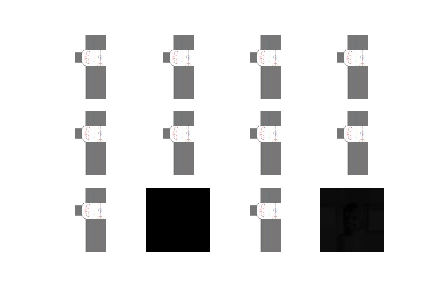はじめに
機械学習、特にdeep learningではデータが命である。ここでは、顔画像から年齢・性別を推定するタスクの学習に利用できるIMDB-WIKIデータセットを紹介する。
本稿では、学習のためのデータの整形まで。次回はCNNを利用した年齢・性別推定CNNの学習をやりたい。
コードは下記。
https://github.com/yu4u/age-gender-estimation
IMDB-WIKIデータセット
このデータセットは、Internet Movie Database(IMDb; 映画やテレビ番組の俳優に関するオンラインデータベース)およびWikipediaをクローリングして作られたデータベースで、プロフィール画像、プロフィール画像から顔領域を抽出した画像、人物に関するメタデータから構成される。IMDbには、460,723枚、Wikipediaには62,328枚の顔画像が含まれる。
このデータセットは、ChaLearn apparent age estimation challengeという画像から年齢推定を行うコンペの優勝チームが、事前学習のデータセットとして利用した(その後、コンペの訓練データでfine-tuning)
データセットの取得
オリジナルの画像は非常にサイズが大きいので、顔領域を抽出した画像およびメタデータのアーカイブをダウンロードする。
# IMDbのデータ
wget https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/static/imdb_crop.tar
# Wikipediaのデータ
wget https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/static/wiki_crop.tar
上記のアーカイブ内の.matファイル(Wikipediaならwiki.mat)にメタデータが全て格納されている。Matlabのデータだが、scipyで下記のように読み込める。
meta = scipy.io.loadmat("wiki.mat")
含まれているデータは下記の通り。
-
dob:生年月日 -
photo_taken:写真が撮影された「年」 -
full_path:画像のパス -
gender:性別 -
name:名前 -
face_location:顔領域の矩形情報 -
face_score:顔検出スコア -
second_face_score:2つ目に大きい顔検出スコア
これらは下記のように取得できる。
full_path = meta[db][0, 0]["full_path"][0]
dob = meta[db][0, 0]["dob"][0]
年齢の計算
画像に写っている人物の年齢は直接メタデータに含まれていないので計算する必要がある。方針としては、撮影日時(photo_taken)から生年月日(dob)を引けば良いが、下記のような細かい対応が必要となる。
まず、dobは、Matlab serial date numberにフォーマットされた値で、時間情報に変換しないと使えない。Pythonにも同様のフォーマットを扱う機能があり変換することができるが、Matlabは西暦0年1月1日からの日数として定義されるのに対し、Pythonでは西暦1年1月1日からの日数として定義されているという罠がある(なんだそりゃ)。というわけで、下記のように変換する必要がある(西暦0年はうるう年!)
python_datetime = datetime.fromordinal(matlab_serial_date_numer - 366)
また、photo_takenは年の情報しかないので、期待値としてその年の真ん中の日時を利用するとすると、下記のように年齢が求められる。
def calc_age(taken, dob):
birth = datetime.fromordinal(max(int(dob) - 366, 1))
# assume the photo was taken in the middle (Jul. 1) of the year
if birth.month < 7:
return taken - birth.year
else:
return taken - birth.year - 1
クリーニング
提供されているデータは基本的にクローリングしてきたデータなので、ノイズデータが多数含まれ、それらを除去する必要がある。例えば、Wikipediaデータベースの場合は下記のようなデータが含まれる。
-
face_scoreが-infなものが18016件存在する -
second_face_scoreがnanでないものが4096件存在する。2つ以上の顔が存在する場合、メタデータがsecond_faceに関するものである可能性がある - 計算した年齢がマイナスだったり100より大きかったりする
ということで、face_scoreが一定以上、second_faceがnan、年齢が0〜100のレンジに入っているものだけを抽出するといったことが必要となる。
データセットの詳細
最後にWikipediaのほうのデータセットの内容を概観する。
詳細は下記。
https://github.com/yu4u/age-gender-estimation/blob/master/check_dataset.ipynb
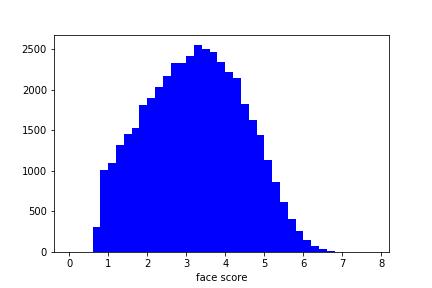
face_scoreの分布。-infは除いたもの。
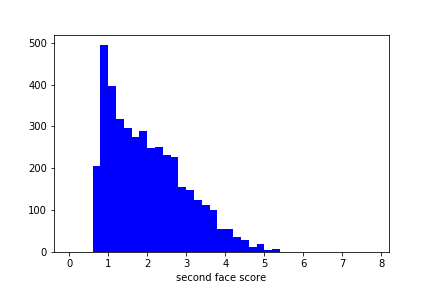
second_face_scoreの分布。nanは除いたもの。
face_scoreが5より大きい画像の例

face_scoreが0から1の画像の例

face_scoreが-infの画像の例

計算された年齢が100より大きい画像の例

計算された年齢がマイナスの画像の例