はじめに
こんにちは!yu-Matsuです。
皆さん楽しい生成AIライフをお送りでしょうか。
約1週間ほと前に以下のような ELYZAの日本語 LLM が SageMaker JumpStart で利用出来るようになった という内容のAWSブログが投稿されました。以前からSageMakerとELYZAのモデル両方とも触ってみたいと思っていたところだったので、試してみることにしました!
ELYZAの日本語モデルについて
今回利用するモデルは、2023年の8月末に株式会社ELYZAが公開したELYZA-japanese-Llama-2-7bというモデルのシリーズになります。Meta社のLlama 2をベースに本語による追加事前学習を行なった、70億パラメータを持つ日本語言語モデルということで、当時は話題になっていました。これらのモデルはHugging Face Hubで公開されており、ローカルマシンでの利用も可能です。
ちょうどタイムリーなことに、2024年6月26にLlama-3-ELYZA-JP-70Bというモデルが公開され、日本語ベンチマークテストにて、GPT-4やClaude 3 Sonnet、Gemini 1.5 Flashを上回る性能ということで、こちらも絶賛話題になっているところです! チャットのデモが公開されているので、気になる方は試してみてください。
SageMaker JumpStartでデプロイしてみる
※ 以降の作業はバージニア北部リージョンで実施しています
SageMaker Studioの起動
SageMakerからのコンソールを開くと、メニューにJumpStartがありますので(下画像の赤枠)、早速見てみましょう!

「JumpStart」 > 「基盤モデル」を開くと、JumpStartで利用出来るモデル一覧が表示されるので、ELYZAの日本語LLMを探します。今回は ELYZA-japanese-Llama-2-7b-fast-chat を選択しました。
モデルの詳細画面に遷移するので、右上の「Studioでノードブックを開く」を押下します。これで SageMaker Studioが起動するのかと思いきや...
はい、起動出来ませんでした... ドメインとユーザープロファイルを作成する必要があるようなので、「SageMaker ドメインを作成」を押下して作成していきます。
ドメインの設定は「シングルユーザー向けの設定(クイックセットアップ)」で実施します。ドメイン、ユーザープロファイルに加え、IAMロールやStudio Nodebookの作成などを自動で行ってくれます。
設定が完了し、ドメインとユーザープロファイルが作成されました。画面上部のメッセージの通り、ユーザープロファイル名の右の「起動」からSageMaker Studioを起動します。

無事に Sagemaker Studio が起動しました!!
モデルのデプロイ
SageMaker Studioを起動出来ましたので、早速モデルのデプロイをしてみたいと思います! Studioのメニューから「JumpStart」を選択します。
モデルのプロバイダー一覧が表示されるので、「HuggingFace」を選択します。

HuggigFaceのモデル一覧から「ELYZA」で検索すると2モデルヒットしますので、今回利用予定の ELYZA-japanese-Llama-2-7b-fast-chat を選択します。
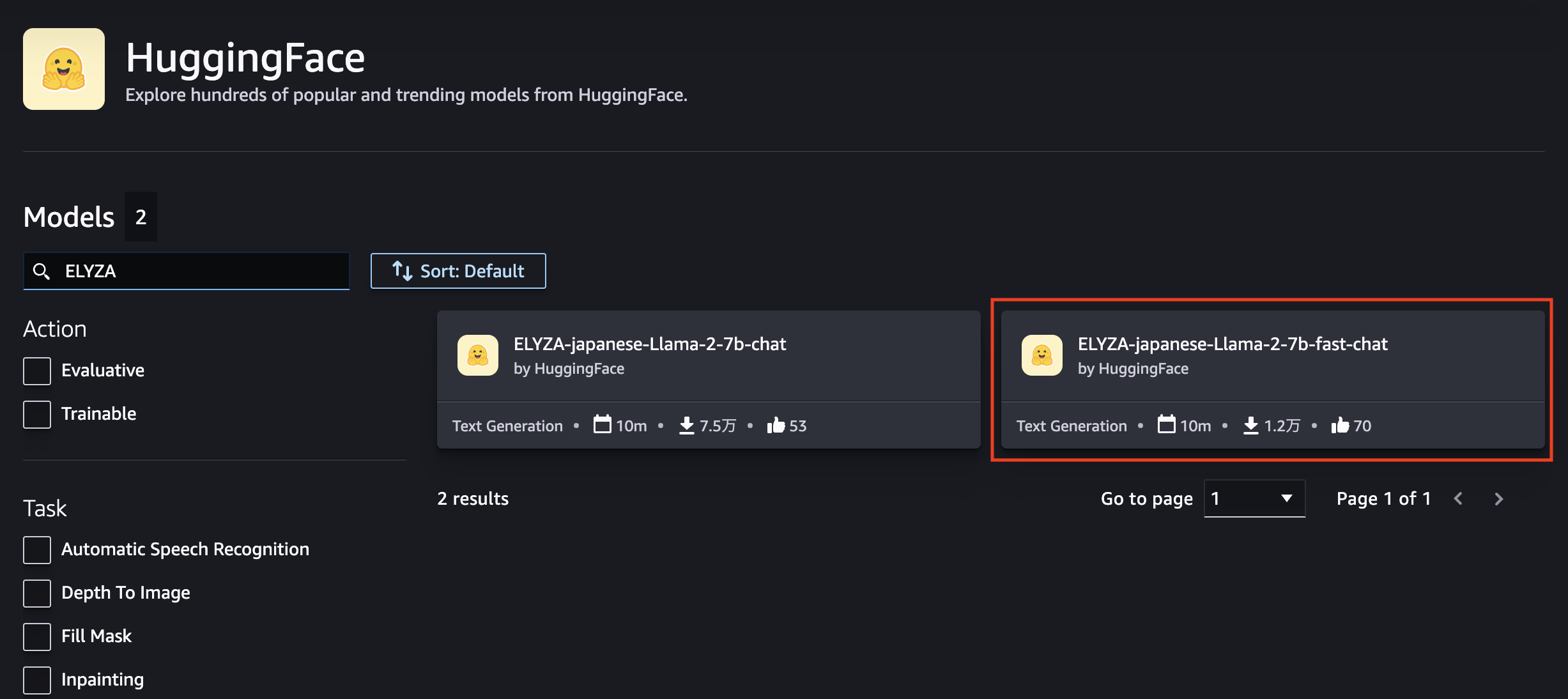
ELYZA-japanese-Llama-2-7b-fast-chat の詳細画面が開きます。ここではモデルについての簡単な説明や利用方法について記載されています。画面右上の「Deploy」からデプロイしてみましょう!
デプロイの設定画面で「I accept the EULA, and read the teams and conditions.」にチェックをつけないとDeployボタンが非活性状態のままなので注意が必要です。その他設定はデフォルトのままデプロイします。
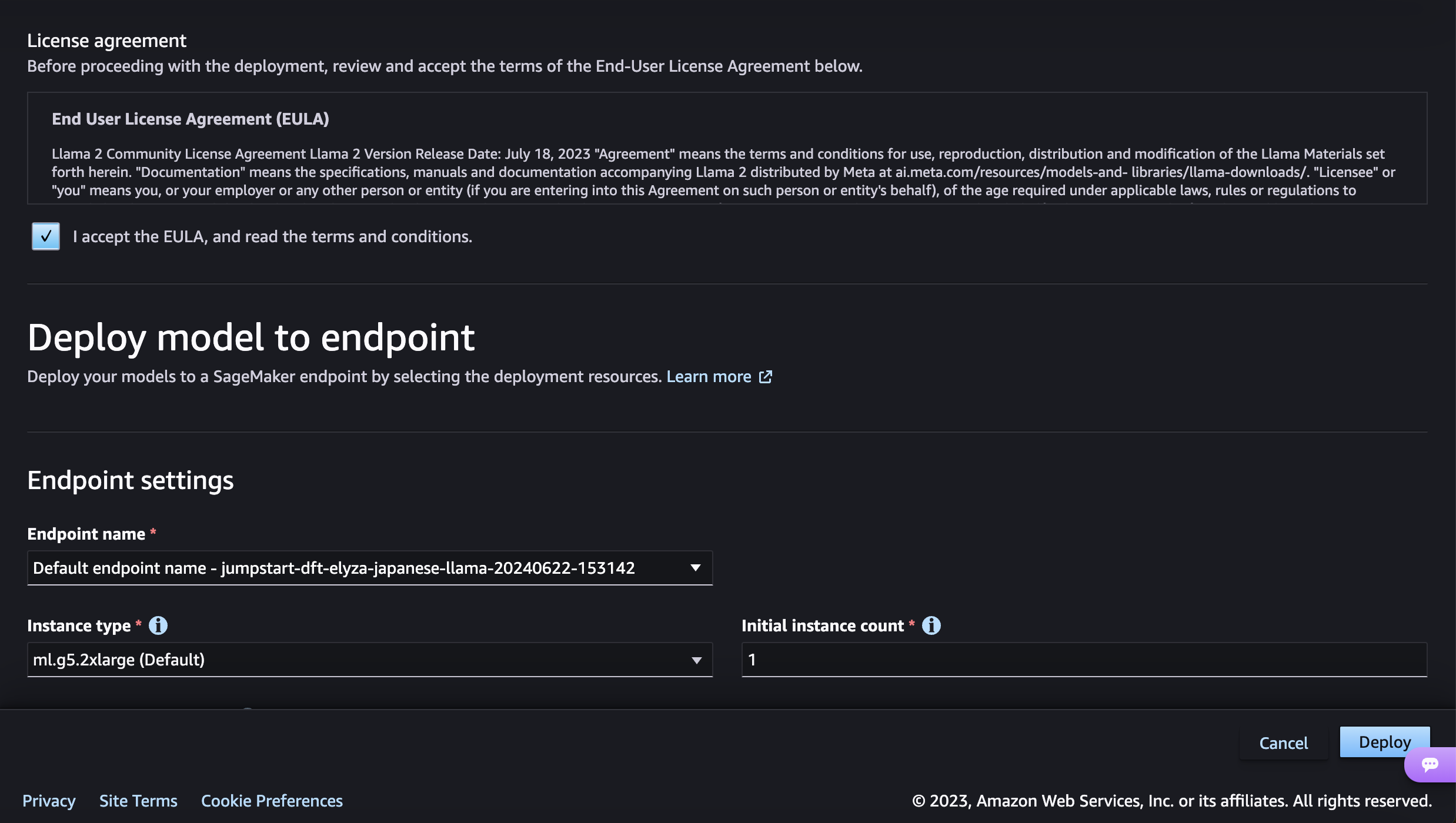
デプロイを開始すると、エンドポイントが作成されます。エンドポイントのStatusが「in Service」になるとデプロイが完了です! とても簡単ですね!
動作確認
モデルがデプロイ出来ましたので、動作確認をしてみたいと思います。エンドポイントの「Test inference」のタブからテスト実行することが出来ます。簡易的なテストであれば、「Test the sample request」を選択します。
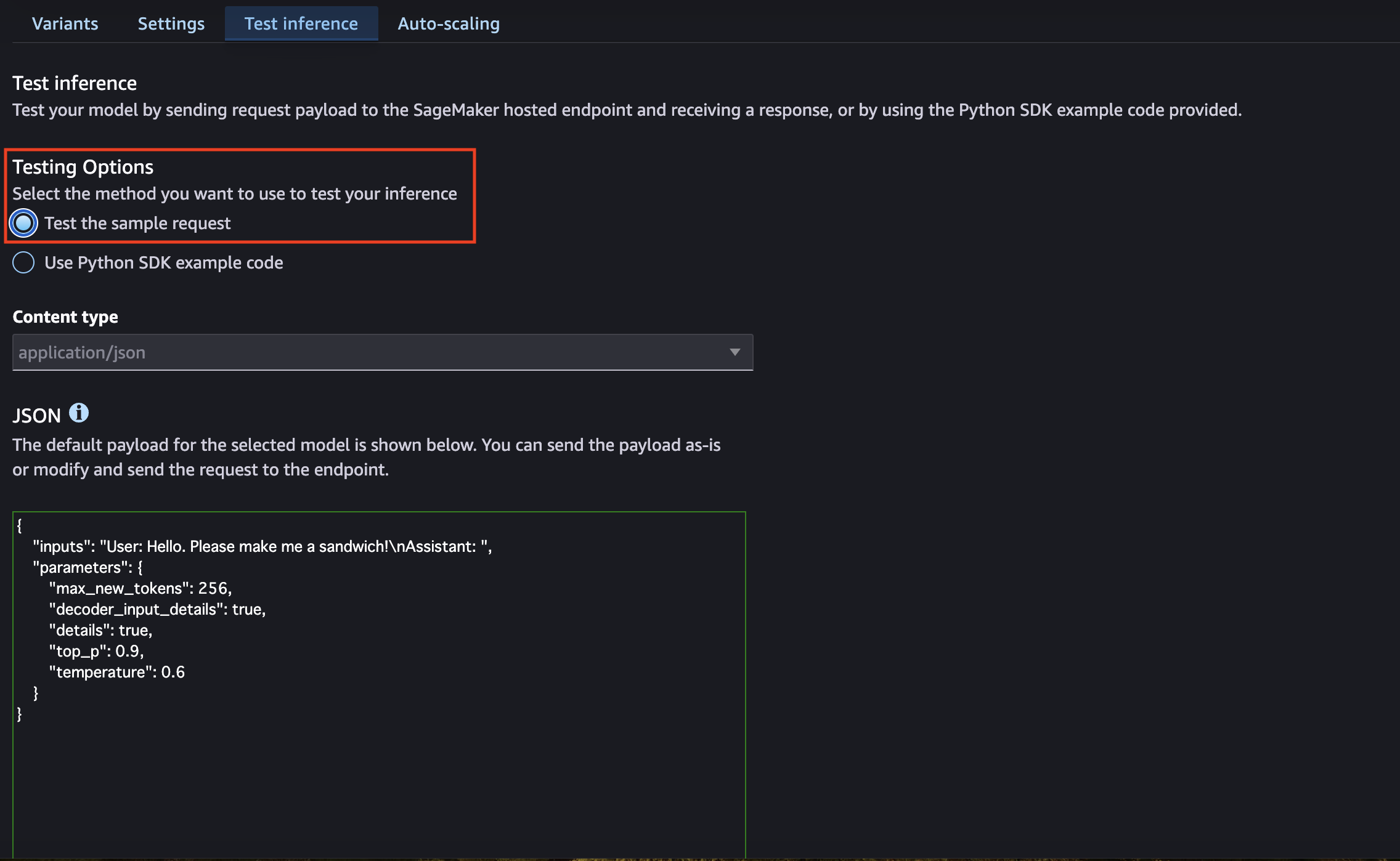
「JSON」の欄にモデルを実行するためのリクエストを入力するのですが、デフォルトのままだと思ったようなレスポンスが得られません。ELYZA-japanese-Llama-2-7b は先述の通り Llama 2 をベースとしており、少し特殊なプロンプト形式をとっているため、そちらに合わせた形でリクエストをしてみます。
<s>[INST] <<SYS>>
{システムプロンプト}
<</SYS>>
{ユーザープロンプト}[/INST]
リクエストの "inputs" を書き換えてリクエストを投げてみました。「Amazon SageMaker について3行で説明してください。」と質問しています。実行結果が右側に出ているのですが、質問内容に関して指定通り簡潔に回答してくれており、内容も問題なさそうなことが分かります。
Amazon SageMaker は、機械学習のプロセスを自動化するサービスです。データ準備、トレーニング、モデルデプロイまで、一貫して管理でき、開発時間を短縮し、モデル品質を向上させることができます。
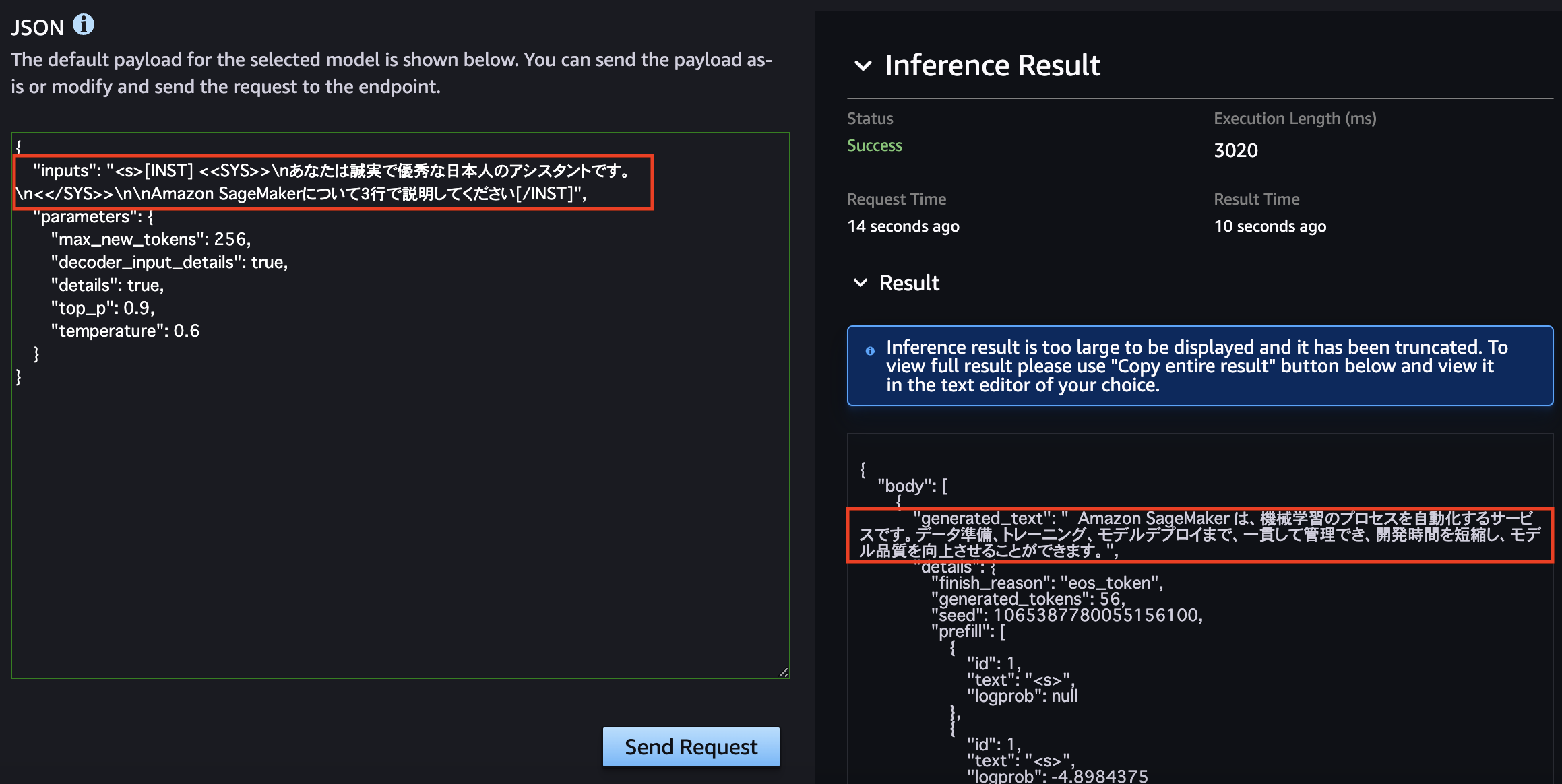
JumpStartではデプロイしたモデルを JupyterLab で動かすことも可能です。今度は「Use Python SDK example code」を選択し、「Open in JupyterLab」を押下します。
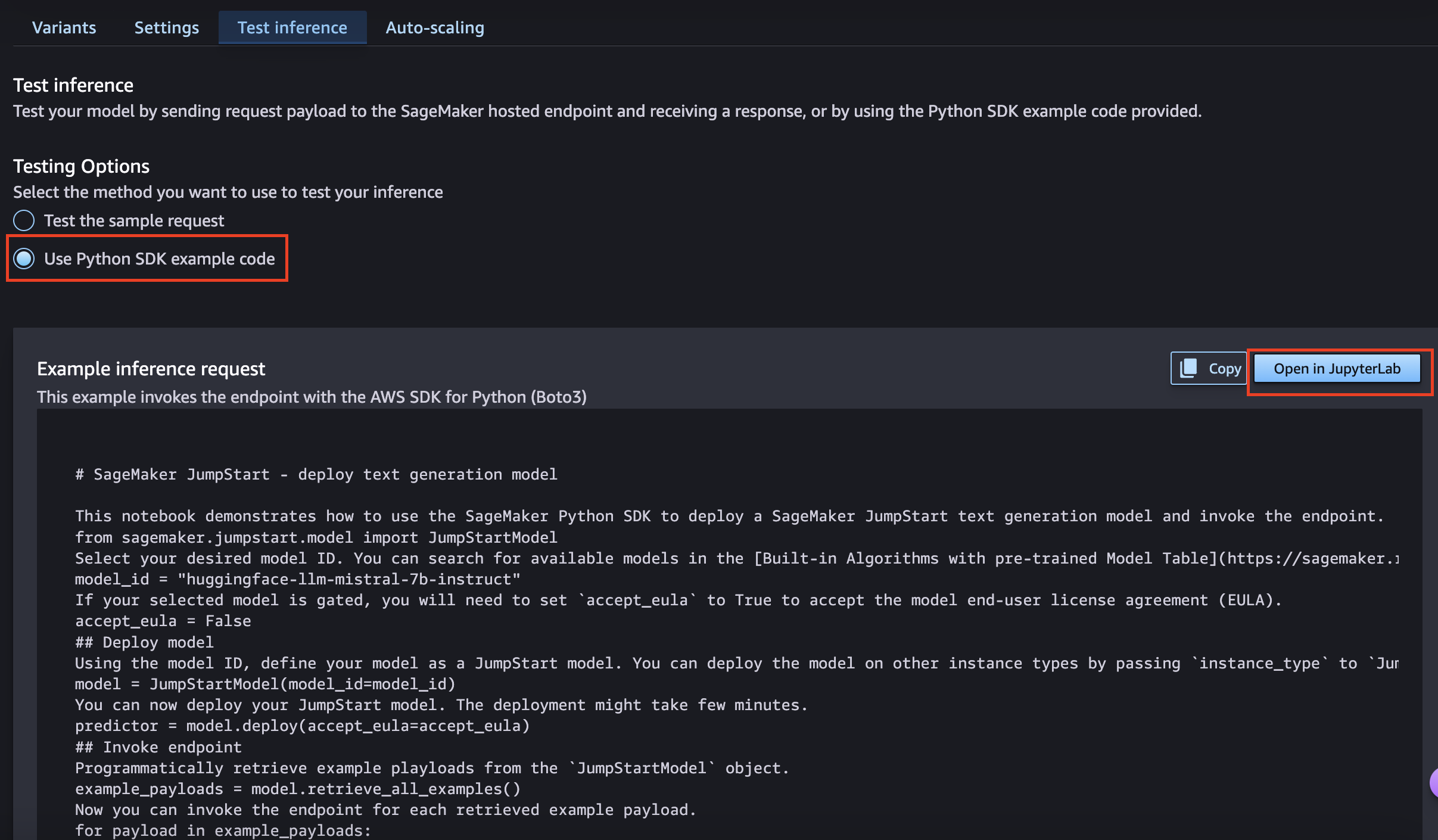
nodebookの作成画面が出ますので、「Create new space」を選択し、新しいnotebookを作成します。
notebookの作成が完了すると、画面下部に以下のダイアログが出るため、「Open JupyterLab」を押下するとnotebookが開きます。

notebook上で以下のようなコードを作成し、実行してみます。記事スペースの都合上詳しい説明は省略しますが、LangChain に SagemakerEndpointというクラスがあるため、今回はこちらを利用してモデルを呼び出すように実装しています。
# LangChainのライブラリのインストール
!pip install langchain==0.2.0
import json
import boto3
from typing import Dict
from langchain_community.llms import SagemakerEndpoint
from langchain_community.llms.sagemaker_endpoint import LLMContentHandler
from langchain_core.prompts import PromptTemplate
# プロンプトテンプレートの定義
template = """<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです
<</SYS>>
{user_input} [/INST]"""
prompt = PromptTemplate.from_template(template)
# SageMakerのクライアントインスタンスを作成
client = boto3.client(
"sagemaker-runtime",
region_name="us-east-1",
)
# Contentハンドラの定義
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -> bytes:
input_str = json.dumps({"inputs": prompt, "parameters": model_kwargs})
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"]
content_handler = ContentHandler()
# SagemakerEndpointでデプロイしたモデルのエンドポイント名を指定し、モデルのインスタンスを作成
llm=SagemakerEndpoint(
endpoint_name="モデルのエンドポイント名",
client=client,
model_kwargs={"temperature": 0.9, "max_new_tokens": 256},
content_handler=content_handler,
)
# Chainの作成
chain = prompt | llm
# Chainの実行
response = chain.invoke({
'user_input': 'Amazon SageMaker について3行で説明してください。'
})
# 実行結果を出力
response
簡易的なテストと同じように「Amazon SageMaker について3行で説明してください。」と質問してみました。実行結果が以下になります。

Amazon SageMaker は、機械学習モデルをトレーニング、デプロイ、スケーリングする一貫したプロセスを自動化するサービスです。 SageMaker を使用することで、データサイエンティストはクラウド上で簡単に機械学習パイプラインを構築し、高度な深層学習モデルを迅速に開発、トレーニング、デプロイすることができます。
良い感じで SageMaker について分かりやすく簡潔に説明してくれています! これで、プログラムからもモデルのエンドポイント名を指定することで、デプロイしたモデルを実行出来ることが分かりました!
Streamlitで簡易的なWebアプリケーションを作ってみる
次は、JumpStartでデプロイしたモデルを利用してStreamlitでWebアプリケーションを作ってみたいと思います!Cloud9上で以下のプログラムを作成しました。
boto3==1.34.87
langchain==0.2.0
langchain-aws==0.1.4
langchain-community==0.2.0
streamlit==1.33.0
python-dateutil==2.8.2
import json
import boto3
from typing import Dict
import streamlit as st
from langchain_community.llms import SagemakerEndpoint
from langchain_community.llms.sagemaker_endpoint import LLMContentHandler
from langchain_core.prompts import PromptTemplate
# Cloud9上ではなく、ローカルなどから実行する際はAWSの認証情報が必要になることに注意
client = boto3.client(
"sagemaker-runtime",
region_name="us-east-1",
# aws_access_key_id='アクセスキー',
# aws_secret_access_key='シークレットキー',
# aws_session_token='セッショントークン',
)
def create_memory_prompt():
'''
会話履歴をLlama2のプロンプト形式に沿う文字列に変換する
Return
----------
memory_prompt : string
会話履歴を文字列に変換したもの
'''
memory_prompt = ''
if len(st.session_state.messages) > 0:
for item in st.session_state.messages:
memory_prompt += "{user} [/INST] {assistant} </s><s>[INST] ".format(
user=item["user"],
assistant=item["assistant"]
)
return memory_prompt
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -> bytes:
input_str = json.dumps({"inputs": prompt, "parameters": model_kwargs})
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"]
content_handler = ContentHandler()
# プロンプトの定義。会話履歴も埋め込めるようになっている
template = """<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです
<</SYS>>
{memory_prompt}{user_input} [/INST]
"""
prompt = PromptTemplate.from_template(template)
llm = SagemakerEndpoint(
endpoint_name="モデルのエンドポイント名",
client=client,
model_kwargs={"temperature": 0.9, "max_new_tokens": 1024},
content_handler=content_handler,
)
chain = prompt | llm
# アプリケーションのページタイトル
st.title("Elyzaモデルのテスト")
# Steamlitのセッション情報に会話履歴messagesを定義する
if "messages" not in st.session_state:
st.session_state.messages = []
# セッションで保持している会話履歴を画面表示する
for message in st.session_state.messages:
with st.chat_message("user"):
st.markdown(message["user"])
with st.chat_message("assistant"):
st.markdown(message["assistant"])
# チャットのユーザー入力欄を定義
if user_input := st.chat_input("お話ししましょう。"):
# ユーザーの入力を画面表示する
with st.chat_message("user"):
st.markdown(user_input)
# Chainの実行を行い、その結果を画面表示する
with st.chat_message("assistant"):
# 現在の会話履歴をLlama2のプロンプト形式に沿う文字列に変換する
memory_prompt = create_memory_prompt()
# Chainの実行
response = chain.invoke({
'user_input': user_input,
'memory_prompt': memory_prompt
})
st.markdown(response)
# ユーザーの入力とChainの実行結果野ペアを会話履歴に追加する
st.session_state.messages.append({'user':user_input, 'assistant':response})
今回は会話履歴も考慮するように実装しています。履歴の実装に関しては、以下の記事を参考にしています。Streamlitのセッションに保存されている会話履歴を、create_memory_prompt関数を使ってLlama 2のプロンプトの形式に変換し、埋め込んでいます。
<s>[INST] <<SYS>>
{システムプロンプト}
<</SYS>>
{ユーザーメッセージ1}[/INST]{モデルの応答1}</s><s>[INST]
{ユーザーメッセージ2}[/INST]{モデルの応答2}</s><s>[INST]
....
{ユーザープロンプト}[/INST]
それではプログラムを実行していみたいと思います。以下のコマンドをCloud9のターミナルから実行します。
streamlit run elyza-webapp.py --server.port 8080
実行が開始しましたら、Cloud9の画面上部の「Preview」を開き、「Preview Running Application」を押下して、実行中のアプリケーションを開きます。
以下のような画面が出ましたら、ひとまずアプリケーションの実行自体は成功です!

今回は少し複雑なタスクを実行させてみたいということで、ELYZA-tasks-100という日本語instructionモデル評価データセットの中から、「仕事の熱意を取り戻すためのアイデアを5つ挙げてください。」という入力を少し変えて「仕事の熱意を取り戻すためのアイデアを3つ挙げてください。」と質問してみました。(数を変えただけ)
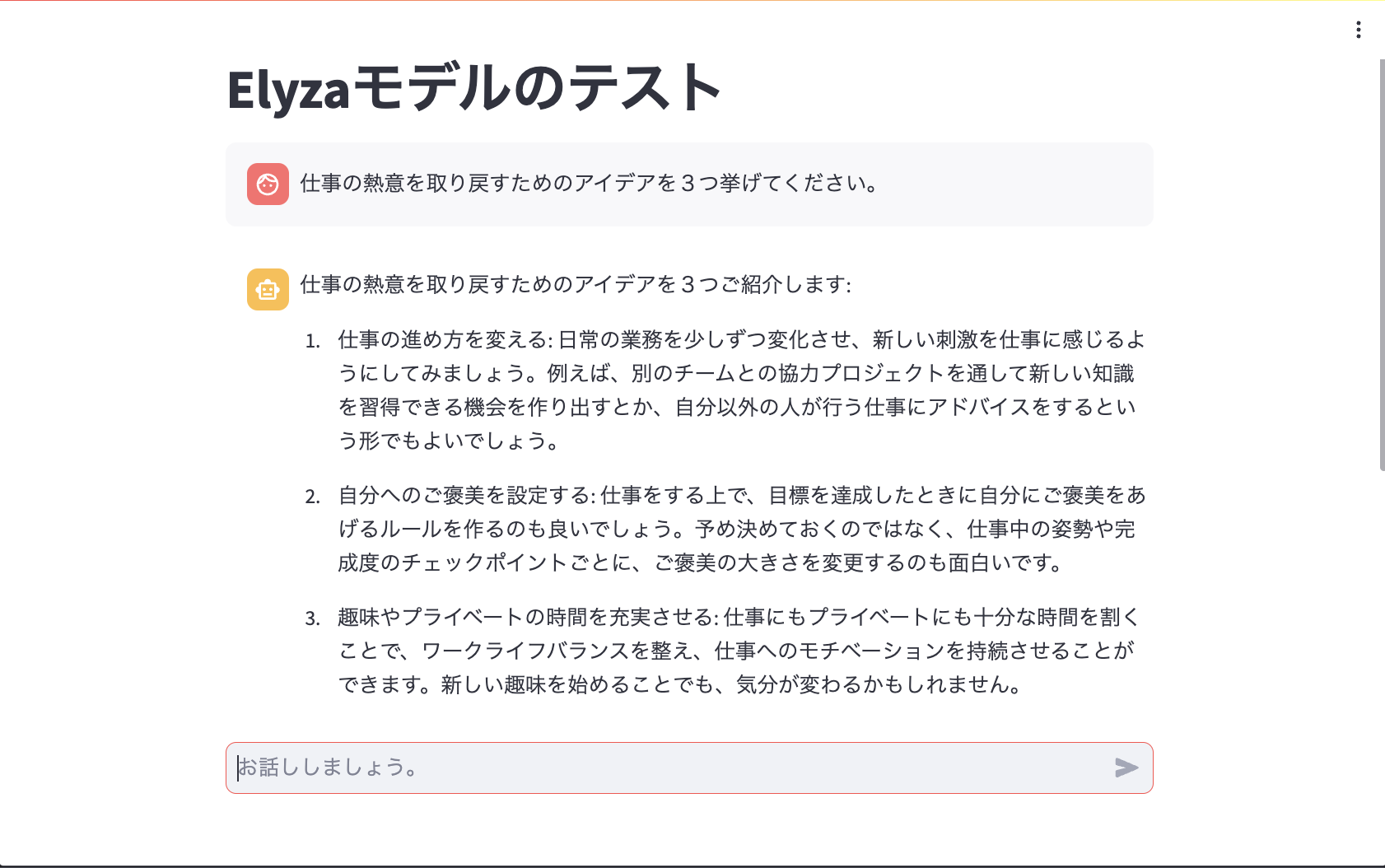
モデルの回答はというと、いい感じの答えを返してくれているように感じます! 日本語の不自然さもほぼ感じられません!
続きまして、会話履歴が効いているかどうかも確認しておきたいと思います。3つ目のアイデアに関して具体的にどのようなことをするのがオススメか聞いてみます。
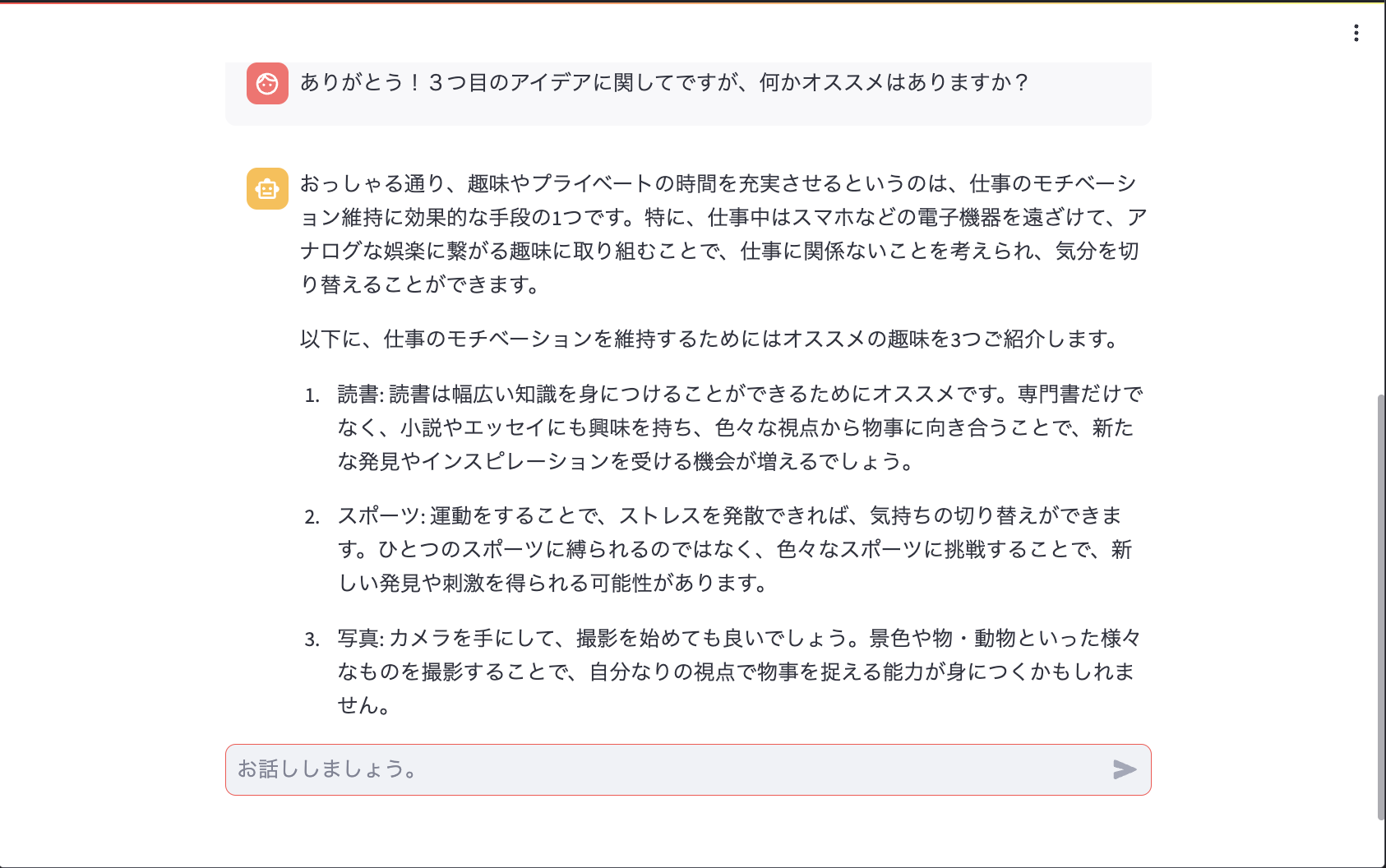
読書、スポーツ、写真、という3つのオススメのプライベート時間の過ごし方について回答してくれました! 事前の自信の回答を加味した上で回答してくれていることが分かります。ただ、冒頭の「おっしゃる通り〜」からはじまる2文に関しては、前後の文脈を踏まえると怪しい部分がそこそこ見受けられました。とにかく、Streamlitを用いたアプケーション実装も簡単に出来ることが分かりました!!
モデルのエンドポイントの削除
SageMaker JumpStartを試した後に忘れてはいけないのがモデルのエンドポイントの削除です。こちらの作業を忘れてAWSの請求額が大変なことになった!という記事が散見されます。
エンドポイントの削除は、SageMaker Studio上から実施出来ます。左メニューの「Deployments」から「Endpoints」を開きます。作成されたエンドポイント一覧が表示されますので、今回作成したエンドポイントを選択し、右上の「Delete」を押下します。

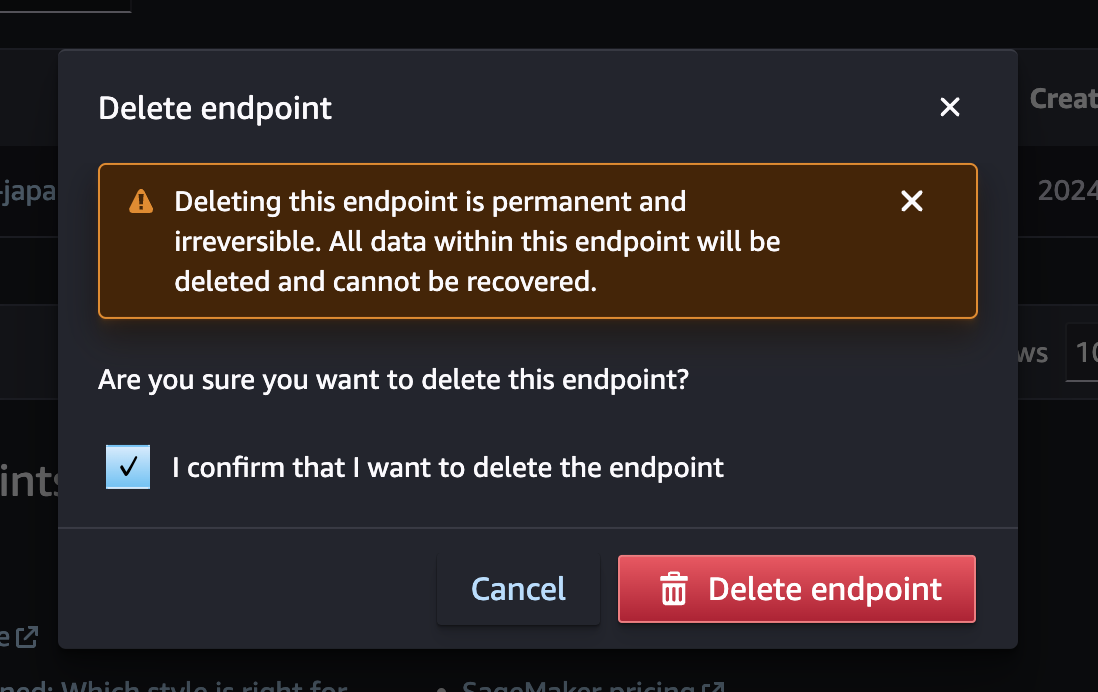
削除確認のダイアログが表示されますので、確認のチェックボックスにチェックを入れ、「Delete endpoint」を押下すると、しばらくするとエンドポイントが削除されます!
まとめ
Amazon SageMaker JumpStartを利用して、ELYZAの日本語モデルであるELYZA-japanese-Llama-2-7b-fast-chatを動かしてみました! ELYZAのモデルはBedrockから利用出来ないので中々手を出せていなかったのですが、JumpStartから利用できるようになったことで、かなり利用の敷居が下がったように感じました。これを機に他のモデルもいろいろ試してみたいと思います! 後は、冒頭で紹介したAWSの記事にあった Bedrockのカスタムモデルインポート にもチャレンジしてみたいところです...
本記事はこれで以上になります! 最後までご精読いただきまして、ありがとうございました!!