はじめに
こんにちは! yu-Matsuです!
今回は、LangGraphで作成したエージェントをデプロイ、ホスティングできるサービスである、LangGraph Cloudを触ってみたので、記事にしたいと思います。
現在LangGraph Cloudはベータ版であり、機能が制限されていますが、利用するには課金が必要になりますので、「どんなものか試してみたいけどお金かかるしなぁ...」という方の参考になればと思います!
LangGraph Cloudについて
LangGraph Cloudは、LangGraphを用いて実装されたアプリケーション(エージェント)をクラウド上にデプロイ、ホスティングすることが出来るマネージドサービスです。
デプロイされたエージェントは、水平方向にスケーリング可能であり、耐久性の高いストレージで管理されます。
また、エージェントをAPIやSDKを通して実行する事も可能であり、既存のシステム等にも組み込みやすいです。CLIも用意されており、ローカルで実行サーバーを立てることも可能です。(下、API/SDK/CLIのドキュメント)
LangSmithと統合されているので、デプロイしたエージェントを実行した際にのトレース、ログ情報をLangSmithのUIから確認することが可能です。
さらに、LangGraphのIDEであるLangGraph Studioとも連携しているため、デプロイしたアプリケーションを視覚化し、デバッグや、Human-in-the-Loop、Double Textingといったテストも容易となっています。
※ 注意点としては、現在ベータ版のため、デプロイできるエージェントは最大で1つまでとなっています。また、LangSmithのアカウントが必要かつ課金も必要になります。
環境のセットアップ
まずはLangGraph Cloudを利用するための準備を始めていきます。前提としてLangSmithのアカウントが必要になりますので、お気をつけ下さい!
LangSmithのコンソールは以下のようになっています。LangGraph Cloudを利用するには課金する必要があるため、左メニューバーの歯車アイコンを押下します。

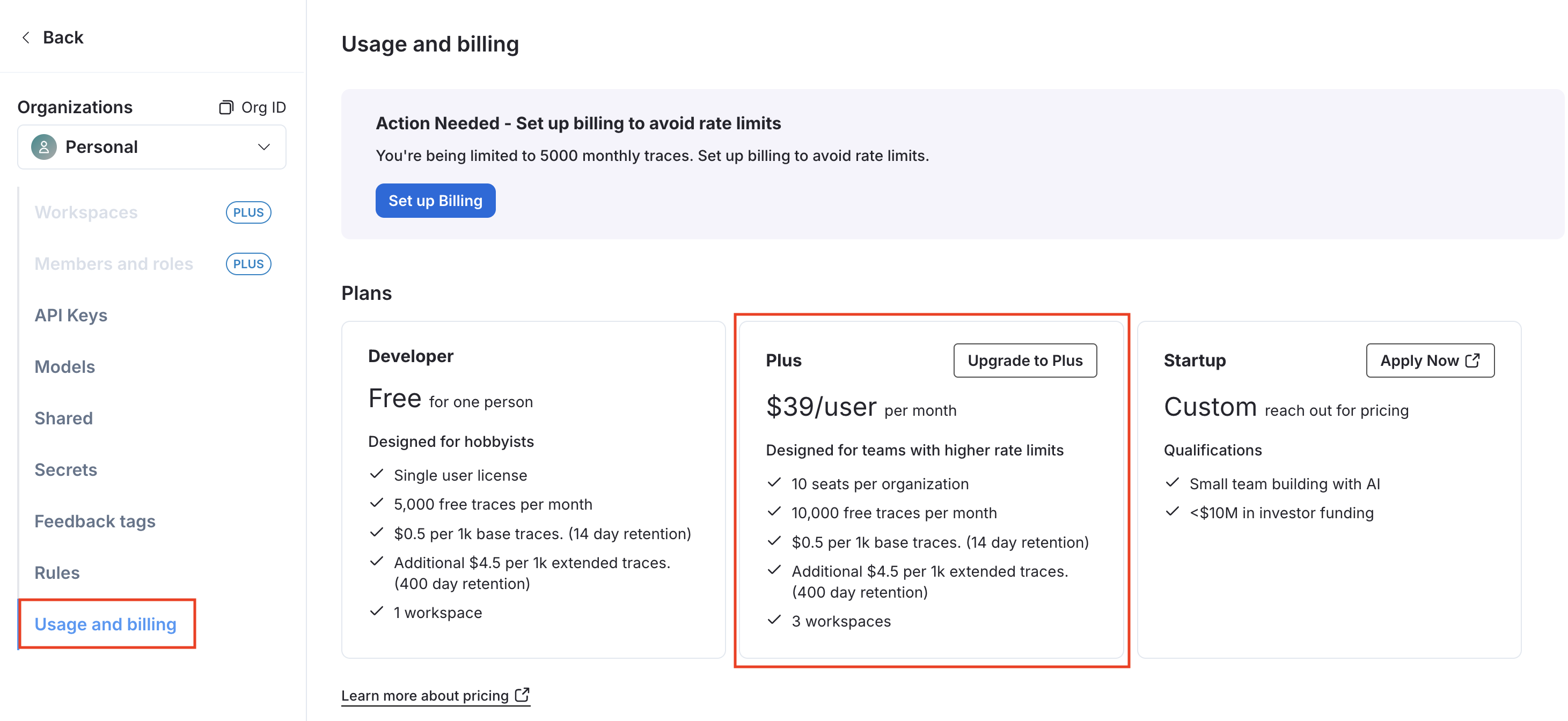
アカウントの設定画面が開くので、左メニューの「Usage and billing」を選択し、開きます。まだ課金設定を行なっていない場合は、プランを選ぶ画面になりますので、今回は「Plus」を選択し、「Upgrade to Plus」を押下します。
すると、Organizationを作成する旨のモーダルが現れますので、適当な名前をつけてOrganizationを作成します。

作成されたOrganizationでプランをSubscribeする画面が開きますので、「Plus」を選択します。

課金の設定モーダルが開くので、必要な情報を入力していきます。「Setup team」で、Organizationに所属させるメンバーを招待する事もできます。
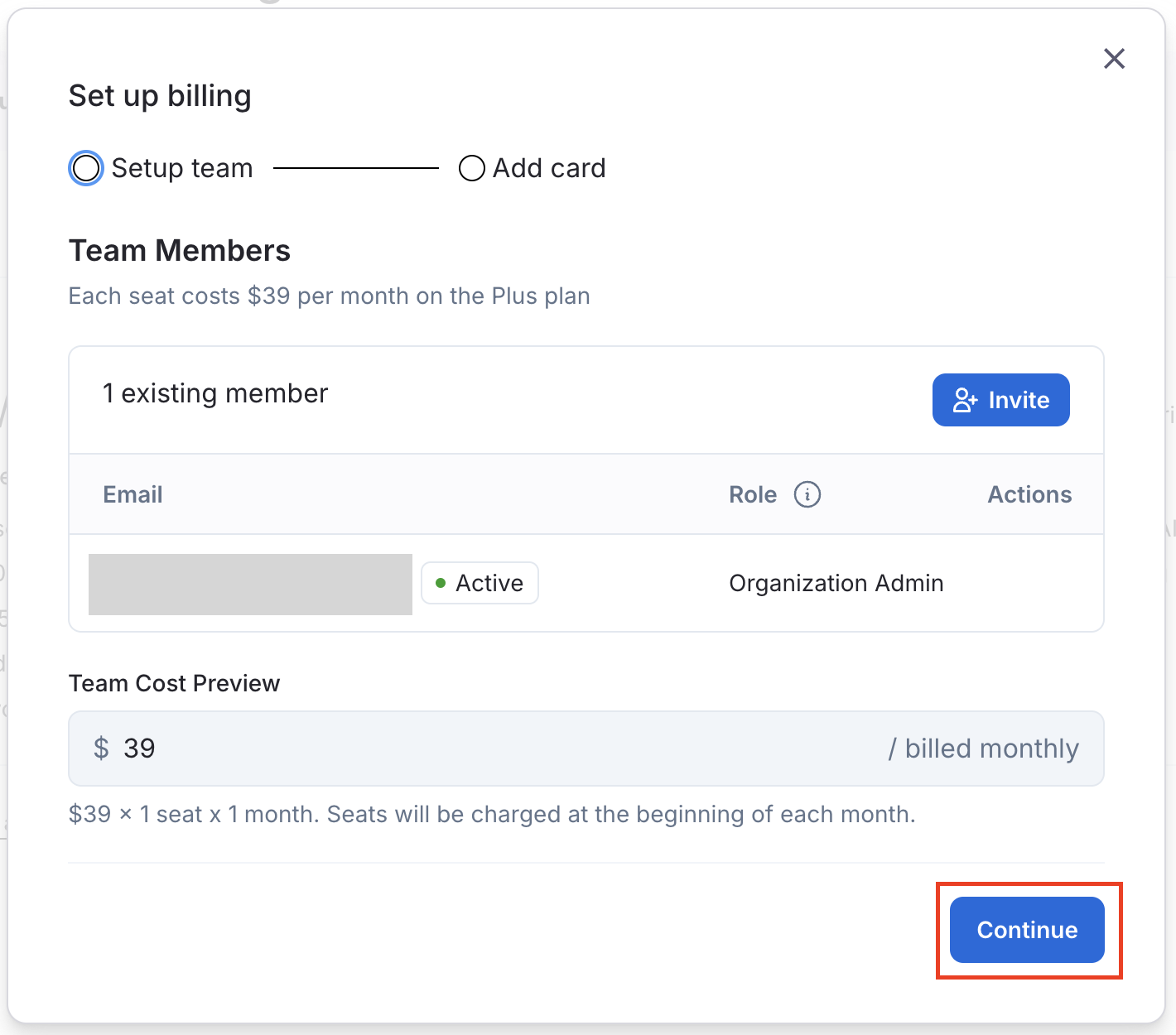
一通り入力が完了しましたら、課金設定が完了です!
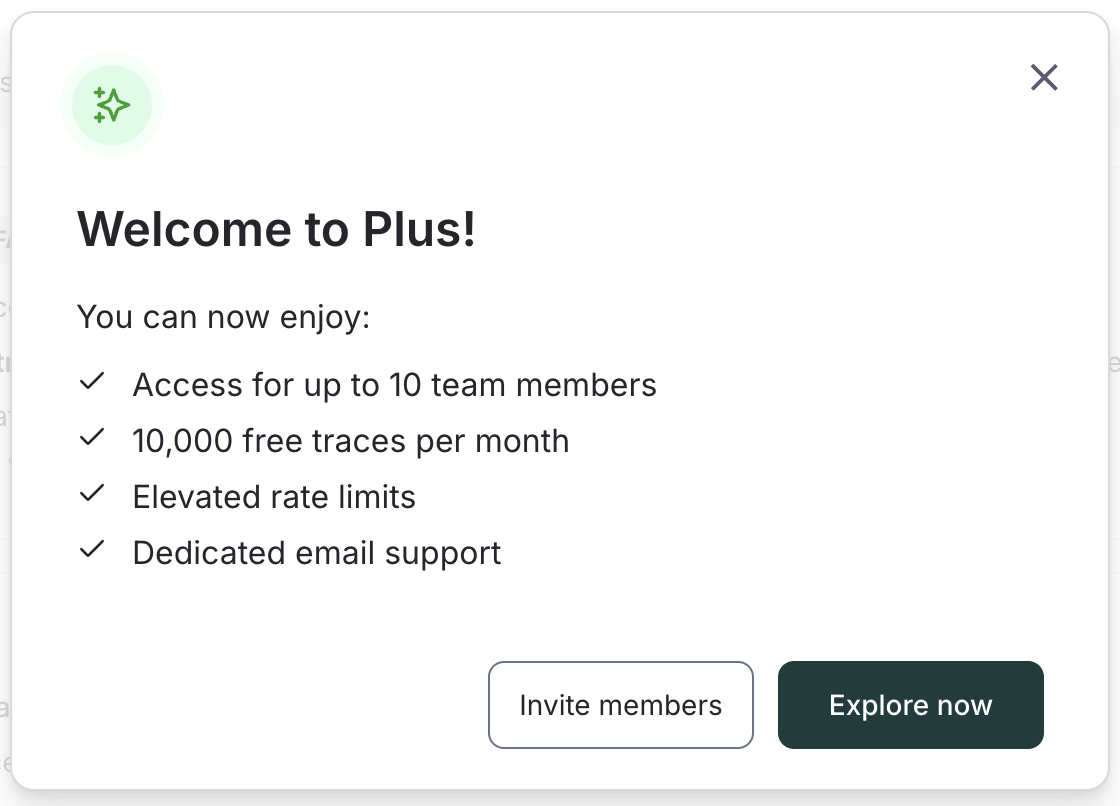
LangSmithのコンソールのTOPに移動し、左メニューから「Deployments」を開くと、LangGraph Cloudが利用出来るようになっています!

また、後で必要になってきますので、LangSmithのAPIキーも発行しておきます。アカウントコンソールのTOPから、アカウントの設定画面を開くとワークスペースの情報が確認できますので、「API Keys」のタブからAPI Keyを作成します。

LangGraphで実装したエージェントのデプロイ
準備も出来ましたので、早速LangGraphで実装したエージェントをデプロイしていきたいと思います!
LangGraph Cloudは GitHub と連携することになるため、適当なリポジトリを作成し、必要なファイルを配置していきます。
まずは、当たり前ですがエージェントのコードが必要になります。今回は、LangGraphのチュートリアルの一つである、「Agent Supervisor」を少し弄ったものを実装しました。コードは以下になります。
from typing import Annotated, Sequence, TypedDict
from langchain.agents.output_parsers.tools import ToolsAgentOutputParser
from botocore.config import Config
import boto3
import functools
import operator
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.tools import PythonREPLTool
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, HumanMessagePromptTemplate
from langgraph.graph import END, StateGraph, START
tavily_tool = TavilySearchResults(max_results=5)
python_repl_tool = PythonREPLTool()
def create_agent(llm: ChatOpenAI, tools: list, system_prompt: str):
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system_prompt,
),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_tools_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)
return executor
members = ["Researcher", "Coder"]
system_prompt = (
"You are a supervisor tasked with managing a conversation between the"
" following workers: {members}. Given the following user request,"
" respond with the worker to act next. Each worker will perform a"
" task and respond with their results and status. When finished,"
" respond with FINISH."
)
options = ["FINISH"] + members
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"Given the conversation above, who should act next?"
" Or should we FINISH? Select one of: {options}",
),
]
).partial(options=str(options), members=", ".join(members))
llm = ChatOpenAI(model="gpt-4-1106-preview")
supervisor_chain = (
prompt
| llm
| ToolsAgentOutputParser()
)
def input_first(state):
init_input = state.get("user_query", "").strip()
return {"messages": [HumanMessage(content=init_input)]}
def agent_node(state, agent, name):
result = agent.invoke(state)
return {"messages": [HumanMessage(content=result["output"], name=name)]}
def supervisor_node(state):
result = supervisor_chain.invoke(state)
next_state = result.return_values["output"]
print('next state:' + next_state)
return {"next": next_state}
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
user_query: str
next: str
research_agent = create_agent(llm, [tavily_tool], "You are a web researcher.")
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")
code_agent = create_agent(
llm,
[python_repl_tool],
"You may generate safe python code to analyze data and generate charts using matplotlib.",
)
code_node = functools.partial(agent_node, agent=code_agent, name="Coder")
workflow = StateGraph(AgentState)
workflow.add_node("Researcher", research_node)
workflow.add_node("Coder", code_node)
workflow.add_node("supervisor", supervisor_node)
workflow.add_node("init_input", input_first)
members = members + ['init_input']
for member in members:
workflow.add_edge(member, "supervisor")
conditional_map = {k: k for k in members}
conditional_map["FINISH"] = END
workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)
workflow.set_entry_point("init_input")
graph = workflow.compile()
# 検証用
if __name__ == "__main__":
while True:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
for s in graph.stream(
{"user_query": user_input},
):
if "__end__" not in s:
print(s)
print("----")
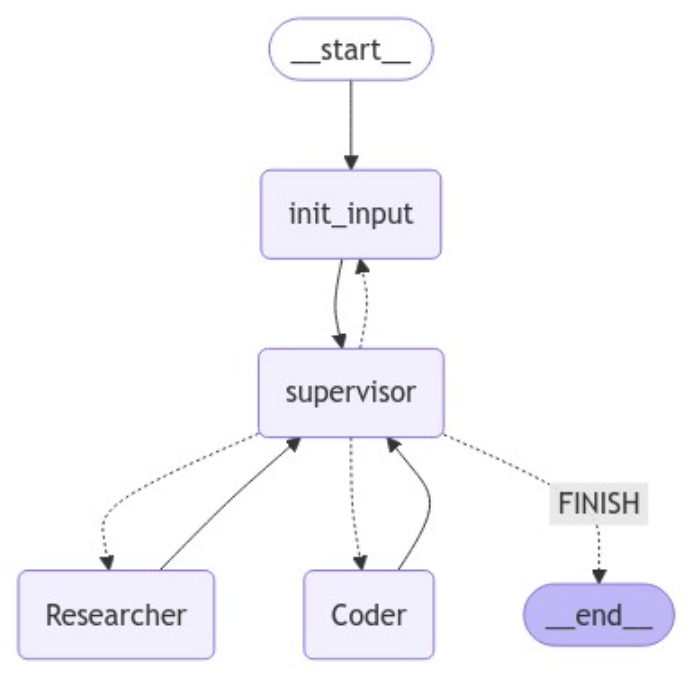
このエージェントは、大まかに以下の3つのエージェントで構成されている、マルチエージェントシステムになります。
- Supervisor:複数のエージェントを従えて、ユーザーの入力をもとに最適なエージェントを呼び出す親分エージェント
- Researcher:ユーザーの入力に対して、Web検索を行い、検索結果をいい感じにまとめて返すエージェント
- Coder:ユーザーがコーディングに関する質問をした際に、要求を実現できるようなコードを作成して返すエージェント
エージェントのコードはこれで以上ですが、その他にも、LangGraph Cloudでアプリケーションを動かすために、langgraph.json というファイルが必要になります。内容は以下のようになります。
{
"dependencies": ["."],
"graphs": {
"agent": "./agent.py:graph"
},
"env": ".env"
}
重要な設定はgraphsフィールドで、エージェントのファイルのパスと、実際にLangGraph Cloudで実行するグラフを指定します。今回、langgraph.jsonとagent.pyは同じディレクトリに配置するので、ファイルのパスは ./agent.py となります。また、実行するグラフに関しては、agent.pyにてグラフを以下のようにコンパイルしているので、graphとなります。
graph = workflow.compile()
langgraph.jsonの設定項目については、以下のドキュメントに詳しく記載されています。
https://langchain-ai.github.io/langgraph/cloud/reference/cli/#configuration-file
また、Pythonではお馴染みの requirements.txt も必要になりますので、agent.py、langgraph.jsonと同じディレクトリに配置します。
langchain
langchain_openai
langsmith
langchain_experimental
langgraph
langchain_core
langchain_community
これで一通りコード周りの準備が完了しましたので、GitHubのリポジトリにpushしておきます。
では、いよいよエージェントをデプロイしていきましょう!!
まず、LangSmithのコンソールの「Deployments」ページを開き、右上の「New Deployment」を押下します。

デプロイの作成画面が開くので、必要な情報を入力していきます。
- GitHubのアカウントに紐づいたリポジトリを選択できるので、エージェントのコードをpushしたリポジトリを選択
- デプロイ名は自分の好きな名前に変更することが出来ます
- config fileはそのまま langgraph.json にします

Environment Variablesで環境変数を設定できます。今回はWeb検索ツールに Tavily を利用していますので、そちらのAPI Keyと、OpenAIのAPI Keyを設定しています。(特に問題がなければ「Secret」にはチェックを入れておきましょう)

これで一通りデプロイ設定は完了したので、画面右上位の「Submit」を押下するとデプロイが始まります!!
デプロイされた(している)エージェントの管理画面が以下になります。(Submitを押下すると自動で遷移します)
ページ中部の「Revisions」で現在のデプロイのステータスを確認できます。下画像では「Building」になっています。ここを押下すると、進捗状況をさらに詳しくみることが出来ます。

詳細画面では、ビルドやデプロイの状況をログで確認することが出来ます。
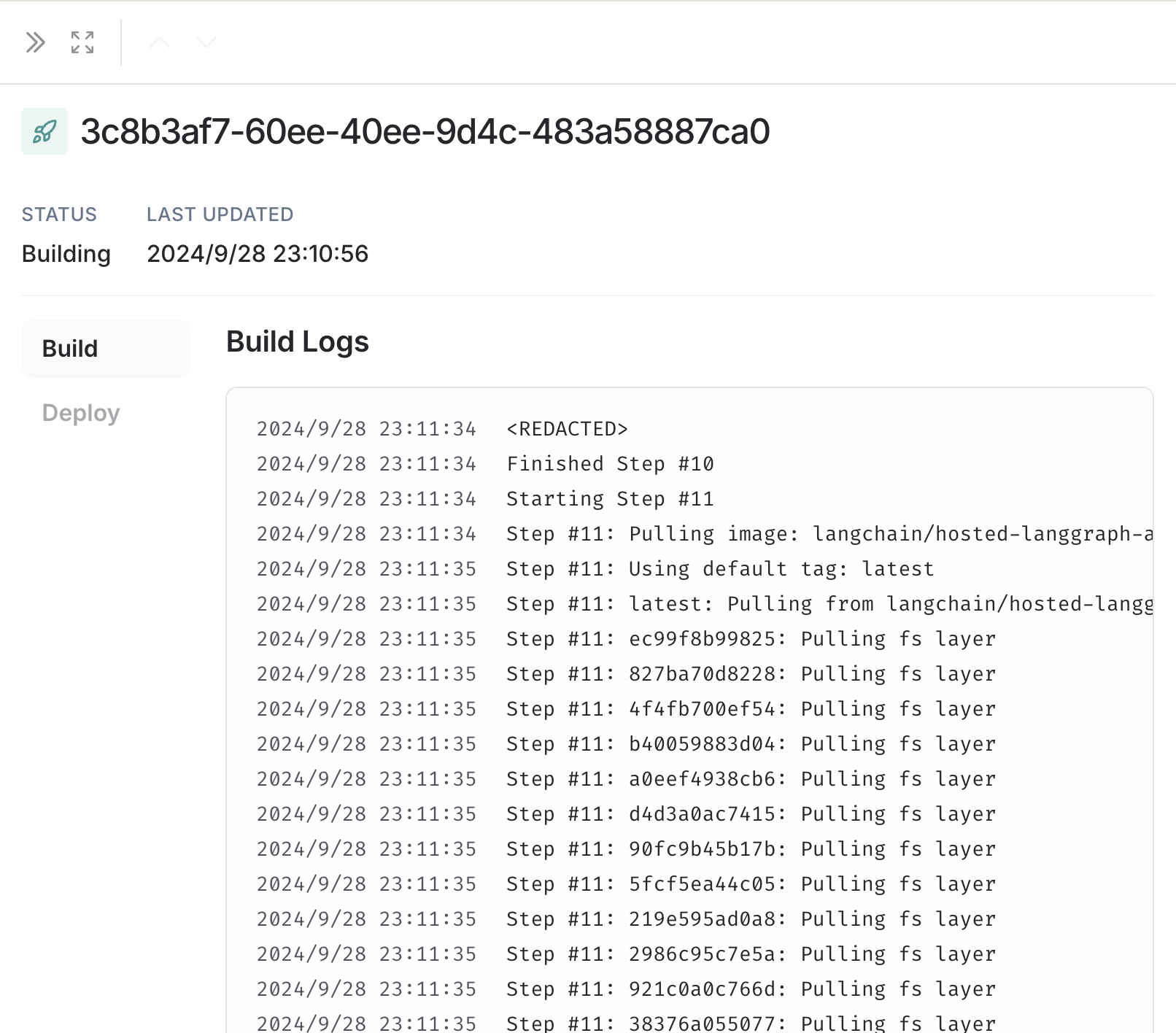
デプロイが完了すると、「Revisions」に表示されるステータスが「Currently deployed」になります!今回はデプロイに15分もかかってしまいました...

それでは、早速デプロイしたエージェントを動かしてみたいと思います!
デプロイしたアプリケーションページの右上の「LangGrpah Studio」を押下します。

すると、LangGraph Studio が起動し、デプロイしたエージェントが表示されています!!

それでは実行してみたいと思います!
今回は「Researcher」エージェントが選択されて実行されることを想定し、「Write a brief research report on pikas.」と「User Query」に入力し、「Submit」を押下します。
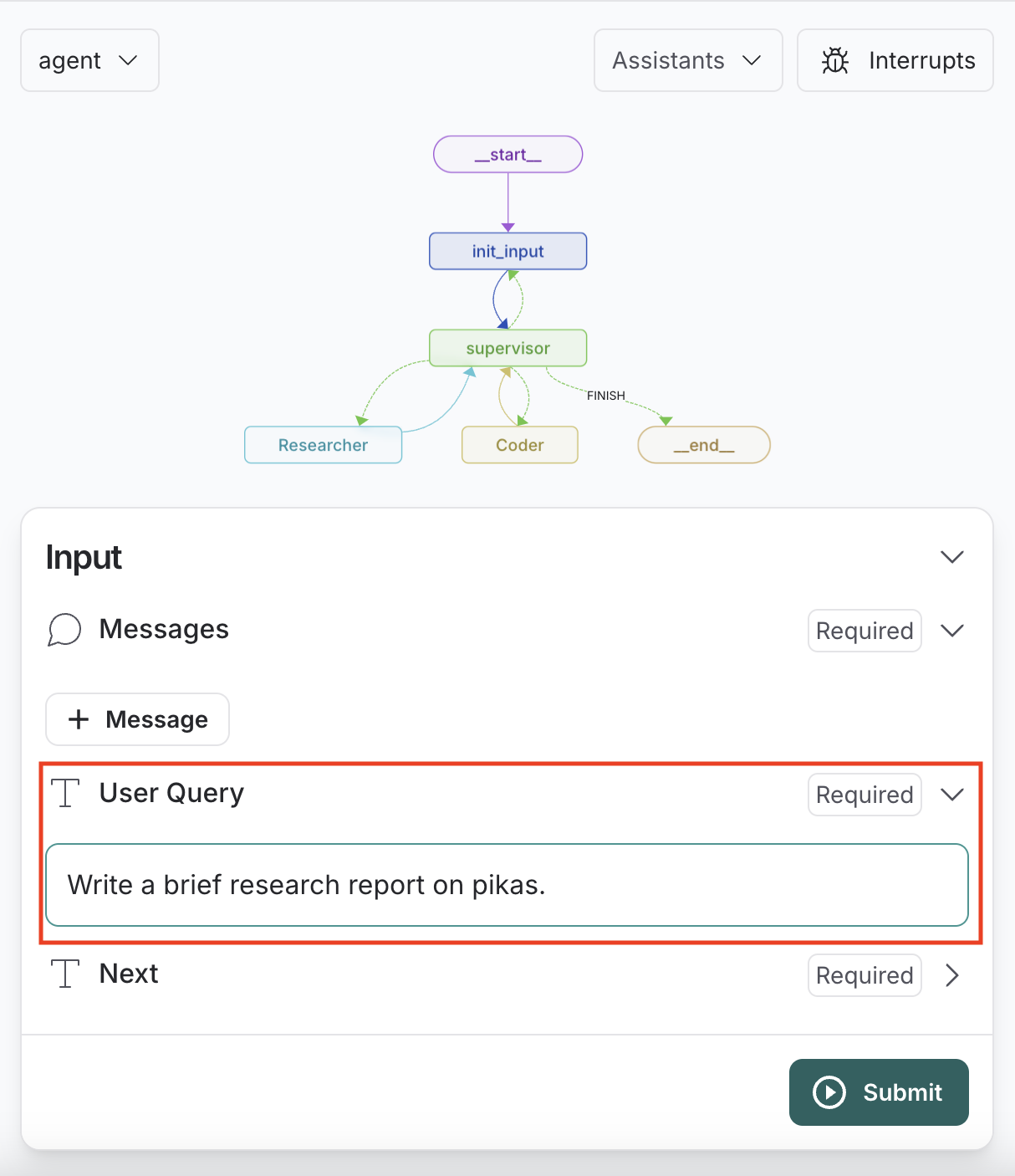
するとエージェントが動き出し、画面右側に進捗状況が表示されます。「supervisor」エージェントの実行結果を見ると、問題なく「Researcher」エージェントが選択されています!「Researcher」エージェントでは、見切れてしまっていますが、Tavilyを利用して「pikas」について検索していることが分かります。
また、画面左側では、現在動いているノードがどこか分かりやすくなっています。

実行が完了して、ピカソに関する調査結果が無事出力されました!(量が多いので見切れています)

もちろん、LangSmithの主要な機能の一つであるトレースも確認出来ますよ!

このように、LangGraph Cloudを利用すると、簡単にLangGraphエージェントをデプロイ、管理できますし、LangGraph Studioと連携しているので、開発もかなりしやすくなります!
ローカルで LangGraph API サーバーを立ててみる
LangGraph Cloudをローカルでも実行することができるので、そちらも試してみたいと思います。こちらの場合はLangGraph Cloud上でのデプロイが必要ないため、より気軽に試すことが出来ます。
まずは、LangGraphのCLIが必要になりますので、インストールします。
pip install langgraph-cli
次に、サーバーを立ち上げる前に .env ファイルを作成し、以下の環境変数を設定します。
- LANGSMITH_API_KEY:環境のセットアップで発行しておいた、LangSmithのAPIキー
- TAVILY_API_KEY:TavlyのAPIキー
- OPENAI_API_KEY:OpenAIのAPIキー
サーバーの立ち上げは、以下のコマンドで行います
langgraph up
コマンドを実行すると、以下のようにサーバーの起動が始まるので、しばらく待ちます。

以下のようなメッセージが表示されたら、サーバーの起動完了です!
% langgraph up
Starting LangGraph API server...
For local dev, requires env var LANGSMITH_API_KEY with access to LangGraph Cloud closed beta.
For production use, requires a license key in env var LANGGRAPH_CLOUD_LICENSE_KEY.
Ready!
- API: http://localhost:8123
- Docs: http://localhost:8123/docs
- Debugger: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:8123
サーバーが立ち上がったので、ローカルでLangGraph Cloudを動かすことが出来るようになりました。実際に動かすには、LangGraph SDKを用いて、以下のようなコードを実装してあげます。
import asyncio
import os
from langgraph_sdk import get_client
client = get_client()
async def get_graph():
assistants = await client.assistants.search()
assistant = assistants[0]
thread = await client.threads.create()
return assistant, thread
async def run_graph(user_input):
await get_graph()
assistant, thread = await get_graph()
input = {"user_query": user_input}
async for chunk in client.runs.stream(
thread['thread_id'],
assistant["assistant_id"],
input=input,
stream_mode="updates",
):
if chunk.data and chunk.event != "metadata":
print(chunk.data)
print("\n")
if __name__ == "__main__":
user_input = input("User: ")
asyncio.run(run_graph(user_input))
実際にこのコードを実行してみると、以下のようになります。
今回は、「Coder」エージェントが選択されるようにしたいので、「Code hello world and print it to the terminal.」と入力してみました。
% python cloud_cdk_local.py
User: Code hello world and print it to the terminal.
{'init_input': {'messages': [{'content': 'Code hello world and print it to the terminal.', 'additional_kwargs': {}, 'response_metadata': {}, 'type': 'human', 'name': None, 'id': None, 'example': False}]}}
{'supervisor': {'next': 'Coder'}}
{'Coder': {'messages': [{'content': "The code `print('Hello, World!')` was executed, and it printed `Hello, World!` to the terminal.", 'additional_kwargs': {}, 'response_metadata': {}, 'type': 'human', 'name': 'Coder', 'id': None, 'example': False}]}}
{'supervisor': {'next': 'FINISH'}}
今回も、「supervisor」エージェントで「Coder」エージェントが選択されていて、CoderエージェントがPythonのコード例を返してくれているので、問題なさそう!
"The code `print('Hello, World!')` was executed, and it printed `Hello, World!` to the terminal."
せっかくなので、簡単なアプリケーションを作ってみる
最後に、Streamlitを使って簡単なアプリケーションを作ってみたいと思います!
先ほどはローカルでサーバーを立ち上げましたが、今回はLangGraph Cloudにデプロイしたエージェントを利用します!
基本的にはローカルサーバーと同じように LangGraph SDK を使うのですが、get_clientをする際に、エージェントのURLを指定してあげる必要があります。
client = get_client(url="デプロイしたエージェントのURL")
エージェントのURLは、デプロイの管理画面の「API URL」から確認することが出来ます。(下画像参考)

Streamlitを用いて実装したアプリケーションのコードが以下になります。
import streamlit as st
import asyncio
from langgraph_sdk import get_client
URL = "デプロイしたエージェントのURL ex)https://xxxxxx.default.us.langgraph.app"
client = get_client(url=URL)
async def get_graph():
assistants = await client.assistants.search()
assistant = assistants[0]
thread = await client.threads.create()
return assistant, thread
async def run_graph(user_input):
assistant, thread = await get_graph()
input = {"user_query": user_input}
output_placeholder = st.empty()
final_response = ""
async for chunk in client.runs.stream(
thread['thread_id'],
assistant["assistant_id"],
input=input,
stream_mode="updates",
):
if chunk.data and chunk.event != "metadata":
# 回答の生成過程をアコーディオン形式で画面出力する
with st.expander("回答中..."):
st.write(chunk.data)
if ("Researcher" in chunk.data):
final_response = chunk.data["Researcher"]["messages"][0]["content"]
elif ("Coder" in chunk.data):
final_response = chunk.data["Coder"]["messages"][0]["content"]
st.subheader("エージェントの回答")
st.write(final_response)
def main():
st.title("LangGraph Cloud デモアプリ")
user_input = st.text_input("何か入力")
if st.button("実行!"):
asyncio.run(run_graph(user_input))
if __name__ == "__main__":
main()
それでは、アプリケーションを起動してみたいと思います。以下のコマンドを実行します。
streamlit run streamlit.py --server.port 8080
すると、ブラウザ上で以下のような画面が開きます。

まずは、入力欄に「Write a brief research report on pikas.」と入力して、「実行!」ボタンを押下してみます。

回答の生成が始まりました!
今までの実行例で、最終的な回答を得るまでに幾つかのステップを踏んでいたと思いますが、このアプリでは各ステップの出力をアコーディオン形式で確認出来るようにしています。
見てみると、「supervisor」エージェントが「Researcher」エージェントを選択出来ていることが分かります。

実行が完了しました!
少し長くなりますが、エージェントの回答は以下のようになりました。しっかりとピカソについての調査結果をまとめてくれています!

ちなみに、「Coder」エージェントの動作確認のために、「Code hello world and print it to the terminal.」と入力してみました。

ちゃんと「Coder」エージェントが選択され、回答が返ってきています!

このように、LangGraph Cloudにデプロイしたエージェントは、API URLさえ分かっていれば簡単にプログラムから呼び出すことが出来るため、チーム内でのエージェントの共有がかなり簡単になります!!
まとめ
LangGraph Cloud自体は前からあったものなのですが、たまたま検証の一環で触る機会がありましたので、記事にしてみました。
実際に使ってみた所感としては、作成したエージェントをデプロイすることで、クラウド上でマネージドで管理されるのは、かなり開発の効率が良くなり便利だなと思いました。APIやSDKから呼び出せるので、チームでエージェントの開発を行う際の管理ツールの選択肢に十分になり得ると感じています。
また、LangGraph StudioやLangSmithといった、既存の便利なサービスとももちろん連携しているため、実行結果を常に可視化し、デバックしながら開発を進められる点も良さそうだと感じました。
一方で Dify や Amazon Bedrock の Prompt Flow のように、ローコードでエージェント(グラフ)を実装できないため、そこまで期待されている方にとっては物足りなく感じるところもありそうです。またベータ版という事もあり、今後の機能拡張にも期待ですね!
今回は以上になります。最後までご精読いただきまして、ありがとうございました!!