ソース
ttml2text.rb
require 'nokogiri'
doc = Nokogiri::parse($stdin.read)
doc.css('p').each do |node|
line = node.xpath('.//text()').map do |e|
words = e.text
words.strip!
words if words.length > 0
end.compact.join(" ")
puts line
end
使い方
bash
ruby ttml2text.rb < インプットttml2 > アウトプット.txt
ソース解説
- Amazonプライムの字幕データはHTMLっぽいXML
- pタグが字幕データそのものなので、
css('p')で字幕ノードを取得 - 細かいメタデータを削除したいので、
xpath('.//text()')でテキストノードを取得 - 空白のテキストノードを削除してつなげる
- brとかで区切られたテキストノードは空白でつなげる
ttml2の見つけ方
devtoolsのフィルタ機能でttml2でフィルタする
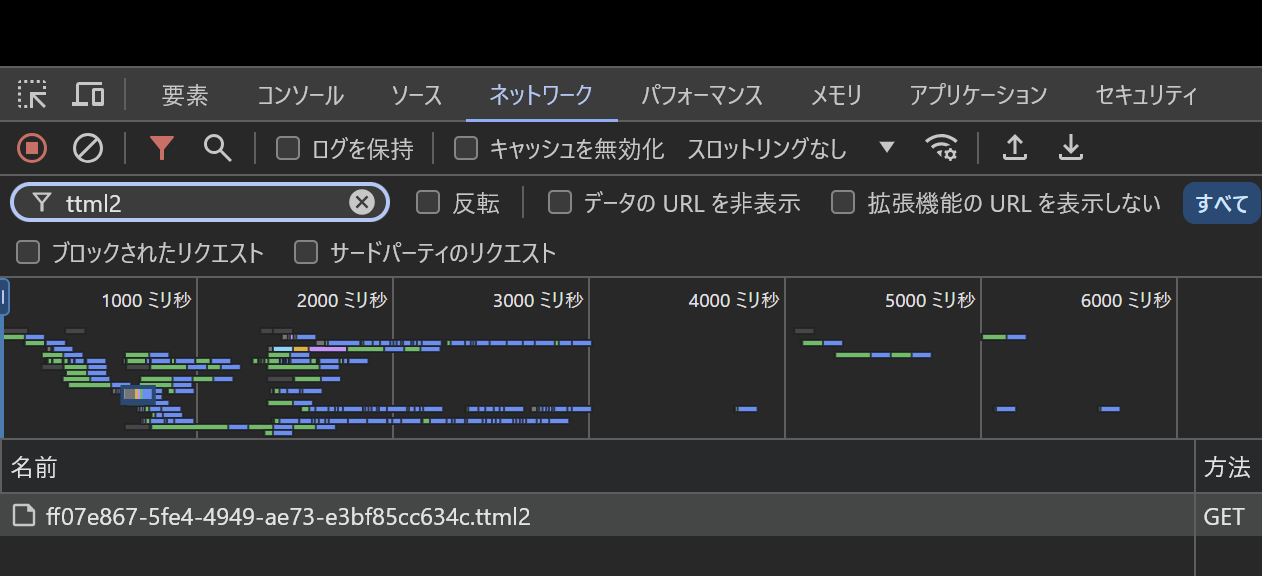
あとは名前欄をダブルクリックすればダウンロードが始まる(Chromeの場合)。