イントロ
日立製作所 研究開発グループの中田です。普段、エッジコンピューティングや分散システムの研究開発、またシステムアーキテクトをやっています。
公私ともにQiitaは初投稿です。
今回は、Rayを紹介します。
Rayは、分散処理を含むアプリを開発するためのライブラリおよび実行環境です。まだ日本では情報が少ないのですが、海外では有名企業や大学がこぞって活用しており、かなりホットなライブラリだと思います。今年2020年10月1日にバージョン1.0がリリースされました。また同じタイミングにRay Summitが開催され、50本程のセッションで多数の活用事例が紹介されました。
Rayは、通常の手続き型言語を容易に分散処理化できるものであり、データ分析やエッジ/IoTの分野で有用に思えるので、日本でも広まって欲しいと思っている次第です。
本記事では、そもそもここでの分散処理とは何か、から始めて、使い方や特徴と、Ray Summitで紹介された活用事例をまとめます。Let's enjoy distributed computing!
(環境:Python3.8、ray1.0.1-post1)
Rayとは
Rayは、分散処理を簡単に記述するためのPython/Javaのライブラリ・処理基盤です。Rayを使うことで、あたかもローカルで動くような見慣れたプログラムを、複数のスレッド、複数のコア、複数のサーバ、複数のクラウドにまたがって実行することができます。
(Google検索では、"ray distributed"などと検索するとトップに出ます)
Rayが対象とする分散処理
まず、ここでの分散処理のイメージを合わせておきましょう。
Rayは、一つのアプリケーションの中において、一部の処理を、別の場所(スレッド、コア、サーバ、クラウド)で動かすような、アプリケーションアーキテクチャとしての分散処理を開発するためのものです。
例えば、このような処理です。
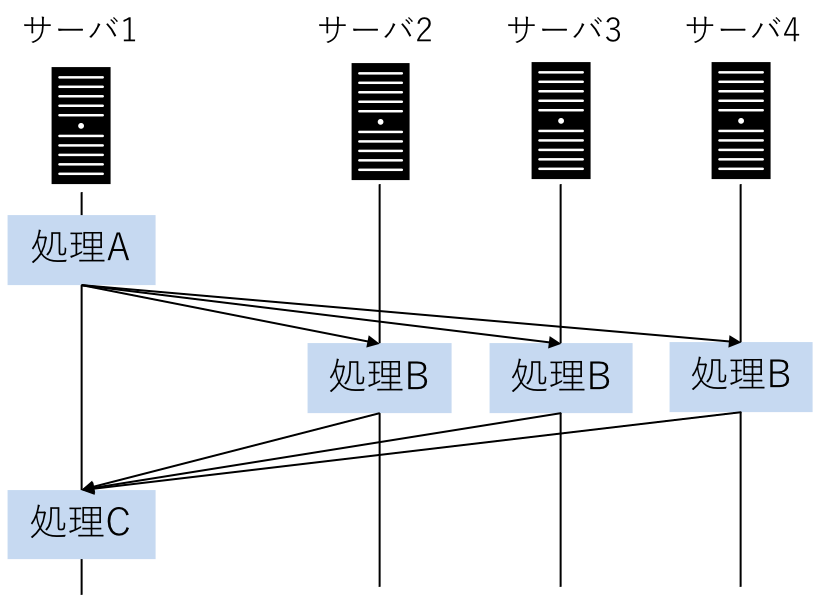
上は、主にスケールアウトのために行う分散処理です。例えば、MapReduceが含まれます。処理を並列に実行するため、分散"並列"処理と言われたりします。
他にも、このような処理もRayの範疇です。
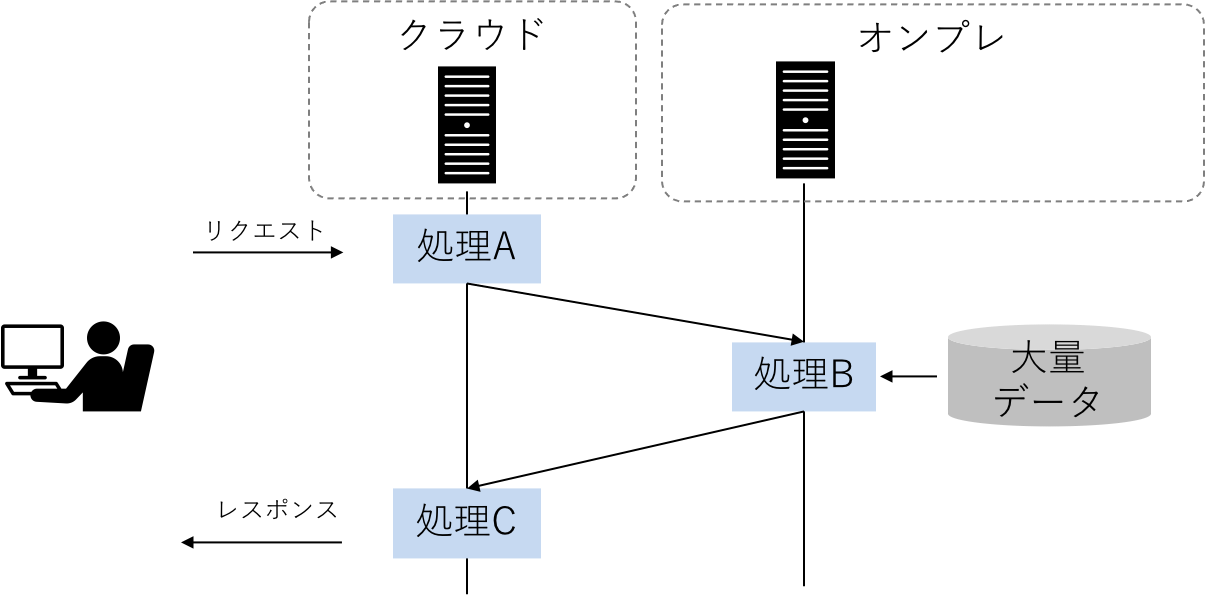
これは、一つの処理の流れではあるものの、処理をする場所が処理ごとに異なっているケースです。例えば、オンプレの大量データをクラウドに送信したり保管するコストを抑えるために、オンプレである程度のデータ処理を行い、結果だけクラウドのシステムに持っていく、というイメージです。
「アクターモデル」と呼ばれるアーキテクチャもRayで容易に実装できます。

アクターモデルは、非同期分散処理を記述するためのアーキテクチャパラダイムの一つです。アクターは、特定の責務を持ったオブジェクト指向のオブジェクトのようなもので、他のアクターから生成されたり、常駐プロセスのように稼動させたりできます。アクターは互いにメッセージを投げ合ってリアクティブに反応します(メッセージの内容や型に応じた処理を実行します)。その処理の連携(連鎖)によってアプリケーションの機能が実現されます。
アクターは、状態をインメモリに持つ常駐プロセスとして実現できるため、ある意味で、DDD(ドメイン駆動設計)で言うドメインオブジェクトのマテリアライズドビューのようなものも実現できます。これを応用し、エッジコンピューティングでは、エッジデバイスの状態を反映するDigital Twinをアクターで表現することが考えられたりします(ご参考1, ご参考2、ご参考3)。
3つ例を挙げましたが、総じて、ここでの分散処理は、一つのアプリケーションの中の話です。コンテナ技術も分散処理ですが、一つのアプリを複数稼動させるシステムレベルのアーキテクチャであり、Rayとはレイヤーが違います。
一つのコンテキスト(関心事の範囲)の中に、分散処理を入れたい場合は、分散処理のためにアプリを分割したり、ドメインロジックを記述すべきところに分散処理用のコードを入れたくはないため、Rayのようなライブラリ・実行環境をうまく使い、システムの可読性・メンテナンス性を向上させるのが良いでしょう。
Rayの基礎的な使い方
Rayを使えば、分散処理がローカルで実行されるコードとあまり変わらずに記述できます。
まず、並列処理を行う一般的なPythonスクリプトを見てみましょう。
from multiprocessing import Pool
import time
def waiting(core_id):
time.sleep(core_id)
return core_id
if __name__ == "__main__":
CORE_NUM = 4
p = Pool(CORE_NUM)
results = [p.apply_async(waiting, args=[x]) for x in range(CORE_NUM)]
print([x.get() for x in results])
4つのコアに、1~4秒待つ処理を実行していますが、x.getで各処理が終わるのを待っています。並列で行っているので、1+2+3+4=10秒待つことはなく、4秒だけ待てば結果が返ってきます。
この処理をRayを使うと、以下のように記述できます。
import ray
import time
ray.init(num_cpus=4)
@ray.remote
def waiting(id):
time.sleep(id)
return id
if __name__ == "__main__":
print(ray.get([waiting.remote(x) for x in range(4)]))
@ray.remoteが付いた関数が、__main__を実行するコアとは別のコアで実行されます。
先ほどと似てはいますが、違いは、p = Pool()がなくなり、代わりにray.init()が追加されたことです。これが何を意味するのかと言うと、プロセスプールを開発者が管理する必要がなくなり、Rayに任せることになります。つまり、どこに処理を割り振るか、各プロセスのメモリの管理など、分散処理における抽象度の低い面倒なことを、Rayが引き受ける構造になったわけです。そのため、開発者は、以前のコードよりも、ドメインロジックに集中できます。
アクターモデルの処理は、以下のように記述できます。
import ray
import time
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
if __name__ == "__main__":
counters = [Counter.remote() for i in range(4)]
[c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
time.sleep(60)
先程は関数に@ray.remoteが付いていたのが、クラスに付きます。この@ray.remoteが付いたクラスを、データと振る舞いを持つ常駐プロセスとして機能することができます。
こちらも、プロセスの管理がRayに任されているため、開発者はCounterオブジェクトの処理を指示するだけで、Rayが良きに計らってどこかで処理を実行します。
Rayがプロセスの管理を行うため、プロセスのモニタリングも、Rayが機能を提供しています。
上記のアクターモデルの処理が終わる前に(time.sleep(60)が終わる前に)、http://127.0.0.1:8265にアクセスしましょう。そうすると、Rayのダッシュボードが閲覧できます。
Rayの位置付け
コンピュータサイエンスの世界で、分散処理は長い歴史があり、Hadoop, Spark, Stormなどなど、様々な分散基盤が存在しています。これらに対するRayの位置付けは、Rayの開発者であるSchafhalter氏の講演の以下の言葉にあると思います。
Modern scalable AI applications need support for distributed training, distributed reinforcement learning, model serving, hyperparameter search, data processing, and streaming. All these problems are right now siloed into specialized distributed systems.
(中略)
Instead of having a separate distributed computing framework that solves some specific part of the machine learning lifecycle, we created Ray, a high performance distributed computing system, and built libraries on top of Ray to support all these types of workflows. Using this architecture, we can avoid overheads and leverage performance of building on one system.
以下、和訳です(一部、私の理解の範囲で補足しています)。
最新のスケーラブルなAIアプリケーションには、分散トレーニング、分散強化学習、モデルサービング、ハイパーパラメータ検索、データ処理、ストリーミングのサポートが必要です。これらの問題はすべて、現在、特殊な分散システムにサイロ化されています。
(中略)
機械学習での業務におけるいくつかの特定の部分を解決する個別の分散コンピューティングフレームワークを用いる代わりに、我々はRayを作りました。Rayは、人のあらゆるタイプの作業を支える、高性能な分散コンピューティングシステム、及び、その上で動くように作られたライブラリです。このアーキテクチャを用いて、我々は(個々のフレームワークを繋ぎ合わせて使う)負担を回避し、一つのシステムでの効率的な開発を享受できるのです。
引用元:InfoQ Scaling Emerging AI Applications with Ray
下記は私が想像する、Rayの立ち位置のイメージです。
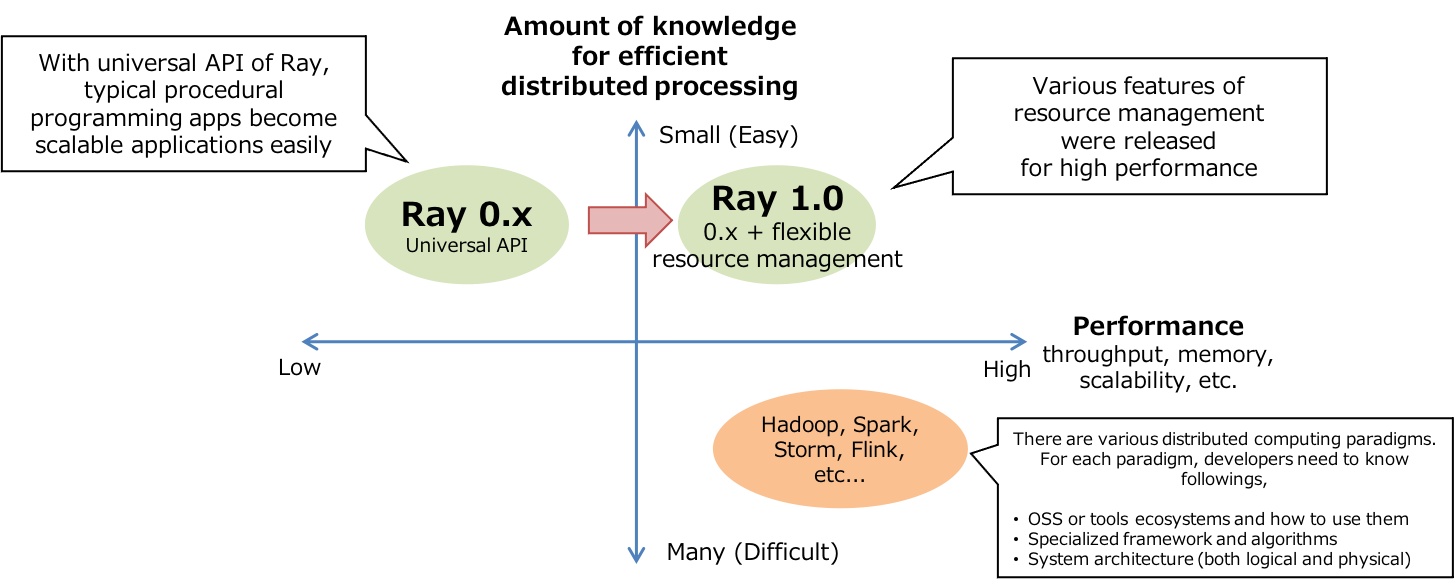
横軸は、分散処理のパフォーマンス、縦軸は開発の容易さです。
データ処理と言っても、バッチ、ストリーム、グラフ、強化学習、ディープラーニング、などなど、とても多様なパラダイムが存在しています。従来のビッグデータ処理のプラットフォームやOSSは、それぞれのパラダイムごとに存在していました。それらのプラットフォームやOSSは、パフォーマンスを常に追求し、そのパラダイムに最適なフレームワーク、分散ロジックが出来上がりました。
しかし、このDX時代において、データを扱うのは、データエンジニアだけではなく、むしろサービス開発者、ドメインエキスパートだったりもします。そういった職種の人々が、やりたいビジネス、改善活動があったときに、一から処理パラダイムについて学習するのは酷です。
これに対して、逆のアプローチなのがRayだと思っています。極端に言うと、Rayは、通常の手続き型言語のプログラムに対し、関数に@ray.remoteをつけるだけなので、遥かに開発難易度が下がります。当然、関数やアクターの分散という、プリミティブな部分(Universal API)のみが範疇なので、複雑で大規模なデータ処理システムをRayで開発したとき、その開発者の設計次第で、パフォーマンスが大きく変わります。
Rayは1.0になり、メモリ管理や、クラスタ環境でのスケジューリングなど、多くのパフォーマンスに関する機能が追加されました。そのため、依然としてRayを使った開発者依存はあるとしても、より性能の良い分散処理アプリケーションを開発できるように、進化しているイメージです。
こういった、パフォーマンスと開発容易性の両立が、Rayの方向性なのかと感じています。
Rayクラスタの構成
分散処理の醍醐味である、複数サーバでのクラスタ構築と分散処理を体験してみましょう。
アーキテクチャ
まず、Rayが稼動するクラスタのアーキテクチャを説明します。
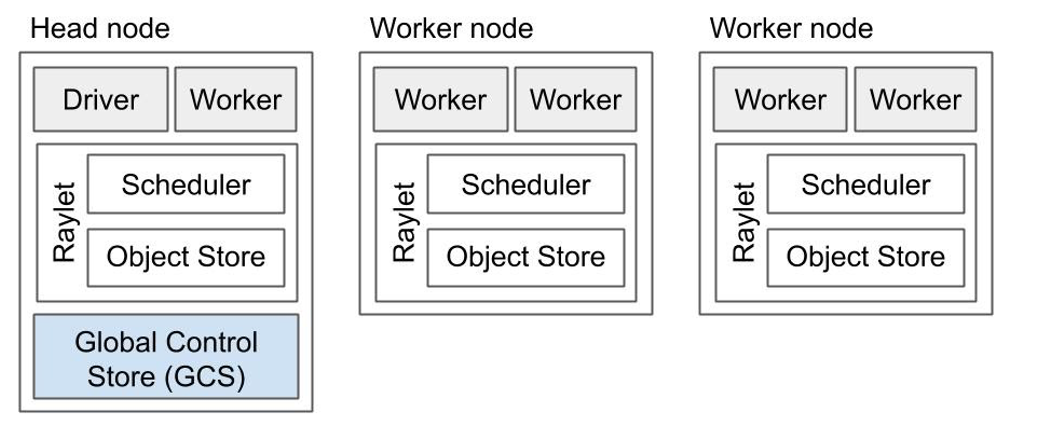
(Ray1.0 White Paperから引用)
Rayが稼動する環境の一単位は、ノード(node)と呼ばれます。各ノード内のWorkerは、アプリの処理を実行するプロセスを指しています。
また、全ノードに、Rayletというコンポーネントがあります。RayletはRayにおけるミドルウェアで、いわゆるコントロールプレーンと呼ばれるような、処理のスケジューリングや各プロセスが使うオブジェクトのメモリ管理などを行ってくれるものです(KubernetesでいうKubeletと同じ立ち位置であり、英語ではよくこういうコンポーネントを〇〇letと呼びます)。
Rayletには、スケジューラと、オブジェクトストアの、2つのスレッドがあります。スケジューラは、リソース(利用できるCPU/GPU、メモリ等々)の状況を共有し合い、アプリで指定した条件に合うノードに分散させたい処理を割り当てます。オブジェクトストアは、分散させたい処理の中で使っている変数を、クラスタ間で共有する場合に用いる共有メモリです。Rayでは、Plasma Object Storeという、現在はApache Arrowの中で開発されている共有メモリオブジェクトストアを利用しています。
クラスタには、ヘッドノード(Head node)とワーカーノード(Worker node)が存在します。ヘッドノードのDriverは、アプリケーションを最初に実行するプロセスのことであり、Pythonであれば、__main__を実行するプロセスと捉えてください。
また、ヘッドノードには、Global Control Store (GCS)があります。GCSは、どこにActorがあるか、など、クラスタの内部管理用のメタデータを管理するデータストアです。これは、基本的に開発者が操作するものではありません。
クラスタの構築
このクラスタ構成を構築する方法は、2通りあります。1つは、ノード構築コマンドを使って手動で構築する方法、もう一方は、Cluster LauncherというRay内のツールを用いる方法です。
まずは、手動でクラスタを構築する方法です。
最初に、ヘッドノードを構築します。やる事は、rayのインストールの他には、コマンド1つだけです。
# ヘッドノード用の環境に入る
pip install -U ray
ray start --head --port=6379 # ヘッドノードの構築
1,2秒後に、以下のような出力が出ます。
Local node IP: xxx.xxx.xxx.xxx
2020-12-13 10:11:48,321 INFO services.py:1090 -- View the Ray dashboard at http://localhost:8265
--------------------
Ray runtime started.
--------------------
Next steps
To connect to this Ray runtime from another node, run
ray start --address='xxx.xxx.xxx.xxx:6379' --redis-password='xxxxxxxxxx'
Alternatively, use the following Python code:
import ray
ray.init(address='auto', _redis_password='xxxxxxxxxx')
If connection fails, check your firewall settings and network configuration.
To terminate the Ray runtime, run
ray stop
出力の指示に従って、ワーカーノードを構築します。
# ワーカーノード用の環境に入る
pip install -U ray
ray start --address='xxx.xxx.xxx.xxx:6379' --redis-password='xxxxxxxxxx'
1,2秒後に、以下のような出力が出ます。
Local node IP: xxx.xxx.yyy.yyy
--------------------
Ray runtime started.
--------------------
To terminate the Ray runtime, run
ray stop
手動でも特に大変ではありませんが、Cluster Launcherを用いると、もっと容易にクラスタを構築できます。
まず先に以下のような構築するクラスタの内容を記載した設定ファイルを用意し、ray up <ファイルパス>をするだけです(AWSの場合は、事前にAWSアカウントの用意、boto3のインストール、クレデンシャルの設定が必要です)。
cluster_name: basic-ray
max_workers: 0 # this means zero workers
provider:
type: aws
region: ap-northeast-1
availability_zone: ap-northeast-1
auth:
ssh_user: ubuntu
setup_commands:
- pip install ray[all]
立ち上がったクラスタに、アプリケーションをアップロードし実行する場合は、ray attach、ray rsync-up、ray execコマンドを実行します。
AWS以外にも、他のクラウドベンダや、自身で用意したKubernetesクラスタにも構築できます。その際の設定ファイルなどは、こちらのCluster Launcherのドキュメントを参照してください。
クラスタ上でアプリを実行
では、最後にクラスタ上で分散処理を実行してみましょう。以下のスクリプトを、クラスタ内のどこか(ワーカーノードでもOK)に置いて、実行しましょう(先程のray attach、ray rsync-up、ray execコマンドを利用しても良いです)。
import ray
import ray._private
import time
ray.init(address="auto")
@ray.remote
def f():
time.sleep(0.01)
return ray._private.services.get_node_ip_address()
# Get a list of the IP addresses of the nodes that have joined the cluster.
print(set(ray.get([f.remote() for _ in range(1000)])))
このスクリプトでは、@ray.remoteの付いた関数が、その関数の処理を実行したノードのIPアドレスを返すため、1000回の処理の実行場所のIPアドレスのリストが生成され、それが集合(set)になります。その結果、クラスタに含まれるノードの数が1000未満の場合は、Rayが処理を均等に割り振るため、ノードのIPのリストが出力されるはずです。
ちなみに、ray 1.0.0より前は、ノードのIPアドレスを出力する機能が、ray以下にパブリックな機能として存在していたのですが、ray 1.0.0以降は、ray._privateに移動し、プライベート化されているので、上記スクリプトは推奨されていない処理だと思います。
活用事例
最後に、Rayで何を作れそうかのイメージを掴んで頂くために、Ray Summitの情報から、活用事例をピックアップします。
(ほぼ全てのセッションは、Youtubeでも公開されています。こちらのRay Summitのスケジュール表からたどれます。)
Rayを用いて金融サービスの開発プラットフォームを開発 (Ant Group)
Ant Groupは中国のアリババのグループ企業であり、Alipayを運用する企業です。Ant Groupのユーザーは、13億人以上おり、大量のデータをサービス開発に活用しています。
ただし、様々な新しいサービス・機能を開発する上で、データの処理は画一的であるわけがなく、ストリーミング処理、バッチ処理、グラフ理論系処理、OLAP、ディープラーニングなどなど、様々です。そのため、従来は、それぞれの処理パラダイムごとに言語、OSS、システムが異なり、サービスの開発者が勉強することが膨らみました。
そこで、Rayのクラスタを共通基盤として、Rayが提供するAPIを用いて、先程の処理パラダイムを実現するフレームワークを開発し、自社のサービス開発者に開発プラットフォームを提供しています。これにより、多様な処理パラダイムを有するデータ分析基盤においても、下回りにRayに集約して依存するOSSなどを減らし、学習コストの低減、プラットフォームの進化可能性の向上を実現させています。
また、Microsoftも、機械に動作を教える強化学習サービスをRayを用いて構築し、サービス開発を行う顧客へ提供しているそうです。
プロトタイプのスケールアウトに向けたライブラリ拡張 (Intel)
データ分析を行うほぼ全ての人は、Pandasというライブラリを利用していると思います。しかしPandasは分散処理を意識したスケーラブルなツールではありません。そのため、ローカル環境で何らかのプロトタイプを開発しても、大量データがある本番システムに適用しようとした場合、Sparkを利用するコードなどに書き直してシステム化しないといけませんでした。
そこで、Intelは、RayでPandasのDataFrameを並列に処理する、MODINという新たなライブラリを開発しています。
従来、import pandas as pdと書いていたところを、import modin.pandas as pdとし、数行のクラスタ構成の設定をするコードを追記するだけで、Pandasの処理がスケールアウトするようになるそうです。
この事例はライブラリ開発でしたが、皆さんもPoCやプロトタイプ開発にRayを使えば、本番移行する際に、少ないコード改変でスケールさせられます。
興味を持たれた方へ
Rayは、関数の分散、アクターの分散、という分散処理に必要最小限のコアAPIを用意し、プロセスの管理等、面倒なところを管理してくれます。そのため開発者は、多くの開発者が慣れ親しんだ手続き型言語のイメージのまま、ドメインロジックにフォーカスしつつ、分散処理を含むスケーラブルなアプリを開発できます。
ただし、最後に注意点も書いて終わりにしたいと思います。
もし本格的にRayを本番システムに活用しようとする場合は、Rayの内部ロジックをしっかり理解するべきに思います。それは、Rayの制限という意味ではなく、分散処理自体が、インフラやアプリの障害も考慮した高信頼なシステムを作るためには、インフラ、ミドルウェア、アプリの様々な仕様を理解しておく必要があるためです。
例えば、共有メモリオブジェクトストレージに保存された変数のライフタイム、AWS LambdaのStep Functionsのような依存関係のある非同期呼び出しにおける処理やアクターの管理、非同期実行中の処理が動くサーバの障害における再実行ロジックなど、今回記載していない、重要な点は多くあります。
今回の記事では、Rayを広めるための入門編ということで(というのは名目であり単に疲れたので)そこまでは説明しませんが、Ray1.0がリリースされた際に公開されたRay 1.0 Architecture Whitepaperに、内部ロジックの詳細が解説されています。比較的、内容は分かりやすいので、本番利用される方は一読することをおすすめします。
- PythonはPython Software Foundationの登録商標です
- KubernetesはLinux Foundationの登録商標です
- Hadoop, Spark, Storm, FlinkはApache Software Foundationの登録商標です
- AlipayはAlibaba Group Holdingの登録商標です
- AWS及びその製品名はAmazon Web Serviceの登録商標です
- YoutubeはGOOGLE LLCの登録商標です