参考本
多変量解析入門 -線形から非線形へ- 小西貞則著
前回記事
基底関数という用語の導入
$$u(x;\boldsymbol \theta)= \beta_0+\beta_1 x+ \beta_2 x^2 + \beta_3 x^3 + \sum_{i=1}^{m} \theta_i M_{x-t_i}^3$$
$$u(x;\boldsymbol \theta)= \beta_0+\beta_1 x+ \sum_{i=1}^{m-2} \theta_i (d_{i}(x) - d_{m-1}(x))$$
$\beta_0, \beta_1, \cdots, \theta_1, \theta_2 ,\cdots$に関しては、どちらも線形モデルである。
どういうことかというと、スプライン関数そのものは非線形モデルである。
3次スプライン関数は、基底関数
$$1, x, x^2, x^3, M^3_{x-t_1}, M^3_{x-t_2},\cdots, M^3_{x-t_m}$$
の線形結合で、また自然スプライン関数は、
$$1, x , d_1(x)-d_{m-1}(x), d_2(x)-d_{m-1}(x),\cdots, d_{m-2}(x)-d_{m-1}(x)$$
の線形結合で表されるモデルである。
ちなみに線形単回帰モデルは、基底関数$[1, x]$の線形結合で、多項式モデルは、基底関数$[1, x, x^2, \cdots, x^p]$の線形結合である。
B-スプライン
スプラインは、区分的に多項式を当てはめて、節点で滑らかに接続したものである。
対して、B-スプラインとは、複数の多項式を滑らかに接続して、1つの基底関数を構成したものである。
いま、$m$個の基底関数$[b_1(x), b_2(x), \cdots, b_m(x)]$を構成するために必要な分点$t_i$を
$$t_1<t_2<t_3<t_4=x_1<\cdots< t_{m+1}=x_n <\cdots< t_{m+4}$$
このように分点をとることで、$n$個のデータは$m-3$個の区間$[t_4, t_5],[t_5, t_6], \cdots, [t_m, t_{m+1}]$によって分割される.
この分点をもとに、B-スプライン基底関数を構成されるには以下のアルゴリズムが用いられる。
$r$次のB-スプライン関数を$b_j(x;r)$とおく。
$$b_j(x;0) = \left\lbrace \begin{array}{c} 1 \hspace{1em} (t_j \leq x \leq t_{j+1}) \
0 \hspace{1em}その他 \end{array}\right. $$
と定義する.
$$b_j(x;r)= \frac{x-t_j}{t_{j+r}-t_j} (x;r-1) +\frac{t_{j+r+1}-x}{t_{j+r+1}-t_j} (x;r-1)$$
$r$を順々に増やすと、1次、2次、3次の多項式を指す。各区間が次数より1つ多い個数の直線や、2次多項式、3次多項式、つまり基底関数によって構成されている。
例えば、
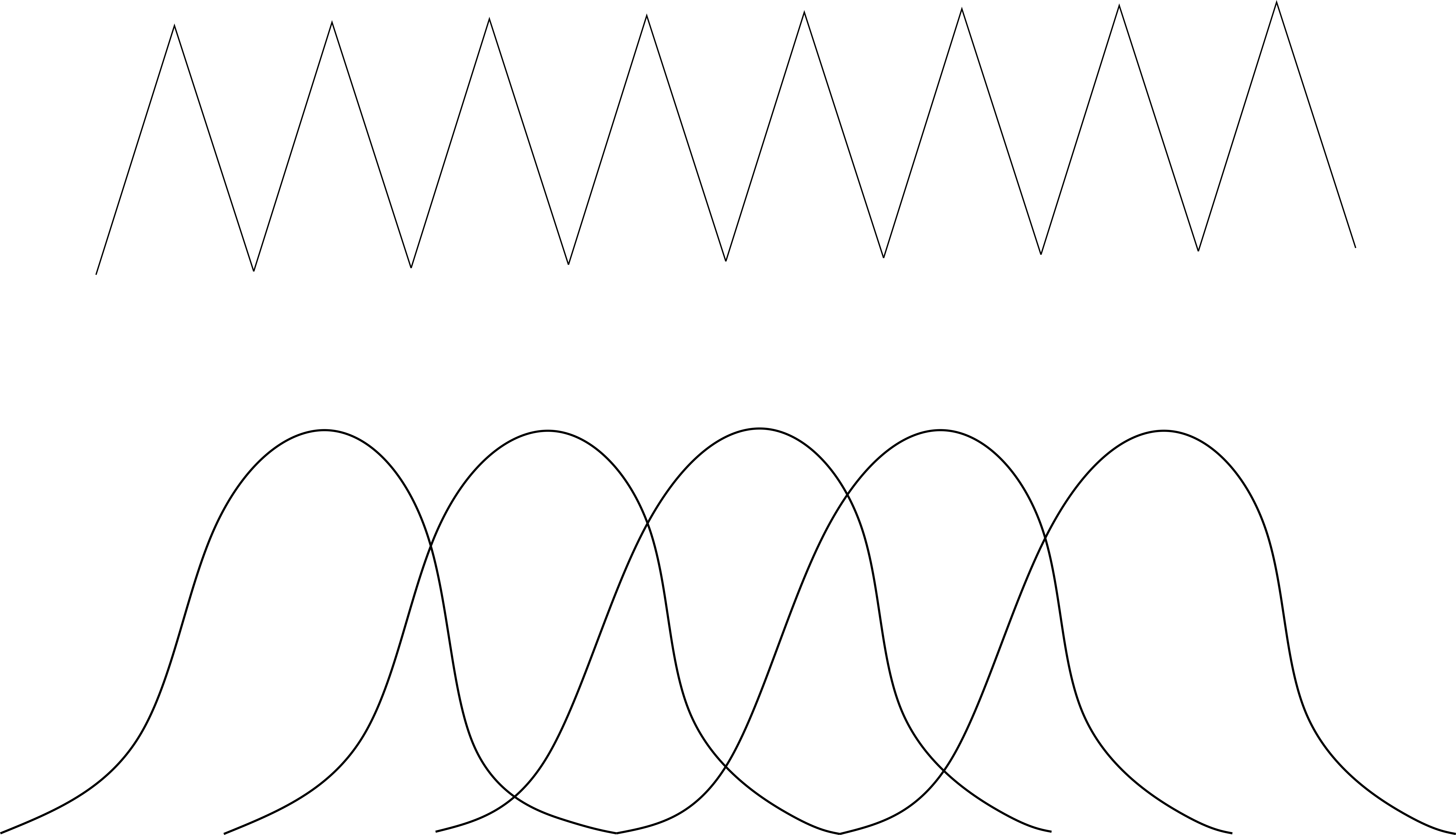
(上から順に1次、2次のB-スプライン基底関数をさす。)
ある区間を上手く選んだうえで、上は2つの基底関数、下は3つの基底関数で覆われている。
次の図では、ある区間で3次B-スプライン基底関数が4つの基底関数で構成される。
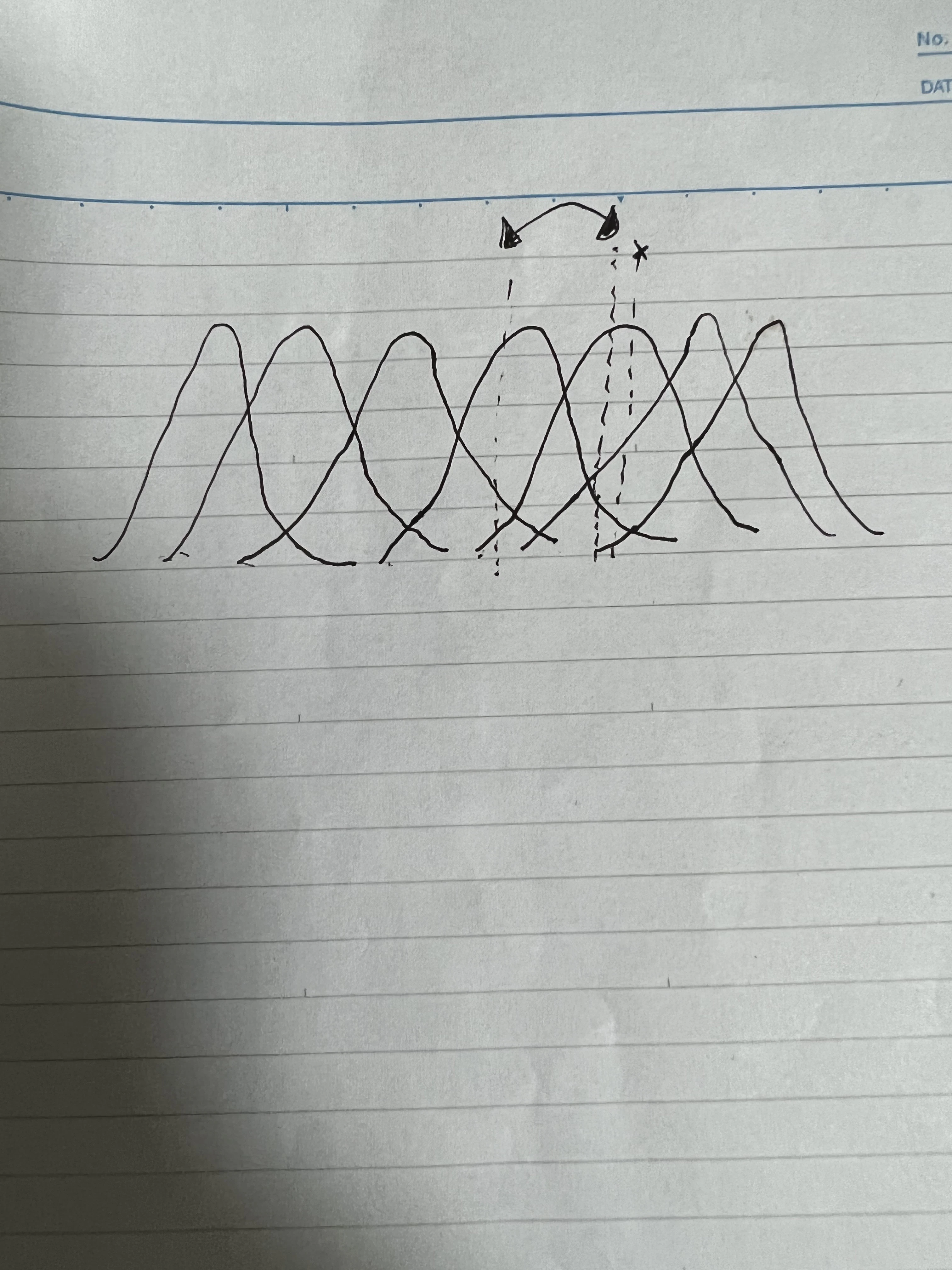
3次B-スプライン回帰モデルは、現象の構造を3次B-スプライン基底関数の線形結合で近似した、次の式で与えられる。
$$y_i=\sum_{j}^{m} w_jb_j(x_i;3) + \epsilon_i \hspace{1em} i = 1,2,3 \cdots,n$$
各基底関数の係数を上手く推定すれば、データの非線形構造を捉えることが可能となる。
実際、スプラインを適用する場合分店の個数と位置を決める問題がある。特に分点の位置をいろいろ動かしてパラメータとして推定することが極めて難しい。
なので、分点を観測範囲に等間隔に配置して分点の個数を調節して、滑らかににする。
動径基底関数
$p$次元ベクトル$x$と$\mu$の間の距離$L_2(\boldsymbol x, \boldsymbol \mu)= \mid \mid \boldsymbol x- \boldsymbol \mu \mid\mid^2 $に依存する非線形関数$\phi(z)$は$\rm 動径基底関数$と呼ばれ、
回帰モデルは、
$$y_i=w_0 + \sum_{j=1}^{m} w_j \phi_j(L_2(\boldsymbol x, \boldsymbol \mu))+\epsilon_i \hspace{1em} i = 1,2,\cdots, n$$
ガウス型基底関数(正規表現の時の関数)とは以下の通り
$$\phi_j(x) \equiv {\rm exp} (-\frac{ \mid \mid\boldsymbol x-\boldsymbol \mu \mid\mid^2}{2h_j^2}) $$
$h_j$は散らばりぐあい、変動具合を示す指標で標準偏差(standard deviation)と呼ばれる。(文献により$\sigma_j$)
$h_j^2$は分散(variance)と呼ばれる。
$$\boldsymbol \mu = \frac{1}{n} \sum_{x_i} \boldsymbol x_i$$
$$h_j^2 = \frac{1}{n} \sum_{x_i} \mid \mid \boldsymbol x_i-\boldsymbol \mu_j \mid\mid^2$$
詳しい説明
パラメータを同時に推定する方法も考えられるが、基底関数の個数の判定も考えると、様々な問題が生じ、計算量が膨大となる。
これを避けるには、説明変数に関するデータから基底関数を事前に決定して既知の基底関数を持つモデルをデータにデータにあてはめる2段階推定法が用いられる。
その一つとして、クラスタリング手法を適用して基底関数を事前に決定する方法がある.
この方法は、$p$個の説明変数に関するデータ$ x_1, x_2, \cdots ,x_n$をいずれ述べる、k-平均法や自己組織化マップによって基底関数の個数に相当する$m$個のクラスター$C_1, C_2, \cdots, C_m$に分割し、各クラスター$C_j$に含まれる$n_j$個のデータに基づいて、中心ベクトル$\boldsymbol u_j$と$h_j^2$を次のように決定する
$$\boldsymbol \mu_j = \frac{1}{n_j} \sum_{x_i \in C_j } \boldsymbol x_i$$
$$h_j^2 = \frac{1}{n_j} \sum_{x_i\in C_j } \mid \mid \boldsymbol x_i-\boldsymbol \mu_j \mid\mid^2$$
推定値をガウス型基底関数に代入して、
$$\phi_j(\boldsymbol x) = {\rm exp} (-\frac{ \mid \mid\boldsymbol x-\boldsymbol \mu_j \mid\mid^2}{2h_j^2}) \hspace{1em} j= 1, 2, \cdots, m$$
を$j$番目の基底関数として用いる.
このときガウス型基底関数に基づく線形回帰モデルは、次で与えられる.
$$y_i = \omega_0 + \sum_{j=1}^{m} \omega_j \phi_j(\boldsymbol x_i) + \epsilon_i, \hspace{1em} i = 1, 2, \cdots ,n$$
vol.3に続く。
https://qiita.com/yudaiyamashita/items/1de41a8a3381557f0478