Power BI はスタースキーマを目指してモデリングをする。
これは Power BI を使用するすべての人が守らなきゃいけないこと。Power BI はモデルがスタースキーマになってることを前提に作られているから、それに乗っかった方がトリッキーなことをやる必要もないし、ややこしく考えることもない。まして、複雑な DAX を書くこともなくなる。
たぶんここまでは、Power BI を使い始めて、しばらくたった人が知っていることだと思う。
でもね、モデリングって、結局何をすることなの?どうすればいいの?って思ってる人、結構たくさんいらっしゃると思う。もし、いまドキッとしたのであれば、全く問題ない。というか、まずはわからないってことを認めることがスタートだと思うのだ。というわけで、今回はスタースキーマを前提に ファクト と ディメンション をってどうあるべきなのさ?ってのを書いてみようと思う。
※ちなみにこの記事の内容は日曜日の朝にシャワーを浴びていたら思い付いたネタなので、そこそこ大事だと思われます(なんのこっちゃ...🤔
スタースキーマって何?
詳しく説明すると、この記事の主題が変わってしまうので、公式の Docs を一読ならず、何度も読むことを強く強くオススメします。
一読する ⇒ 自分のモデル (レポート) で試す ⇒ もう一度読む ⇒ 自分のモデル (レポート) で試す ⇒ もいっかい読む ⇒ 自分のモデル (レポート) で試す...
この繰り返しがとても大事です
ちょっとだけ引用すると、スタースキーマではテーブルを ディメンション と ファクト に分類して、モデリングをします。

ディメンションテーブル
いわゆるマスターテーブルだと思っていれば、たぶん大丈夫です。商品マスタ、カテゴリマスタ、社員マスタ、顧客マスタなどのことです。日付テーブル(カレンダーテーブル)もディメンションに分類されます。日常の業務でもよく出会いますよね?ディメンションテーブルの条件は次の通りです。
- 一意の KEY 列がひとつ存在すること(ID とか〇〇コード)
- その KEY を説明する列がひとつ以上あること(通常は名称列)
- マスタデータなので、データ更新の度にあまりデータが増えない傾向がある
こういう風に書くとちょっと難しく聞こえるんですが、例えば商品マスタだったら、[商品コード] と [商品名] があればいいのです。1行が1商品を表していることになります。[商品名] 以外に、単価や利益、コストなどを持っていてもいいです。ただ、あんまりにも列数が多くなるのはオススメできません。せいぜい数列といったところで、必要なものだけにしてください。使わないものは不要なので、削除しましょうね。
例を示すとこんな感じです。
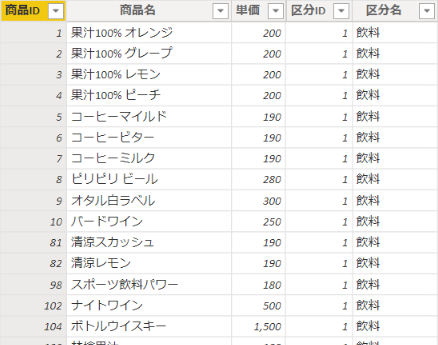
上の図を見て、「あれ?商品マスタに区分も持たせてるの?」って思った方がいるかもしれません。はい、その通りです。持たせちゃってます。スタースキーマにする時のディメンションはその中に階層を持っていても問題ありません。というか、むしろこの方が便利です。区分をテーブルとして分けると、スノーフレークという形になるのですが、すべてを正規化するのではなく、非正規化しておいた方がパフォーマンスの面で効率的になることがあります。先ほどの 記事 に [スノーフレーク ディメンション] というパートがあるので、引用しますね。

スノーフレークもひとつのディメンションのカタチではあるのですが、パフォーマンスとデータ量のトレードオフの関係になります。
つまり
- スノーフレークにすると、データ量は減るけど、パフォーマンスが悪くなることがある
- ひとつのテーブルにまとめると、データ量は増えるけど、パフォーマンスが良くなることがある
ということです。ご自身のデータ量を鑑みて、それぞれを試してみて、パフォーマンスアナライザーや DAX Studio や計測してみることをオススメします。つまり、絶対的にどっちがいいということではなく、ケースバイケースだということです。ただ、最初に試すべきは、スノーフレークではなく、ひとつのテーブルにまとめることをオススメします。
ファクトテーブル
ファクトテーブルは事実が記録されているテーブルです。ディメンションテーブルはマスタデータなので、レコード(行)の単位は何のマスタか?で決まります。ファクトテーブルは、何単位でレコードを保持するかがとても大切です。売上トランザクション単位なのか、日付単位なのか、月単位なのか。基本的には、これ以上分けられない最小の単位で持つことが好ましいですが、レポートでチャート(グラフや表)で表示するのに、そこまで細かい単位がいらないのであれば、ある程度まとめておいてもいいかもしれません。ポイントは、レポートでは、その最小の単位をさらに細かくすることはできないということです。
日付単位で数値を持ってしまうと、時刻単位の集計はどんなに DAX を駆使しても無理ということです。時刻単位の集計が必要なら、ファクトテーブルは時刻単位でデータを持たなければなりません。
数値がある場合
ファクトテーブルで最低限必要なのは、日付と値です。それ以外は、ディメンションの数だけ、列が必要です。
どういうことかというと、
| 日付 | 商品ID | 売上 |
|---|---|---|
| 2022/01/01 | 1001 | 1000 |
| 2022/01/01 | 1002 | 2000 |
| 2022/01/01 | 1003 | 3000 |
| 2022/01/02 | 1001 | 1500 |
| 2022/01/02 | 1002 | 2500 |
| 2022/01/02 | 1003 | 3500 |
| 2022/01/03 | 1001 | 500 |
| 2022/01/03 | 1002 | 1500 |
| 2022/01/03 | 1003 | 4000 |
上記の場合、日付と商品単位で売上という値が記録されています。この場合、日付と商品IDがありますので、ディメンションは [日付テーブル] と [商品テーブル] の2つになるということです。
| 日付 | 商品ID | 売上 | 店舗ID |
|---|---|---|---|
| 2022/01/01 | 1001 | 1000 | 1 |
| 2022/01/01 | 1002 | 2000 | 1 |
| 2022/01/01 | 1003 | 3000 | 1 |
| 2022/01/01 | 1001 | 2000 | 2 |
| 2022/01/01 | 1002 | 4000 | 2 |
| 2022/01/01 | 1003 | 6000 | 2 |
| 2022/01/02 | 1001 | 1500 | 1 |
| 2022/01/02 | 1002 | 2500 | 1 |
| 2022/01/02 | 1003 | 3500 | 1 |
| 2022/01/02 | 1001 | 3000 | 2 |
| 2022/01/02 | 1002 | 5000 | 2 |
| 2022/01/02 | 1003 | 7000 | 2 |
| 2022/01/03 | 1001 | 500 | 1 |
| 2022/01/03 | 1002 | 1500 | 1 |
| 2022/01/03 | 1003 | 4000 | 1 |
| 2022/01/03 | 1001 | 1000 | 2 |
| 2022/01/03 | 1002 | 3000 | 2 |
| 2022/01/03 | 1003 | 8000 | 2 |
上記に加えて [店舗ID] を増やしたとするなら、日付単位、商品単位、そして店舗単位のファクトに変わり、 [日付テーブル] と [商品テーブル] の2つに加えて、[店舗テーブル] もディメンションとして必要になります。合計3つのディメンションということです。
すでにお気づきかと思いますが、ディメンションを表す値はファクトには [Key値] で持たせます。いわゆる [正規化] ですね。このように整理していくと、ファクトテーブルがすっきりして、スタースキーマにより近づくということになります。
数値がない場合
違うパターンをお見せしましょう。ファクトに必ずしも値があるとは限らないのです。
「え?んなバカな...!?」
と思われた方。わかります。わかりますよ。
でもね、あるんです。
どういうデータかと言うと、ログデータがその好例です。
| 日時 | 社員ID | 支店ID | 入退室ID |
|---|---|---|---|
| 2022/01/04 09:00:00 | 1001 | 1 | 1 |
| 2022/01/04 09:30:00 | 1002 | 1 | 1 |
| 2022/01/04 09:50:00 | 1003 | 1 | 1 |
| 2022/01/04 09:50:00 | 2001 | 2 | 1 |
| 2022/01/04 10:15:00 | 2002 | 2 | 1 |
| 2022/01/04 10:30:00 | 2003 | 2 | 1 |
| 2022/01/04 17:30:00 | 1001 | 1 | 2 |
| 2022/01/04 17:40:00 | 1002 | 1 | 2 |
| 2022/01/04 17:50:00 | 1003 | 1 | 2 |
| 2022/01/04 18:50:00 | 2001 | 2 | 2 |
| 2022/01/04 18:15:00 | 2002 | 2 | 2 |
| 2022/01/04 18:30:00 | 2003 | 2 | 2 |
例えば、こんなデータ。おそらくオフィスへの入退室のデータです。これも立派にファクトデータなのですが、数値がないので何を集計したらよいか、途方に暮れる方もいるかもしれません。ご安心を😋‼こんな時はレコード数を数えればいいのです。もちろん目的によっては、レコード数を数えても知りたいことが知れないかもしれませんが、その場合はデータが不足しているということを意味します。
なお、レコード数を数える場合は、レコードの単位が正しいか確認してくださいね。レコード単位が正しいのであれば、DAX で COUNTROWS() 関数で数えるのがよいでしょう。
ちなみに私が公開しているコロナの感染者数のレポートはこの考え方で作ってます。いつ、どこで、どんな人が感染者として確定したかという感染者単位のデータになっていたので、COUNTROWS() にて、レコード数を数えて、欲しい数値の基となる感染者数を算出しています。
COVID-19 in Japan
https://bit.ly/COVID-19-JP-2
東京都 新型コロナウイルス陽性患者発表詳細
https://bit.ly/PBI-Tokyo-Covid19
ここまではわかったけど、でもさ、データがそうなってないんだけど...
そうですよね。データソースが都合よく、ここまで説明したディメンションとファクトのカタチになっているなんてこと、ほぼないですよね。だから、なんです。だから ETL が必要なんです。Data Preparation(Data Prep) と呼ばれる、データ準備です。つまり Power BI ではそれは Power Query のお仕事です。Power Query によって、データを上記のように整形してあげることが必要なのです。
元のデータがどういう形をしているのか?によって、一概にこうすればいい、と言えないのが辛いところです。ですが、ここまでの説明で、ディメンションとファクトが最終的にどういう形であるべきかは理解できたかと思います。いまはまだ、なんとなくで結構です。だまされたと思って、まずは真似をしてみてください。何回かやってるうちにわかる時が来ます。必ずです。というか、やらないとわからないのです。
ファクトからディメンションを作る
よくやるのが ファクト から ディメンション を作る方法。
ディメンションが存在しない場合は、ファクトテーブルに名称が含まれていることが多い。ディメンションテーブルってのは、一意の [Key] と [名称] があればいいわけだから、ファクトテーブルを参照または複製して、別クエリにして、名称列のみにして、DISTINCT(重複を削除)してしまえばよい。のだけど、ちょっと待ってね。Power Query の重複を削除は、全レコードを参照しちゃう処理だから、ファクトテーブルが100万行あると、100万行取得してから、重複を削除しようとしちゃうので、効率がよくないことがある。なので、Power Query のグループ化を上手く使うと良い。名称でグループ化して、集計した列は使わずに削除しちゃえば良い。これで重複を排除した名称列がゲットできたわけなんだけど、ID 値がない。だから、これも作る。インデックス列を追加して任意の ID 列を作ってしまう。
例を挙げてみましょう。例えばこんなデータがあって、[financials] クエリに含まれる [Segment] 列をディメンション化します。
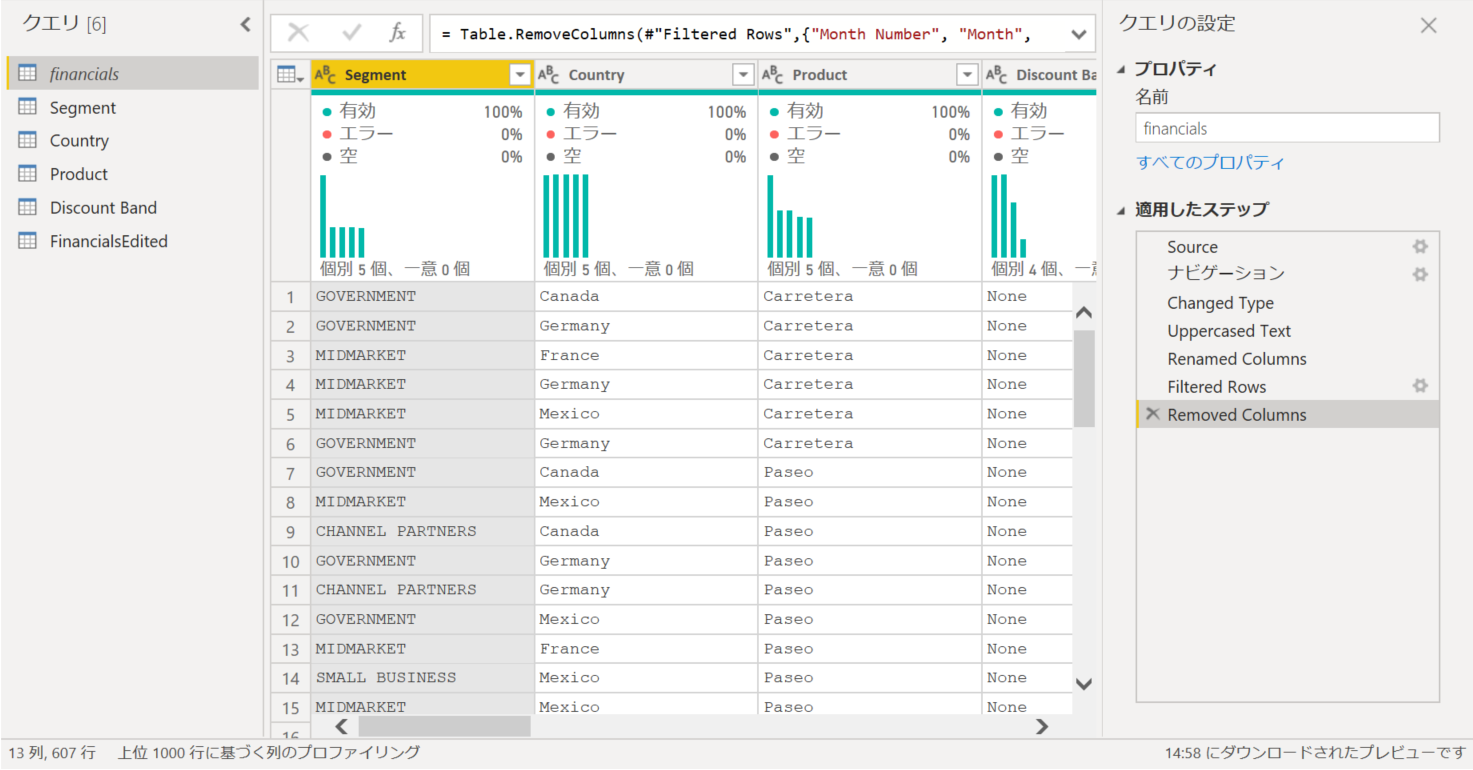
[financials] クエリを右クリックして、[複製] で別クエリを作ります。
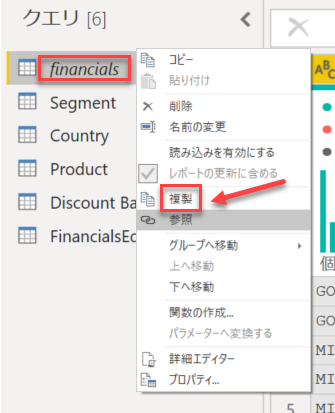
[financials (2)] クエリの [Segment] 列を右クリック - [他の列の削除] をクリック
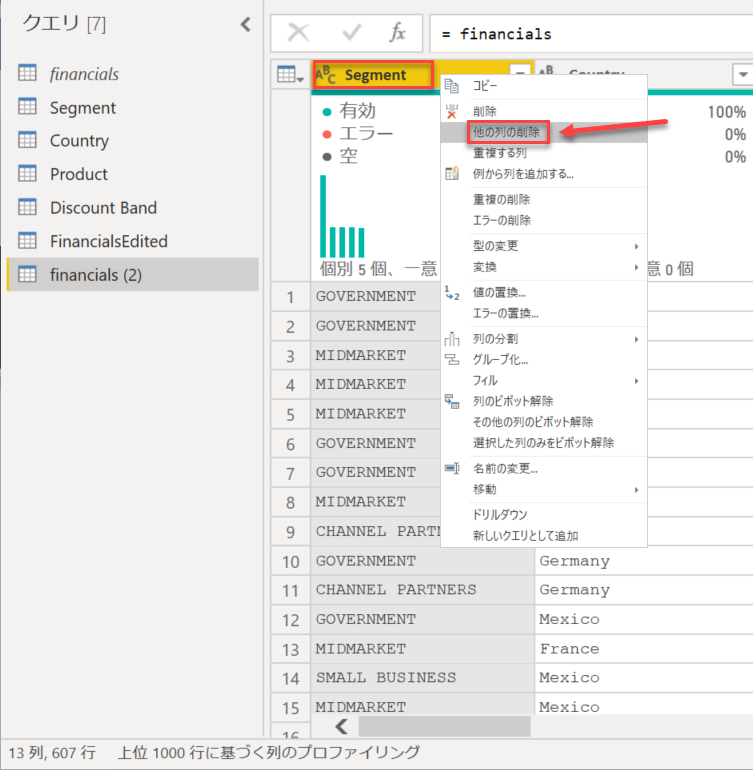
もう一度 [Segment] 列を右クリック - [グループ化] をクリック
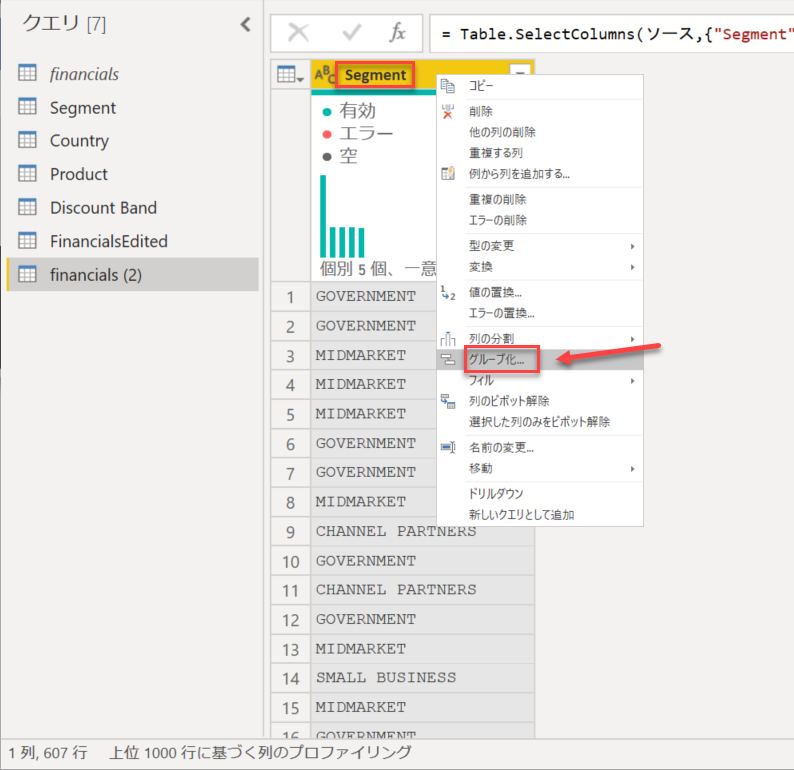
この状態で [OK] をクリック

そうすると、[Segment] 列の値ごとの行数が [カウント] 列に集計されますが、この [カウント列] は不要なので、削除します。
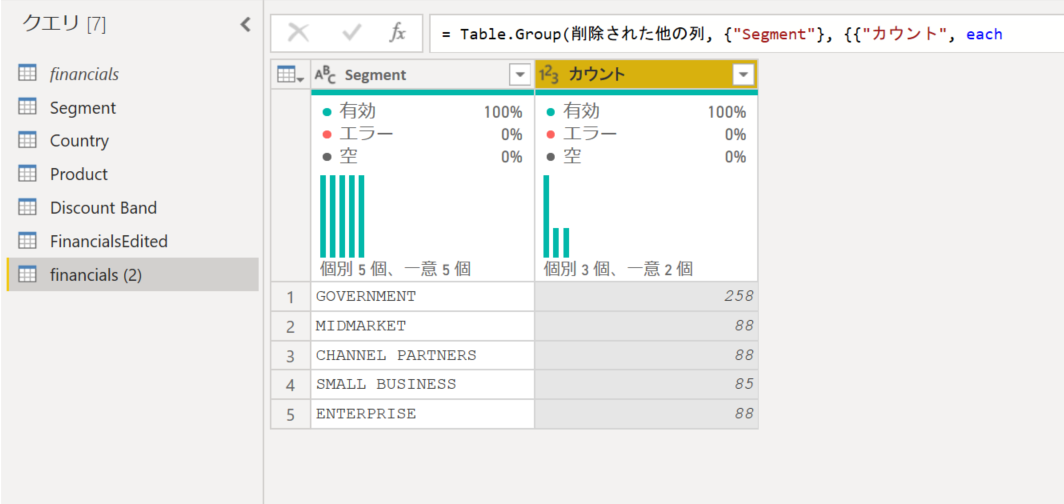
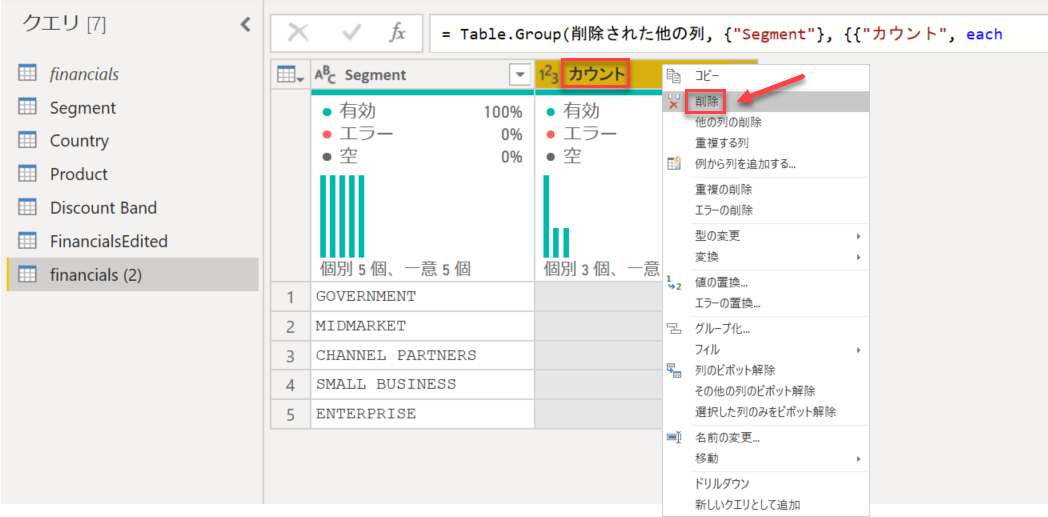
これで [Segment] 列の値が一意になりました。次は ID 列が必要です
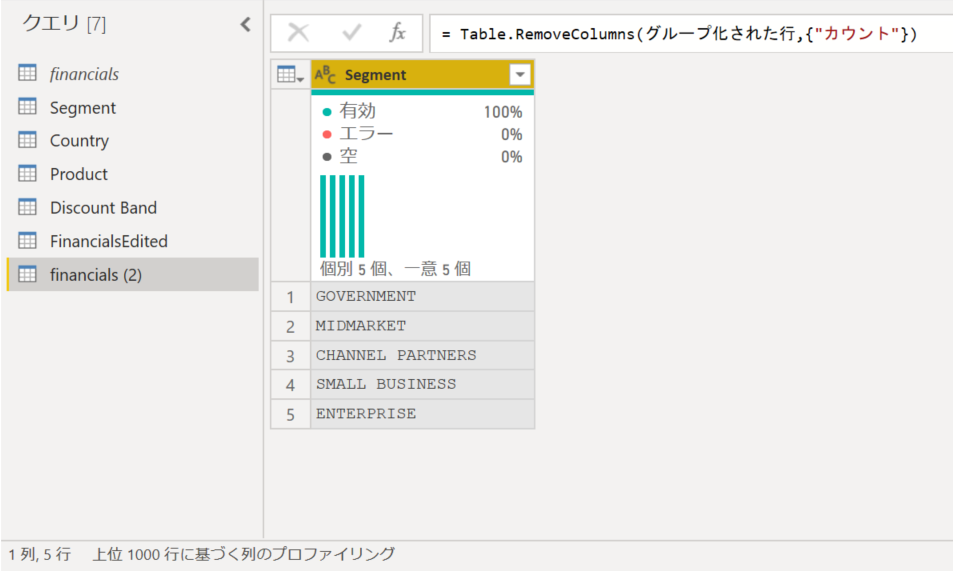
というわけでリボンの [列の追加] - [インデックス列] からインデックス列を追加します。
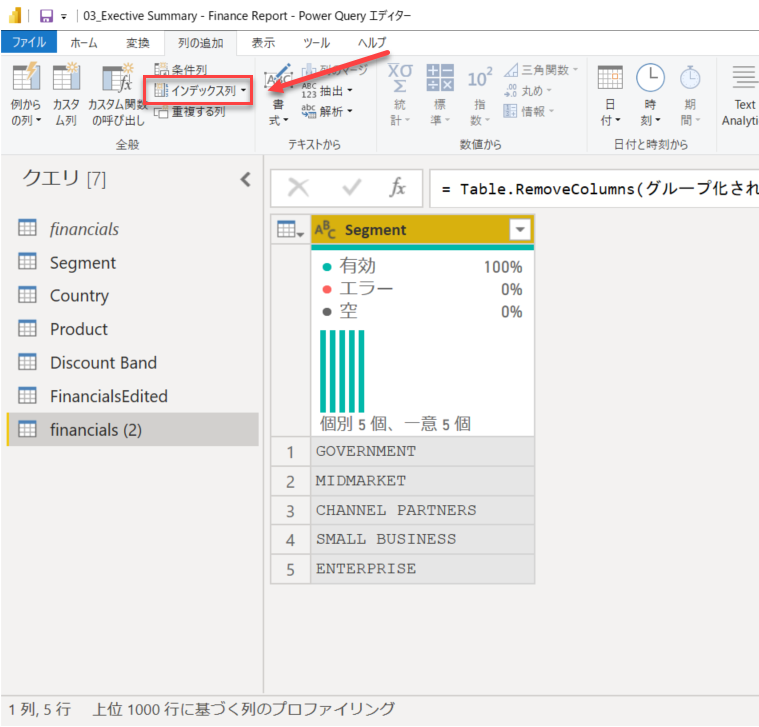
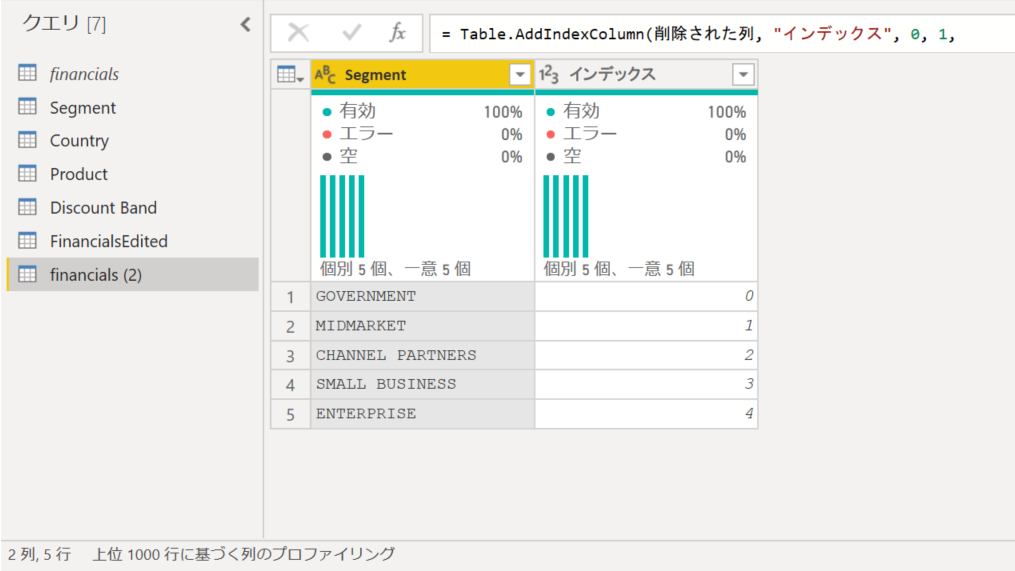
Power Query の "インデックス" ってなってるところを "SegmentId" に変えておくと、追加時に列名が付けられます。
Table.AddIndexColumn(削除された列, "SegmentId", 0, 1, Int64.Type)
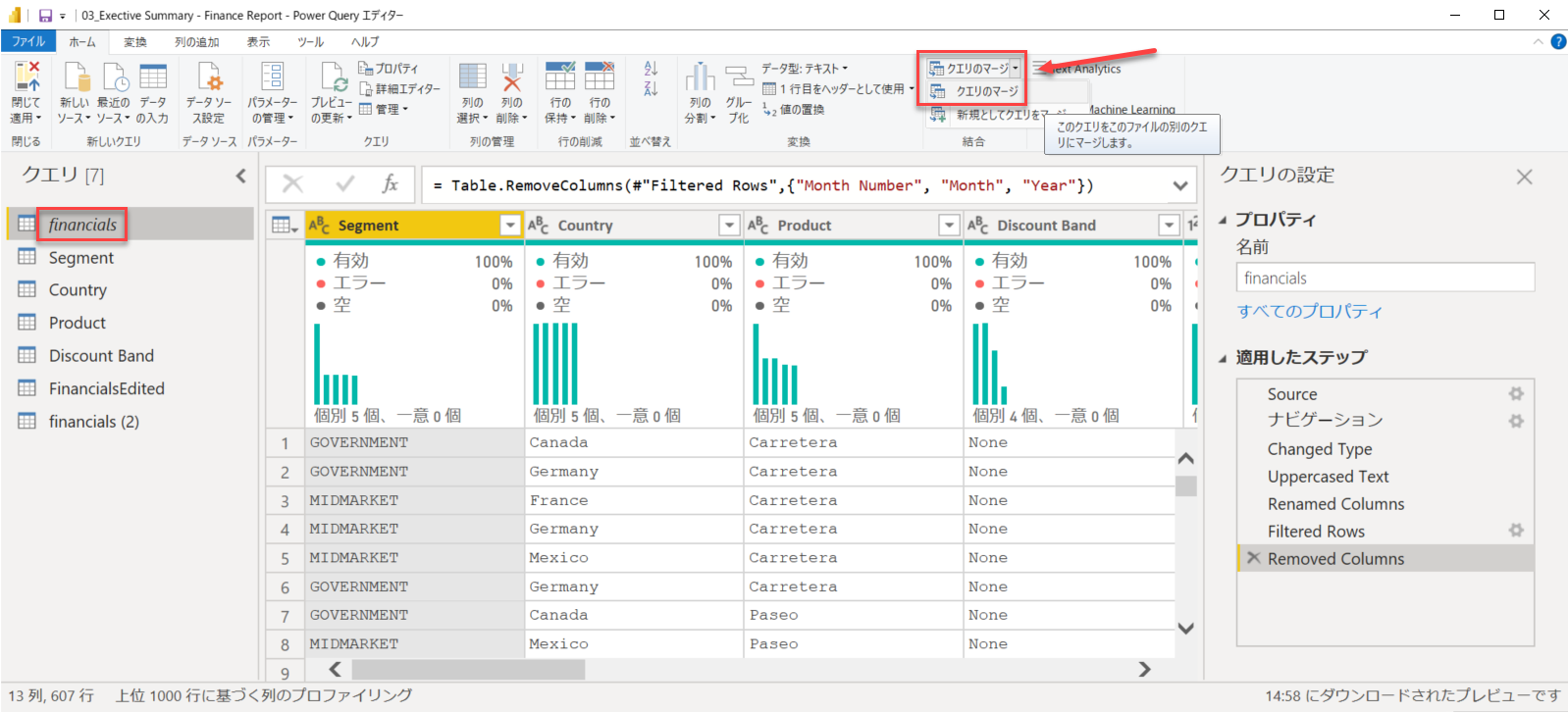
さて、まだあります。あとは元のクエリ [financials] と名称でマージして、ID 列に置き換えます。
いっぺんに行きますよ。
[financials] を選んで [クエリのマージ] をクリック
[Segment] と [Segment] を選んで、OK をクリック
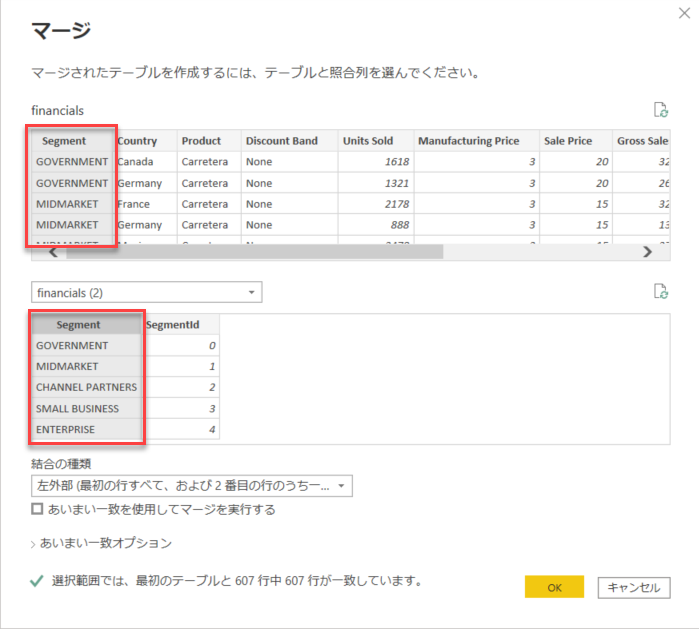
[financials (2)] の列名右側の展開ボタン - [SegmentId] のみ選択 - [OK] をクリック
注意:[元の列名をプレフィックスとして使用します] のチェックは外しておく
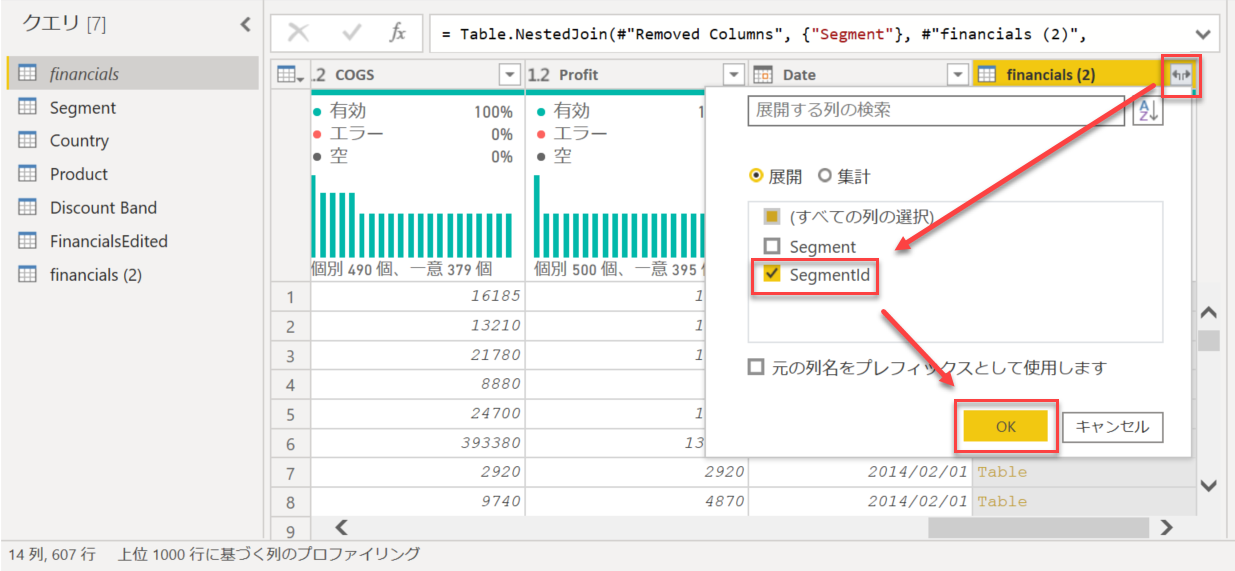
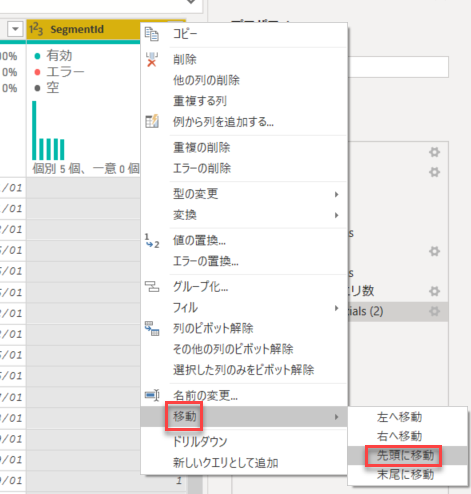
説明のため、見やすくするために、[SegmentId] 列を先頭へ移動
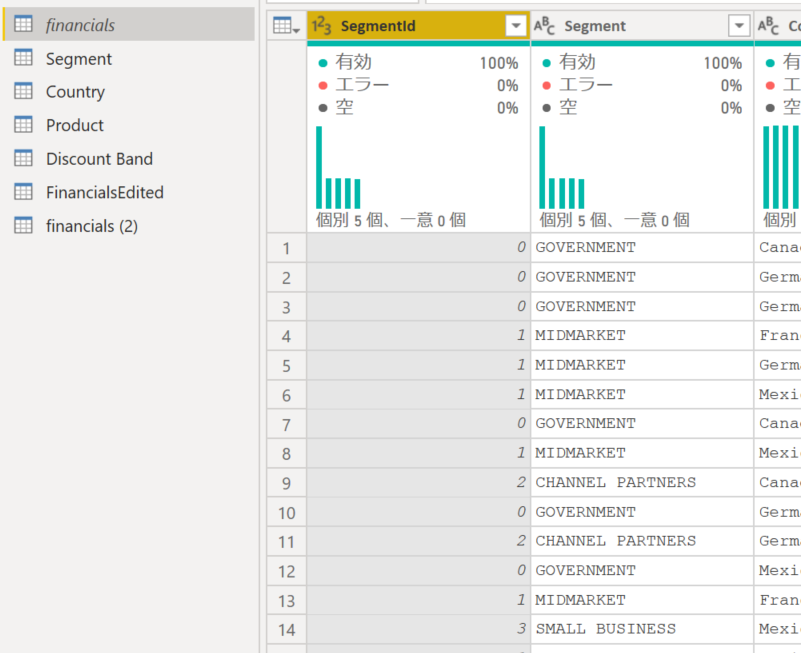
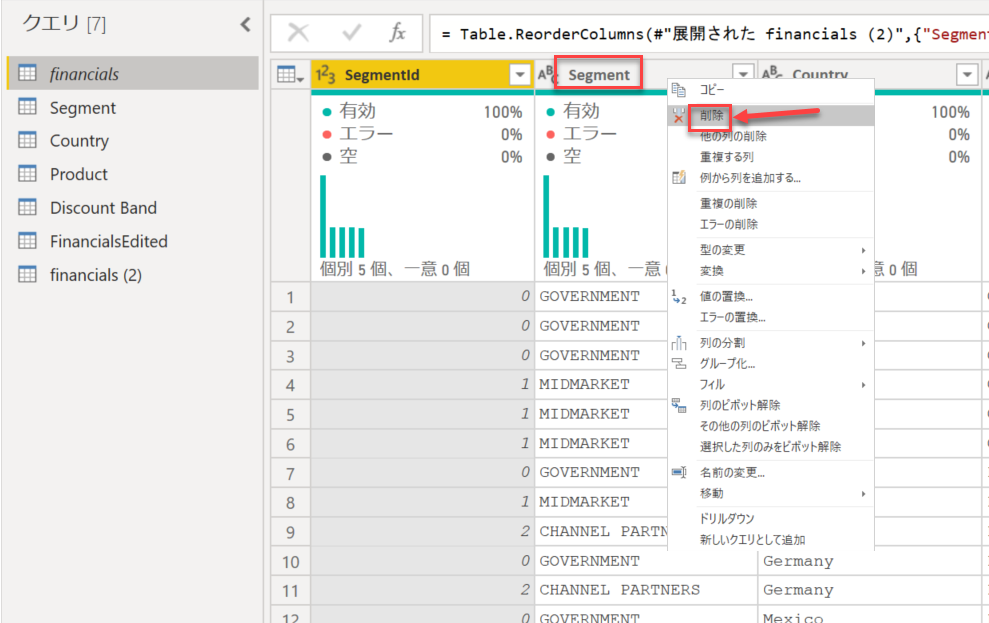
これで [financials] クエリの中に [Segment] という名称列に対応する [SegmentId] 列が作成できたので、名称列は不要になりました。というわけで、[Segment] 列を削除します
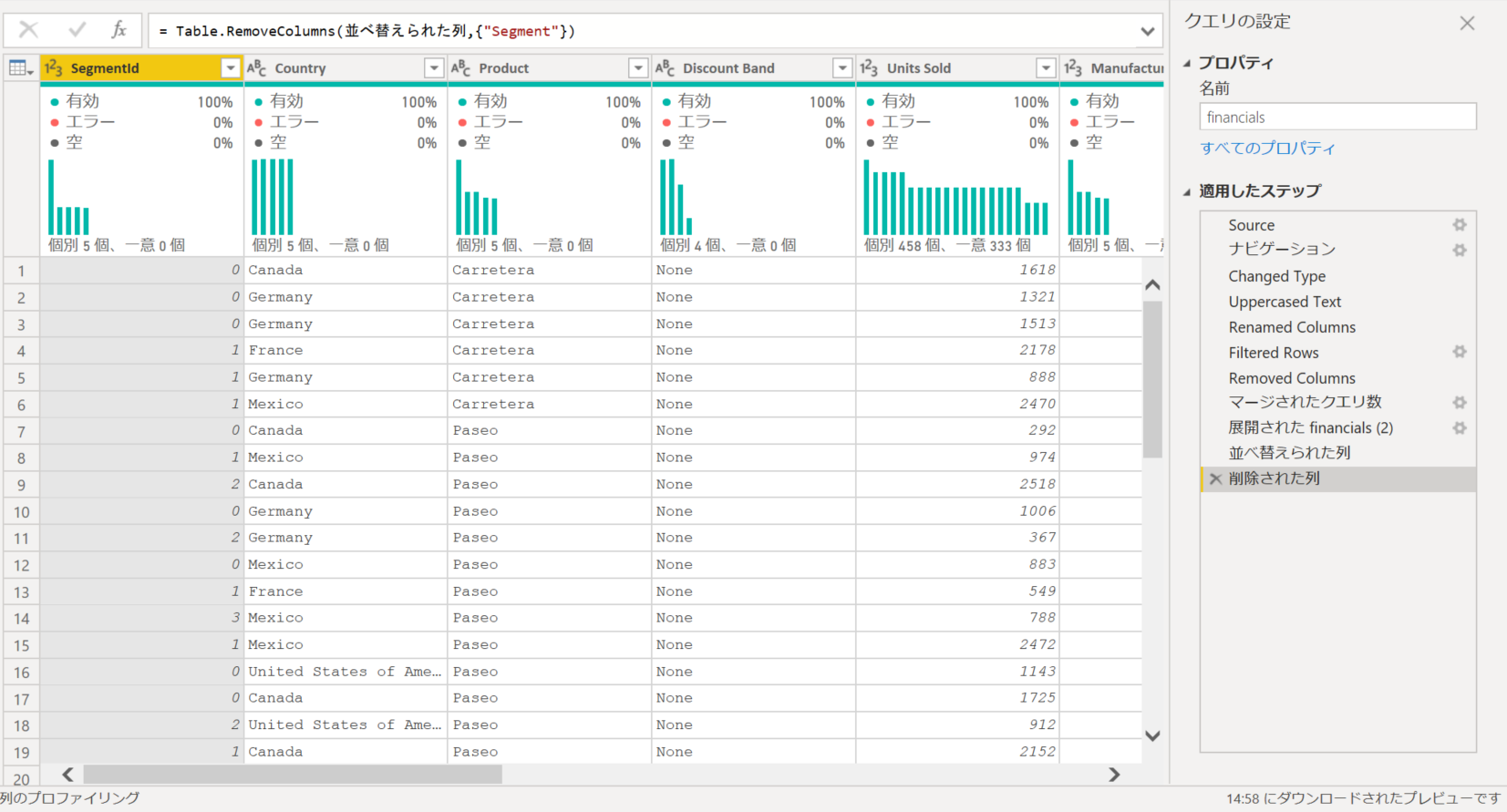
こんな感じで、名称列を持っているファクトテーブルからディメンションテーブルを作成して、ファクトテーブルの名称を ID 値に置き換えることができました。これを欲しいディメンションごとにすべてやれば、いいというわけです。少々面倒に感じるかもしれませんが、最も効率のよいスタースキーマのためのデータ準備の手順を紹介しました。
もちろんこの方法が唯一の方法ではありません。データソース側でこのように準備ができるのであれば、それに越したことはありません。いずれにしても、処理の結果、どういう形のデータが欲しいのか?を意識して、データ準備をすることが大事です。
まとめ
今回は以上です。
スタースキーマを作る手順を少しだけ紹介しました。
もっとここが知りたいなどがありましたら、遠慮なくコメントください。
それではまた😋👍