのコンテナは全て同じような設計です。フロントとなるFlaskサーバーがいて、それがコアからリクエストを受け付けるとタスクを作成し、そのタスクは外部を操作するクライアントを利用するという流れです。そのため、Flaskに必要な全コンテナ共通機能(エラー処理や、コアへの進捗連絡)は親クラスに実装し、それを各コンテナが継承して差分(どのタスクを作成するか、渡されたデータのデシリアライズなど)を実装するという設計にしています。クライアントも1つの巨大な機能をもつクラスを作るのではなく、REST APIのラッパーをコンポーネントごとに作成して、各コンテナが持つクライアントが多重継承により必要機能を取り込むという設計です。
中央のOps(Operations, タスク実行)は各コンテナごとに全く違うので継承せずに個別実装しています。
このようにバラバラに分けて開発すると、コンテナごとに独立した開発者(責任境界点が明確だし、少人数で素早く開発可能)をつけつつ、共通コンポーネントを持つことで車輪の再発明を防げます。全体のコンテナ間の連携の設計と、コアおよび共通コンポーネントは上級エンジニアが担当すべきでしょう。
開発手法
この内容は丁寧な説明と具体的なコードとともに2020年春に出版するDocker/Kubernetes本で説明します。詳細を知りたいかたは本を買ってください:)
CI/CDパイプライン
弊社のツールはDockerベースで開発しており、そこそこコンテナの数もあります。
これを手動で展開すると日が暮れてしまいますので、Jenkinsのパイプラインを構築してCI/CD環境をつくっています。よくみるDevOpsの無限(∞)マークの絵でいうと、使っているツールはほぼDockerです。

この流れを各ステップごとに記載した絵が、以下となります。

まず、ローカル環境(私の場合はMac + Docker for Desktop)で開発し、それをDocker-Compose(以下Compose)とDockerfileでビルドして、テストを実施してから、ソースコードリポジトリ(GitHub)にPushしています。大事なのはテストをパスしない品質の低いコードはPushしないことです。また、ローカル環境(超汚い)で作ったイメージは他の環境で動くという保証はないので、このイメージは本番環境ではつかいません。
GitHubにPushされると、JenkinsはCI/CDパイプラインを起動します。
コードのなかにJenkinsfile(パイプラインの定義)があるので、パイプライン自体もコードで管理されています。Jenkins as a Code!!
Jenkinsの最初の仕事は更新されたソースコードから、ビルド環境でイメージをビルドすることです。このJenkinsにはDocker Clientがインストールされているので、リモートのビルド環境を「docker-compose -H 接続ホスト コマンド」を使って操作します。
ビルド環境はユーザーのローカル環境と違って綺麗なので、そこで作成されてテスト(ユニットテスト + Selenium)にパスしたイメージは綺麗とします。そのため、そのイメージは本番で使えるとしてDockerHubのリポジトリにタグ(バージョン。タイムスタンプ)をつけてPushします。
Jenkinsはビルド環境でのイメージ作成に成功したので、本番環境で信頼できるイメージからコンテナを展開します。
コンテナの展開にもdocker-composeを使います。このサービスはいきなり更新して問題ないので、凝ったデプロイ方法は使っていません。
効率的な開発手法
Dockerを使うことで、WindowsのうえでもLinuxベースのアプリケーション開発をおこなえます。ただ、一般的にはアプリケーションを展開するには「コードを書く -> イメージ化する -> イメージをコンテナ化 -> コンテナを確認したりテストする」というステップが必要です。
WindowsやMacのうえでアプリケーション開発していれば、「コードを書く -> 動かしてチェック」とできますので、コンテナでの開発は少々面倒です。
弊社での開発では、このような問題に対処するために「開発時はホスト上のコードをBindでコンテナ上に直接のせる(ホストのファイルを更新したら、コンテナ上のファイルも更新される)」方式を使い、実際に利用するイメージはコードをCOPYしてイメージに取り込んでBindは一切しません。
こうすることで、開発時はソースコードを変更して挙動を即時確認して迅速な開発ができます。また、実際にコンテナを使う場面ではコード変更は発生しないのでイメージ内に直接埋め込んで、どこでも動かせるポータビリティを確保しつつ、外部から一切タッチできないようにしています。
この構成はシンプルなHTMLの開発では以下のようになります。

まず、ローカルでの開発とビルドの両方で共用されるDockerfileではHTMLのコードをイメージに直接取り込んでいることです。
面白いのは、開発用とビルド用にdocker-composeファイルが2つ用意されていて、開発版のファイルでのみ「イメージ上のHTMLの領域を、ホストのHTMLディレクトリでBindを使って上書きする」という使い方をしている点です。
一方、ビルド用のcomposeファイルではBindでの上書きをしていません。
こうすることで「開発環境ではホストのソースコードをマウントし、すばやく開発できる」かつ「ビルド時はソースコードを埋め込んで、ガッチリ固めたイメージを作れる」という場所に応じた使い方ができます。
なお、厳密にいうと開発用のcomposeファイルでもBind前のイメージはコードをCopyして取り込んでいるので開発版と同じですが、他のパラメーターに違いがあったり、明確にビルドを開発用か本番作成用かを区別するためにファイルを分けています。
新しいインフラと開発手法
最後に私からみたインフラと開発の歴史的なところと、2020-2025あたりに流行りそうなトレンドについて紹介します。間違っていたら本になるまえに指摘して頂けると助かります!!
インフラの歴史
おもにデータセンター系をずっとやってきているので、それよりな歴史感ですが、おもに以下のような流れがありました。
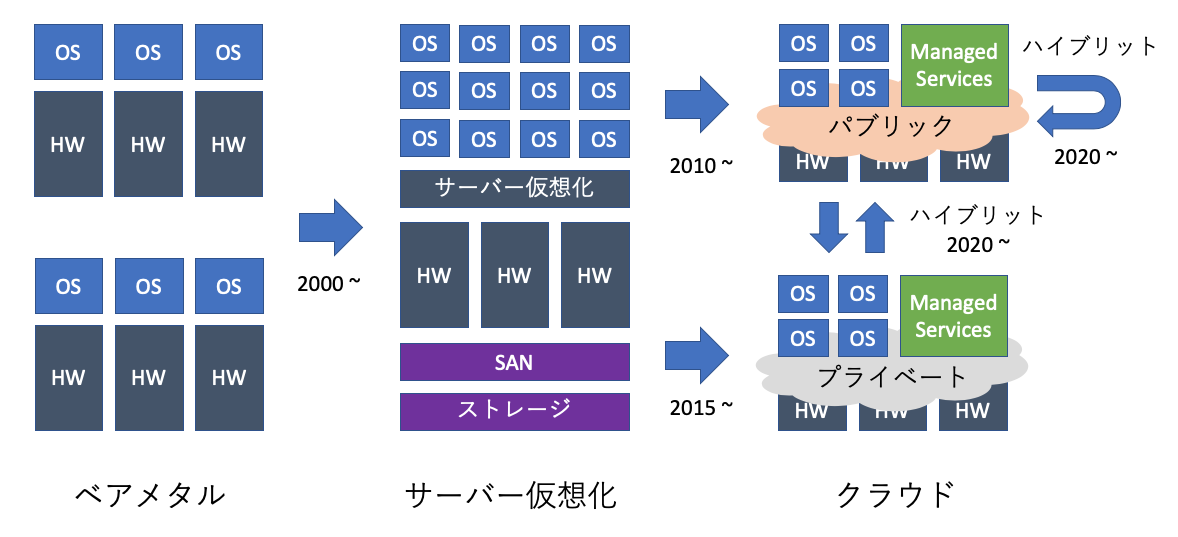
大雑把にいうと、最初はベアメタル中心だったものが、ハードの性能向上とリソースのプール化のメリットを最大限に使える仮想化が最初のおおきな変化でした。
ただ、冗長性も考慮したレガシー仮想化(3tier)は私もやっていたのですが、ひとことで言えば超難しいです。SANやストレージの設定変更は難しいわりに、やらかした影響が最悪なのであまり触りたくありませんでした。
おおよそ2000から2005年あたりだった気がしますが、大きく状況が変わったのはVMwareのvSphere(当時はESXiではなくESX)がでたあたりだと思います。
そういった状況にパブリッククラウド(AWS)が出始めて、気軽にマシンを動かしたいウェブ系(インターネットに近いほうがよい)が飛びつき始めたのが2010年あたりだと思います。ただ、ご存知のように全てのワークロードがパブリックに適するわけではないので、AWSやAzureを使いたいけど台数が多いので高すぎたり、そもそも出せないシナリオでオンプレミスのクラウドが使われ始めました。これが2015年あたりです。(このトレンドを当時は感じたので思い切って、ネットワークエンジニアからプライベートクラウドの会社に移っています)
クラウド業界で働く人はおよそ2018年あたりからハイブリットクラウド(複数クラウドの利用)に向けて動き出していますが、これがインフラ的な次のトレンドになると考えています。パブリッククラウドがオンプレミスに乗り出したり、オンプレミスがパブリッククラウドに乗り出したりしているのが顕著な例ですし、マルチクラウドの製品を多くの会社が頑張って売ろうとしています。
開発の歴史
開発の歴史は、いろいろな分野があるので一概には言えませんが、おおまかには以下の図のような流れがあると考えています。
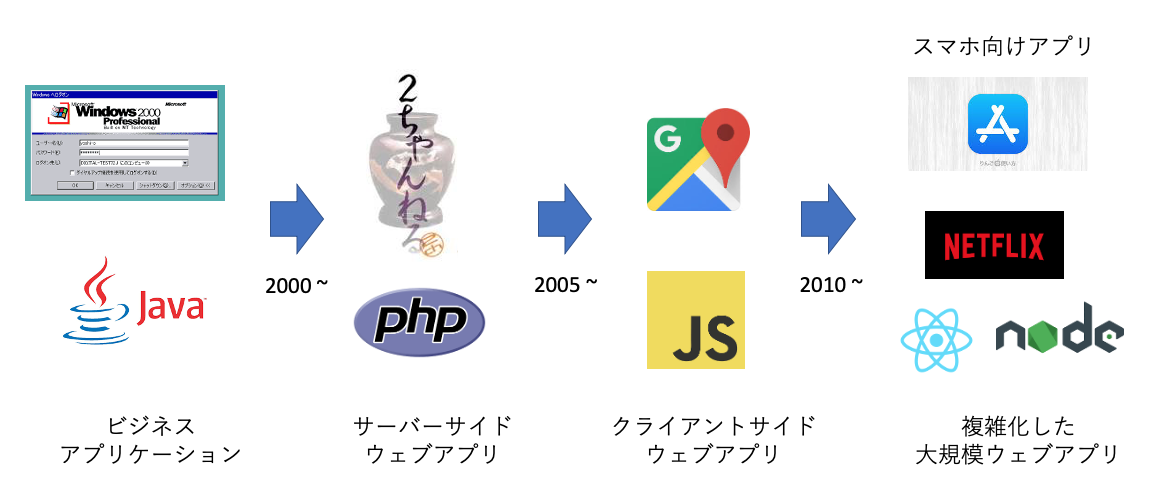
最初はアプリケーションはデスクトップで動かすWindowsアプリや、ブラウザベース(IE!!)であっても企業内のものが多かったです。2000年あたりからPHPやPerlを使ったサーバーサイドの動的なアプリが出始めました。
状況が大きく変わったのがGoogleMapのような「ページを更新しなくてもデータをやりとりして更新できるブラウザアプリケーション」の登場です。これがおよそ2005年ぐらいかと思います。
技術的にはAjaxを使って、クライアントサイドで描画を変える、Javascriptベースのサービスです。
このあたりからウェブ開発は明確にフロントとバックエンドが分かれました。
現在はウェブではないのですが、比較的それに近いスマホのアプリ(配信や使い方は全然違いますが、その思想はかなり似ています。最近はバックエンドも共有していたりしますし)の開発が流行していますし、GoogleやFacebook、Netflixのような超大規模なサービスが展開されています。
そこまででかくなくても、有名サービスであれば相当なトラフィックが流れています。
大規模化したことに加えて、サービスは複雑化しはじめました。
2015年あたりから大きく使われ始めたSPA(Single Page Application)などは、その顕著な例です。
しかも、これらのアプリケーションはリリースサイクルがかなり早く、一週間に一度以上更新されることも普通です。
ようするに「でかくできて複雑なアプリを、トラブルなく頻繁にリリースする」という要望が高まっているということです。それができないと、ウェブサービスで負けてしまいます。
新しい開発と運用方式
こういったインフラと開発の背景から、2015年あたりから徐々に以下の図の右の構成を先進的な会社は取り込み始めています。

あまり日本では有名なたとえではありませんが、「ペット VS 牛」というたとえをDevOpsに関わる外国人はよく使います。ペットはかけがえのない存在で、それが病気になると頑張って治そうとしますし、死んでしまうとすごく悲しいです。今までの開発/運用をすると、「インフラやサービスがどんどんペットになる」状況になります。
「俺の大事なVMを面倒みるぜ、いくらコストがかかってもな!!」「俺の大事なVMは簡単に変更できないぜ、いままでいっぱい世話をしてデリケートだからな!!」という感じです。
一方、アメリカ人の牛にたいする思いはあきらかにペットとは違います。死んだら悲しむでしょうが、それは牧場のビジネスには影響が発生しません。牛は番号で管理され、病気になったら処分されて終わりです。牛は利益を生み出す「置き換えることができる存在」なのです。(私は牛は好きですよ。別に牛に恨みはありませんよ!!)
新しいインフラや開発では、そのコンポーネントひとつひとつを「牛」として扱えることを目標とします。そのためにはVMを作るのは手動ではなくAnsibleを使い、アプリケーションのビルドや展開にはコンテナを使います。
また、データベースのような難しいサービスは、いっそ頑張るのではなく「金を払ってマネージドサービスを使って省力化しよう」という方向に動くひとたちも増えています。
こういった方向で動くことを想定して、勉強したり、スキルをつけたり、組織を作っていくのがいいのではないかなーと最近感じることがおおいです。
以上、私の今年のパートはおわりです。