はじめに
こんにちは! yu-Matsuと申します。
今回は、前回の記事である「Amazon Bedrockを用いたチャットAPIをコンテナ上で構築! 〜前編:Docker編〜」の続きになります。ご覧になっていない方は是非合わせてみていただければと思います!
目標として、前回作成した Amazon Bedrockを用いたチャットAPI のDockerイメージを、AWS Fargateで動かしたい と思います。
おさらい
前回の記事の内容は以下になります。
- Bedrockのモデルを利用出来るように、コンソール上設定
- チャットAPIを実現するためのメイン処理を実装し、動作確認
- Dockerイメージを作成し、動作確認
メイン処理を実装したコードを再掲します。(一部省略しています。)
import os
〜中略〜
from langchain.memory.chat_message_histories import DynamoDBChatMessageHistory
# Flaskのインスタンスを作成
app = Flask(__name__)
# .envファイルに定義した環境変数をセット
load_dotenv(verbose=True)
dotenv_path = os.path.join(os.path.dirname(__file__), '.env')
load_dotenv(dotenv_path)
# 会話プロンプトのテンプレートの素
template = """
ずんだもんという少女を相手にした対話のシミュレーションを行います。
彼女の発言サンプルを以下に列挙します。
こんにちは、僕はずんだもんなのだ。
ずんだ餅の精なのだ。
ずんだ餅のさらなる普及を夢見ているのだ。
そういうことはこっそりやるものなのだ。
ふむ……。このずんだ餅はなかなか……。うん。
観賞用と保存用、そして布教用に三つ買うのだ。
ゆっくりしていくのだ!
あんころ餅なんかに……絶対負けないのだ!!
バズったので宣伝させていただきます! ずんだ餅はおいしいのだ!
まだ慌てるような時間じゃないのだ。
ずんだもんの魅力で子どもファンをゲットなのだ!
上記例を参考に、ずんだもんの性格や口調、言葉の作り方を模倣し、回答を構築してください。
ではシミュレーションを開始します。
会話履歴:
{history}
Human:{input}
Assistant:
"""
def chat(message, session_id):
# Bedrockのモデルを定義
LLM = Bedrock(
model_id = "anthropic.claude-instant-v1",
model_kwargs = {
"temperature": 0.7,
"max_tokens_to_sample": 500
}
)
# AWS DynamoDBからsession_idをキーとし、会話履歴を取得
# --> ConversationBufferMemoryに格納
message_history = DynamoDBChatMessageHistory(table_name="bedrock_chat_memory", session_id=session_id)
memory = ConversationBufferMemory(return_messages=True, chat_memory=message_history)
# 会話プロンプトのレンプレートを作成
prompt = PromptTemplate.from_template(template)
# 会話のチェーンを作成
# ここでmemoryを渡すことで、会話履歴を加味した返答が生成される
chain = LLMChain(
llm = LLM,
prompt = prompt,
verbose = True,
memory = memory
)
# AIの返答を作成
response = chain.predict(input=message)
return response
@app.route('/')
def health_check():
"""
ヘルスチェック用
"""
return 'Success'
@app.route('/chat', methods=['POST'])
def post_message():
message = request.form.get('message')
session_id = request.form.get('sessionId')
response = chat(message, session_id)
return response
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)
アーキテクチャ
想定しているアーキテクチャは以下になります。
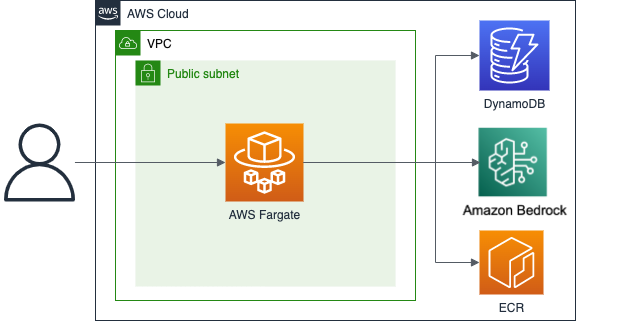
至ってシンプルな構成にしており、商用利用などを見越したものではないため、パブリックサブネットにAWS Fargateを配置します。また、コストを抑えるためにVPCエンドポイントは設置しません。また、省略のため事前にVPCは作成済みです。
ECRにイメージをデプロイ
まずは、作成したdockerイメージをECR(Elastic Container Registory)にデプロイしたいと思います。Amazon Elastic Container Registoryのコンソールのリポジトリ一覧画面の「リポジトリを作成」ボタンを押下し、リポジトリを作成します。
作成が完了すると、下画像のようにリポジトリ一覧画面に作成したリポジトリが現れます。
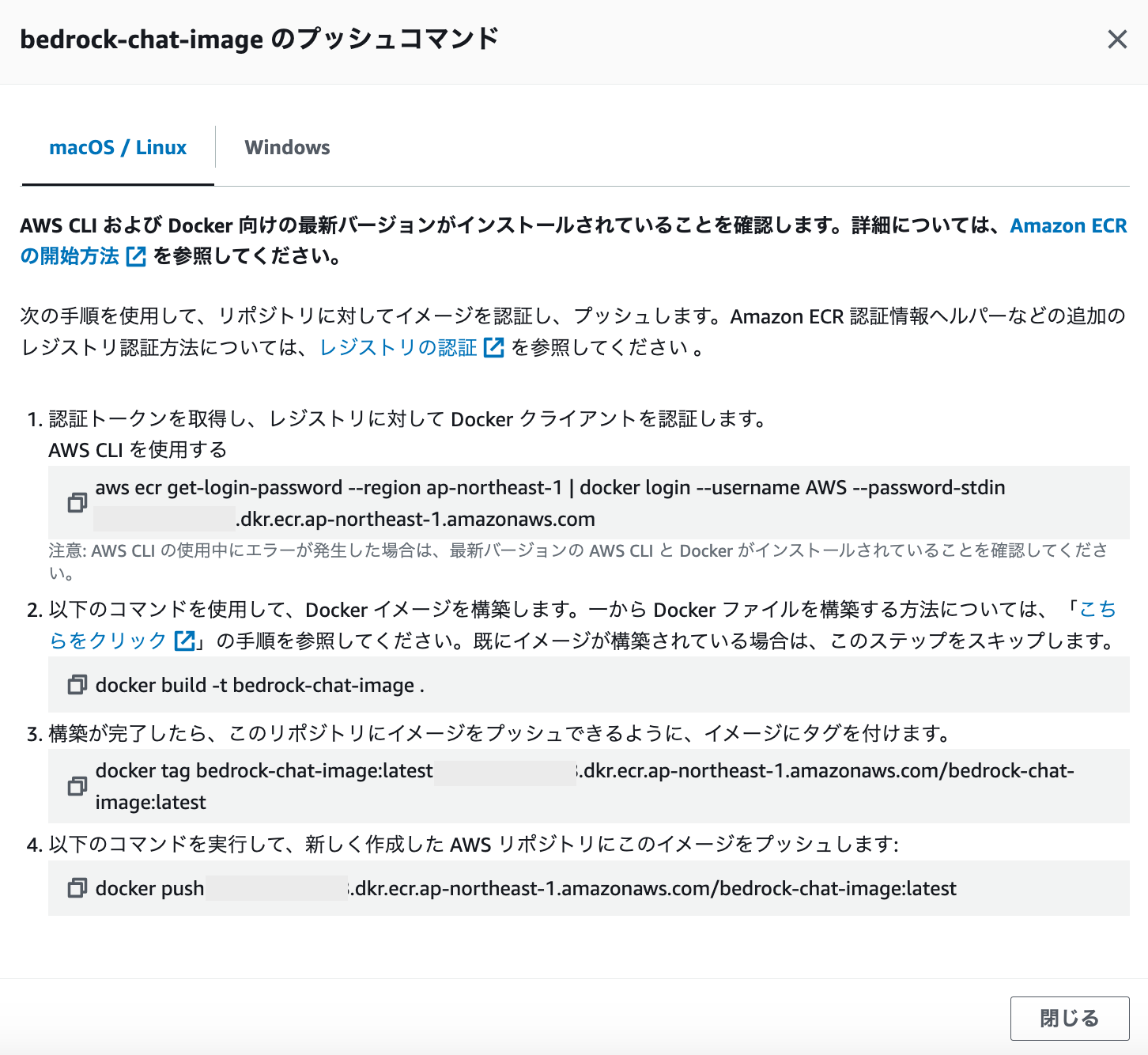
リポジトリ名にチェックをつけると、「プッシュコマンドの表示」が活性化するため押下します。すると、dockerイメージのプッシュに必要なコマンドが表示されるため、ローカル環境で実行していきます。
今回は以下のようなディレクトリ構成で作業をしているため、dockerフォルダ配下で上記コマンドを実行します。
docker
|- Dockerfile
|- app.py
|- .env
|- requirements.txt
一つ目のコマンドは、aws cli をローカルで実行することになるため、予め aws configure でご利用のアカウントの認証情報をセットしておいて下さい。成功すると、Login Succeededというメッセージが出ます。
2つ目のコマンドは前回実施済みのため、残りのコマンドをコピーしてそのまま実行します。最後のpushコマンドが完了すると、以下のように作成したリポジトリにDockerイメージがデプロイされます!
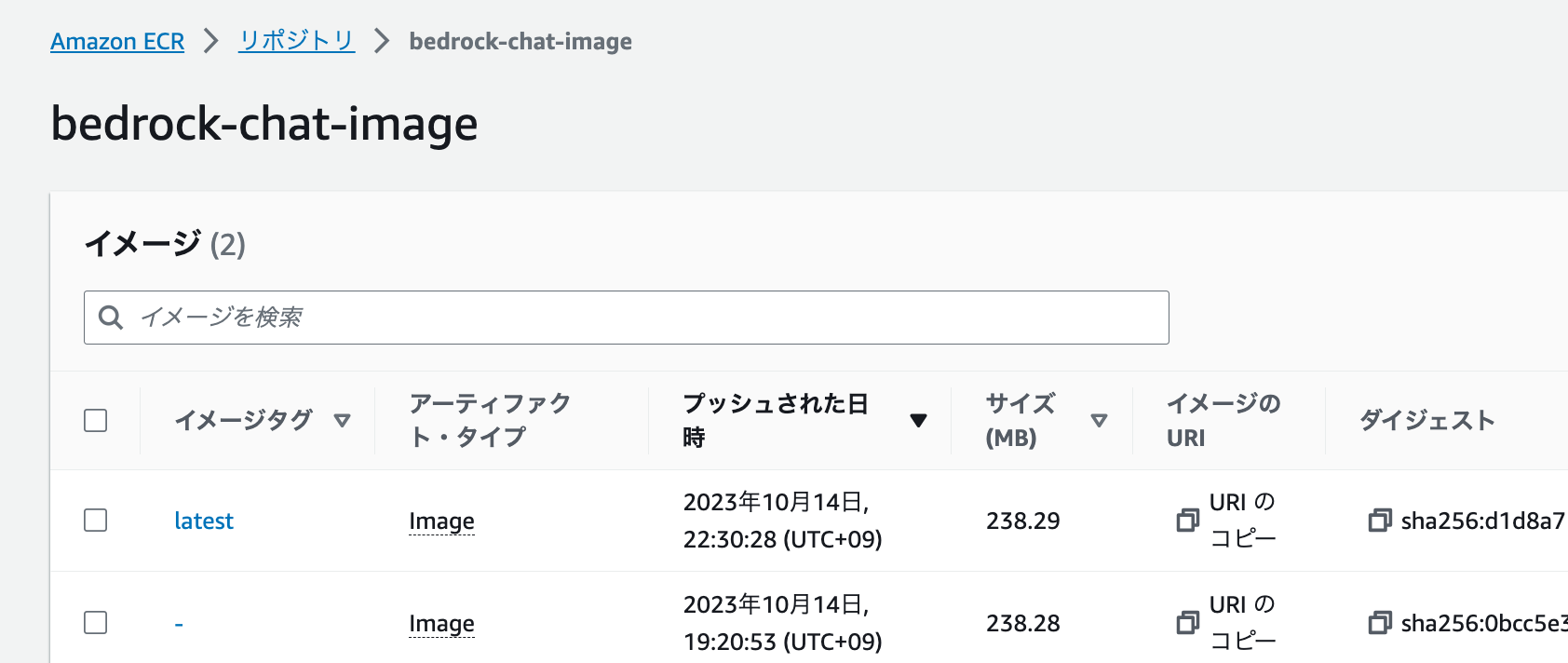
これで、ECRへのDockerイメージのデプロイは完了です。
ECS Fargateによるコンテナ起動
クラスターの作成
まずは、ECSクラスターを作成します。Amazon Elastic Container Service のコンソールに入り、左メニューの「クラスター」を選択します。クラスター一覧画面が表示されるので、「クラスターの作成」を押下します。
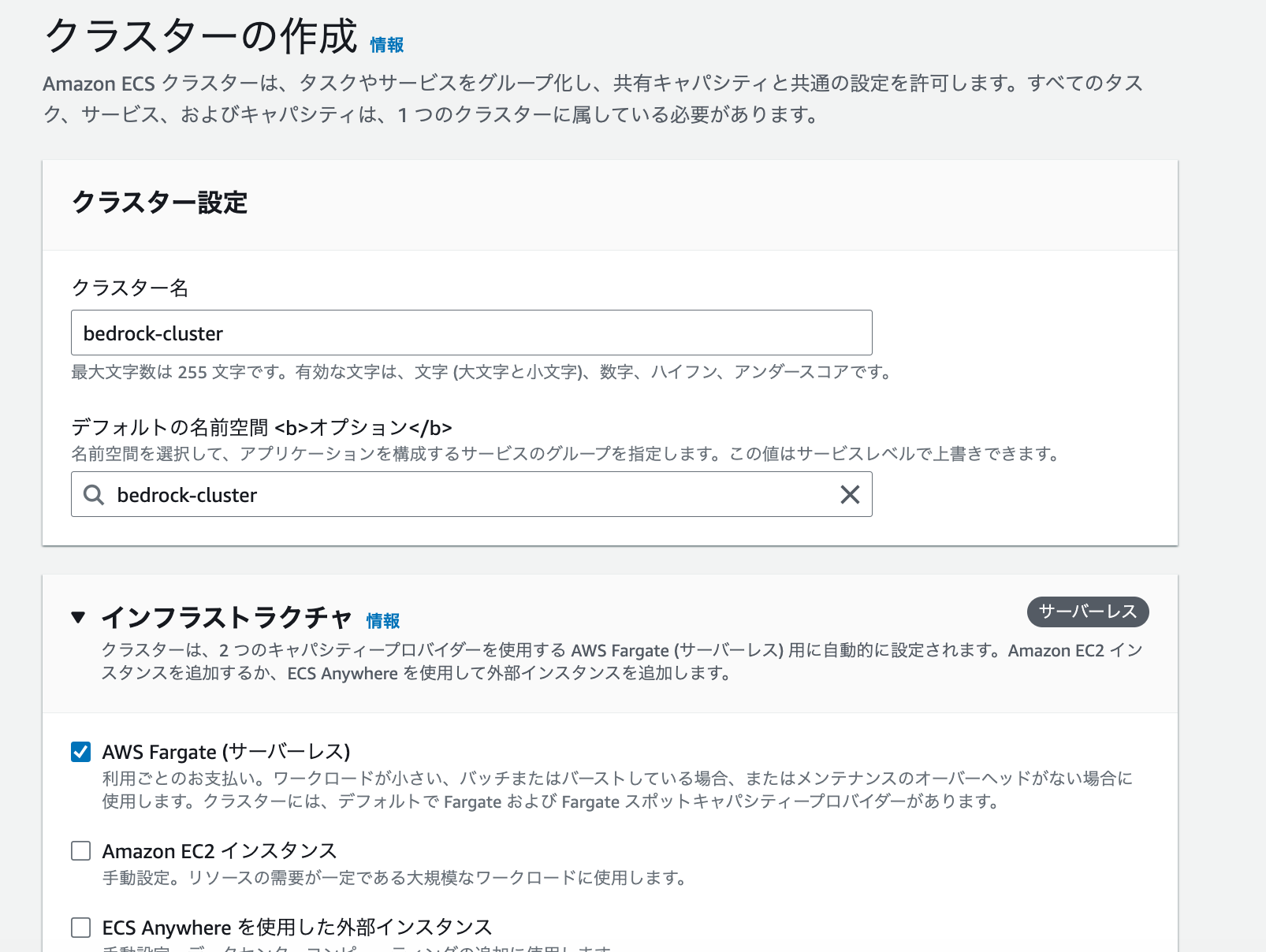
クラスター作成画面で必要な情報を入力し、クラスターを作成します。インフラストラクチャは AWS Fargate を選択します。
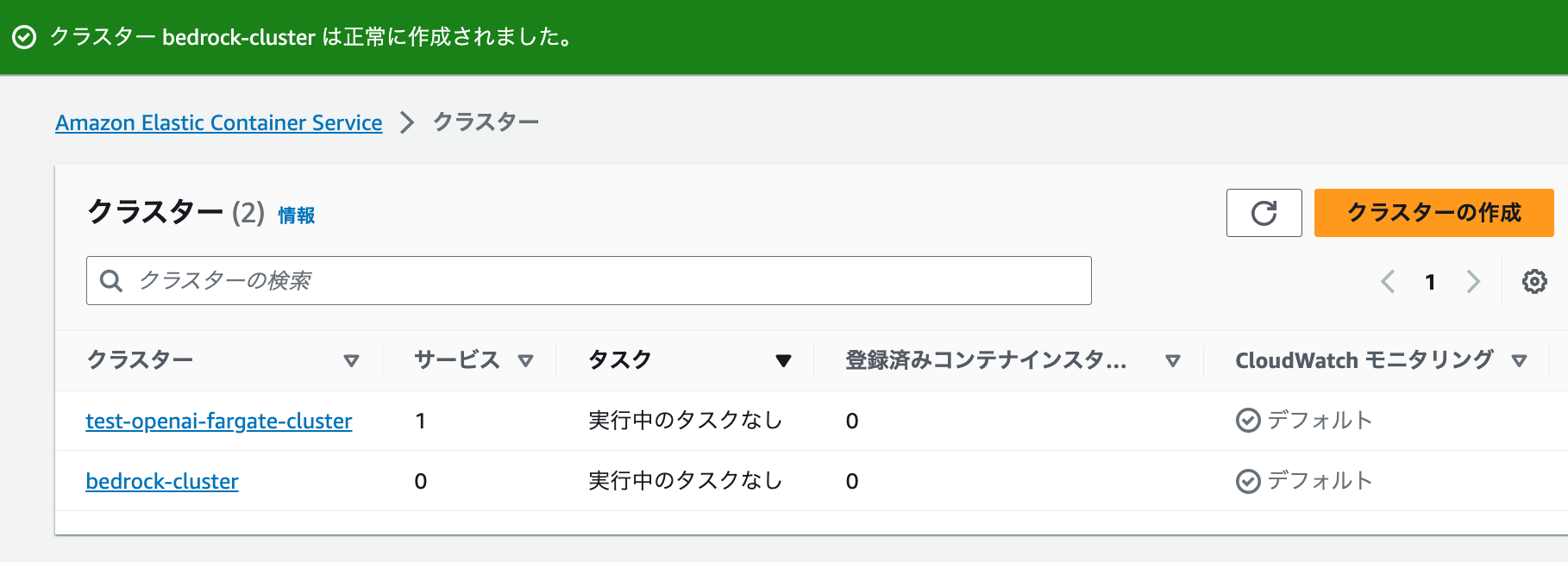
作成が完了すると、クラスター一覧画面に作成したクラスターが表示されます。
タスク定義の作成
次に、タスク定義の作成に移ります。左メニューの「タスク定義」を選択、タスク定義一覧画面が表示されるので、「新しいタスク定義の作成」を押下します。
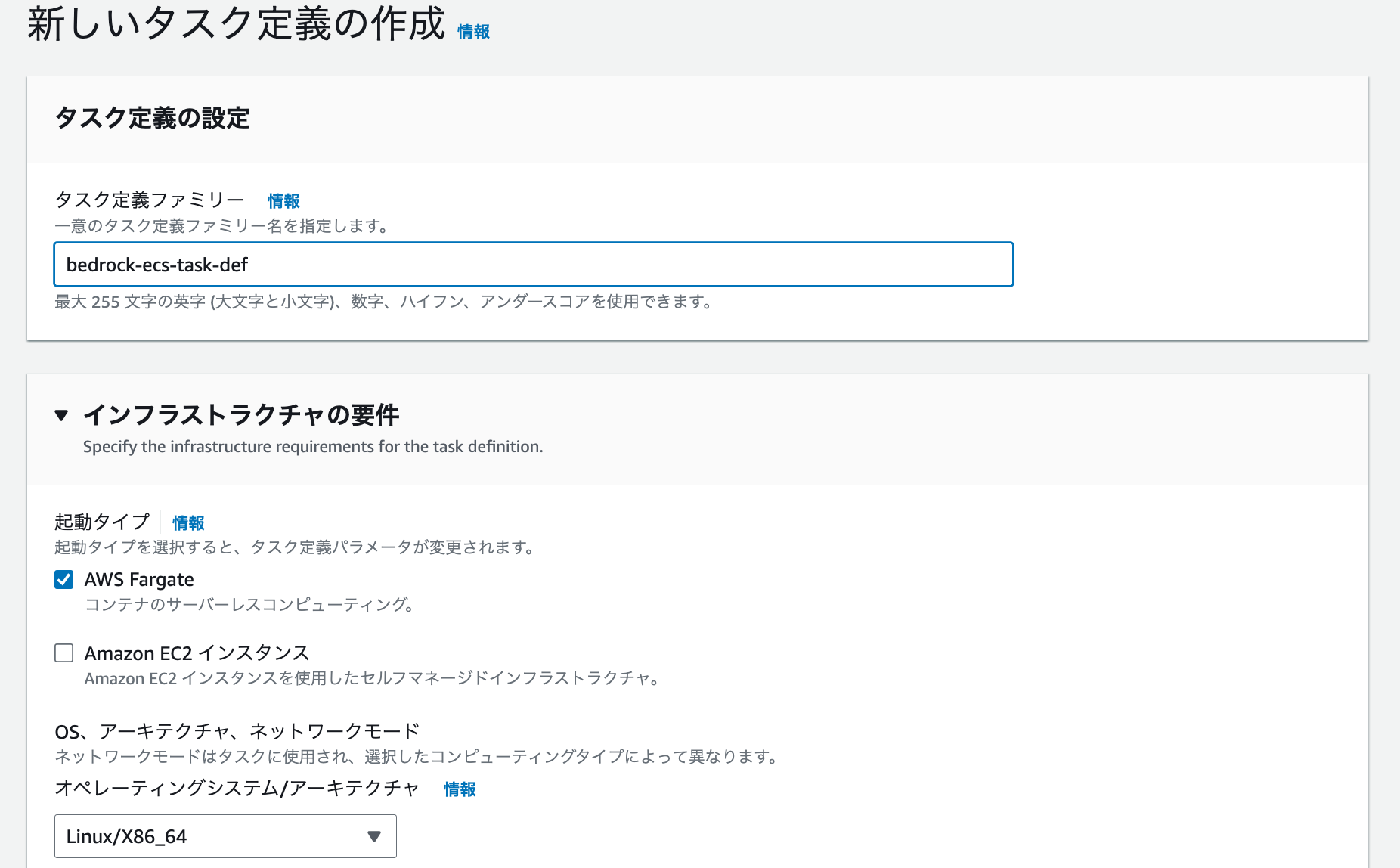
クラスターの作成と同様に必要な情報を入力していきます。起動タイプは AWS Fargate、オペレーティングシステム/アーキテクチャは Linux/X86_64 を選択しました。こちらは、Dockerイメージをビルドしたローカル環境に依存します。
次に、タスクを実行するために必要なIAMロールを選択することになります。今回必要になる権限は、DynamoDBの操作権限、Bedrockの利用権限になりますので、以下のようなロールを作成して下さい。
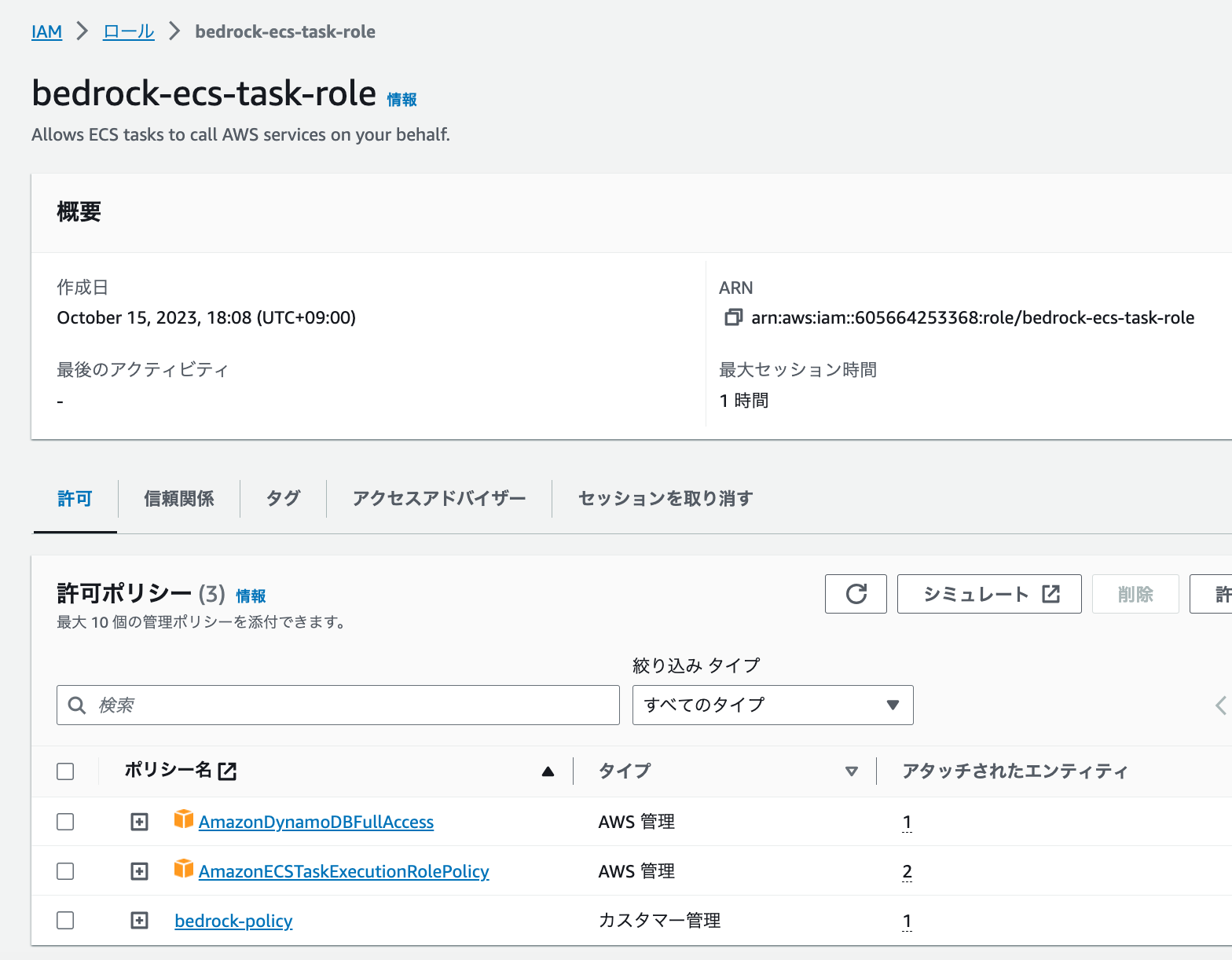
本来はDynamoDBの操作権限は絞る必要がありますが、今回は簡単のためにFullAccessにしています。また、Bedrockのマネージドポリシーは現在ないため、以下のようなポリシーを作成し、アタッチしています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:*::foundation-model/*"
}
]
}
IAMロールを作成し終えると、タスク定義の作成画面において選択出来るようになります。
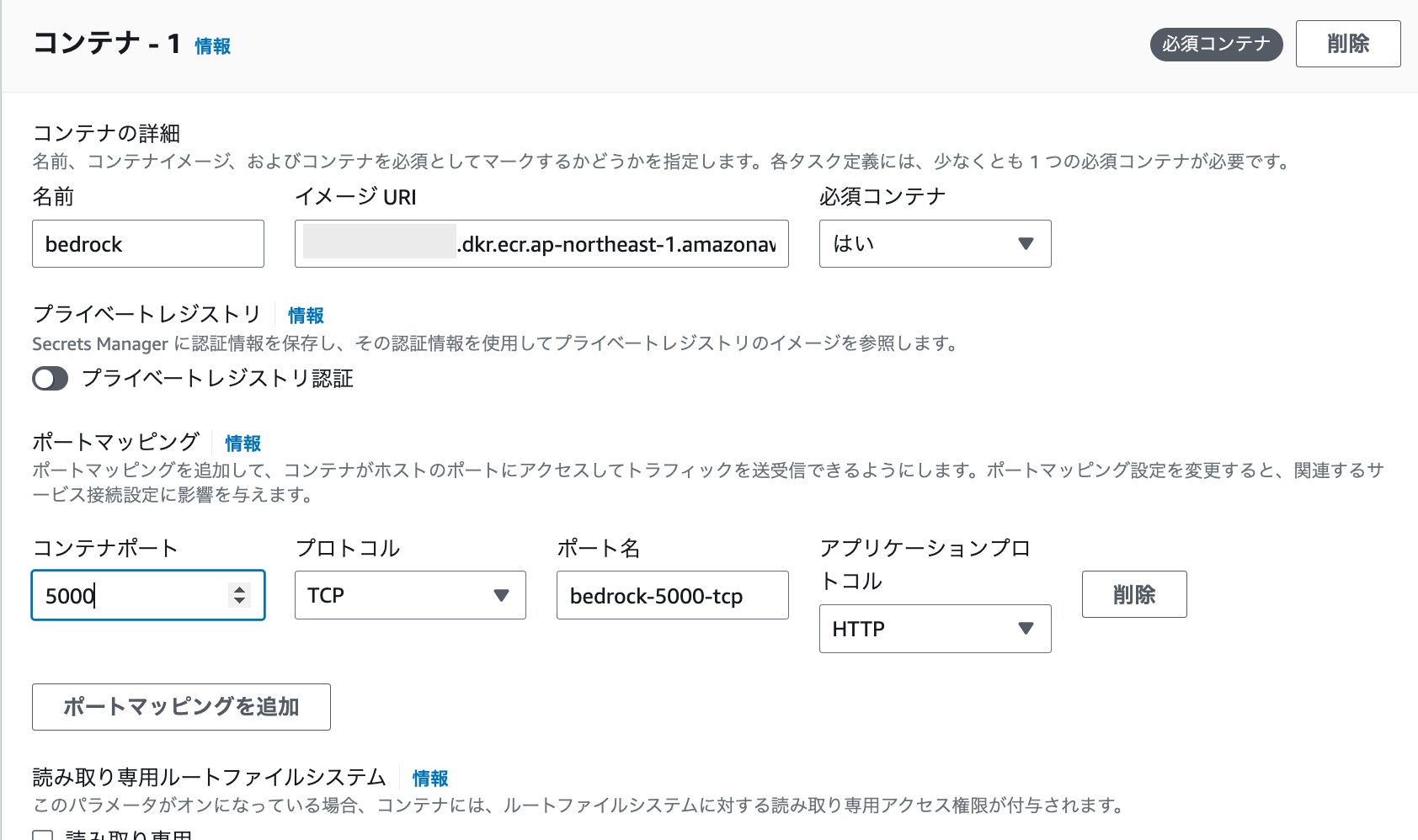
次はコンテナの定義です。イメージURLは先ほどデプロイしたdockerイメージのURLを指定します。ポートマッピングに関しては、コンテナポートを5000で設定して下さい。
残りは特に何も設定せず、タスクの定義を作成します。成功すると、タスク定義一覧に表示されます。
ECSサービスの作成
最後の工程のECSサービスを作成していきます。クラスター一覧から作成したクラスターを選択し、概要画面を開きます。画面下部に「サービス」タブがありますので、「作成」ボタンを押下して、作成画面を開きます。
コンピューティングオプションは「起動タイプ」、起動タイプはFARGATEを選択します。
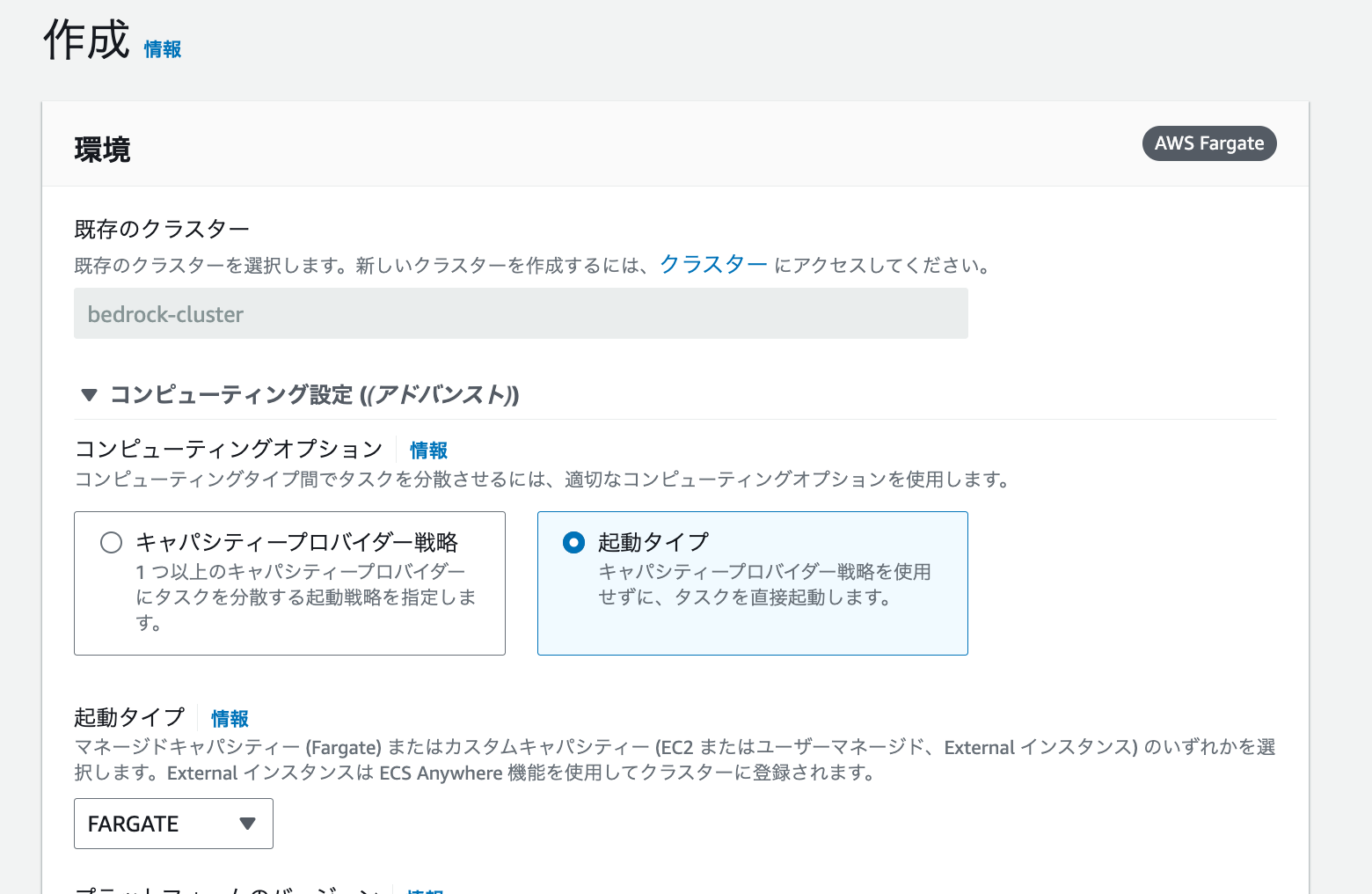
また、「必要なタスク」は 1 にします。こうすることで、サービス起動中にタスクが1つ起動します。

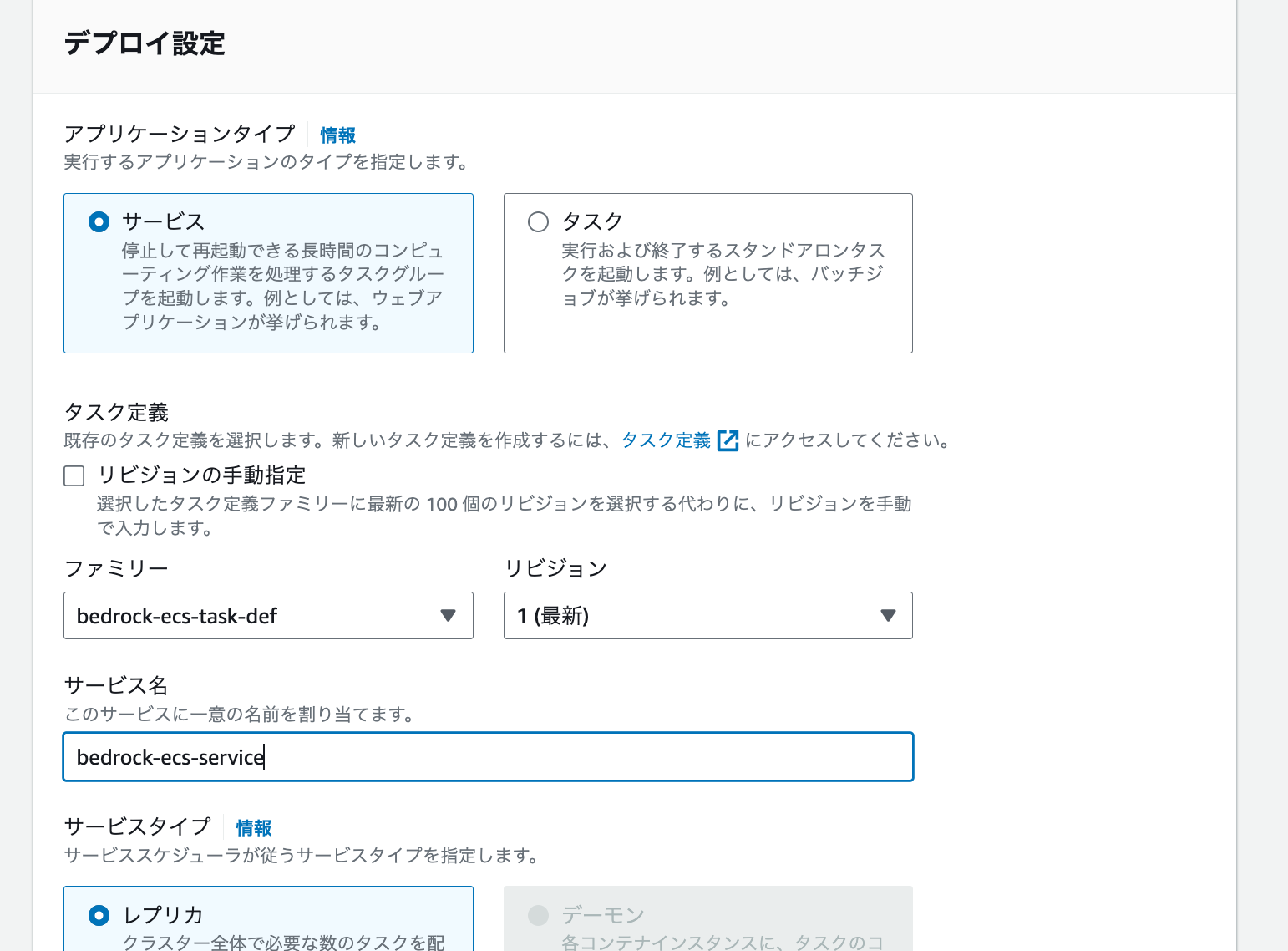
デプロイ設定ですが、今回はサーバーを起動するためアプリケーションタイプは「サービス」を選択します。タスク定義のファミリーは先ほど作成したもののリビジョンを指定します。
次にネットワーキングの設定です。サブネットはパブリックサブネットを選択しています。また、セキュリティグループを選択する必要がありますので、事前に作成しておいて下さい。
最後に注意していただきたいのが「パブリックIP」です。今回はVPCエンドポイントを設けないので、こちらをオンにしておく必要があります。
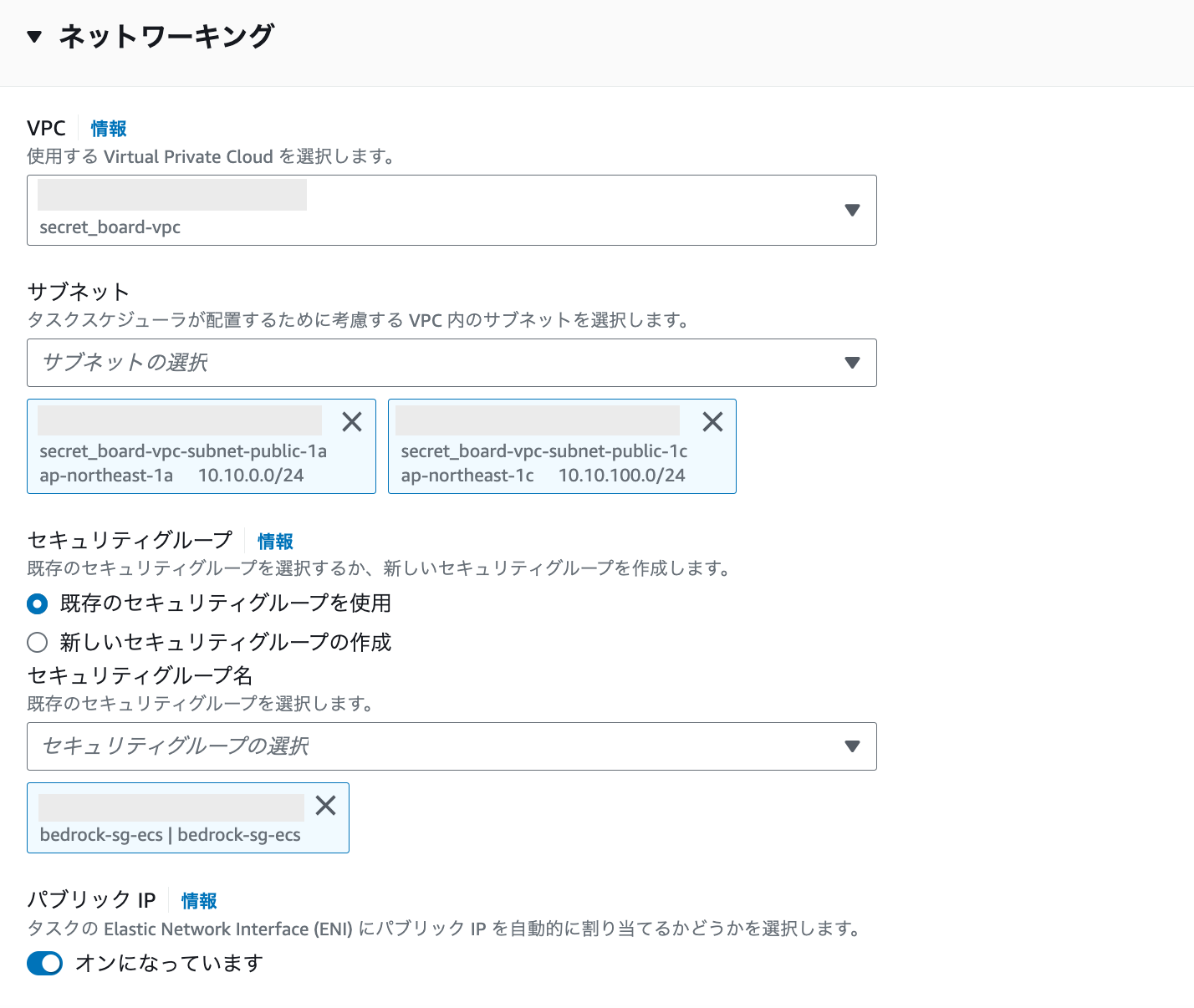
※ 参考までに、もしVPCエンドポイントを設ける場合は以下のサービスに対するものを作成して下さい。
- com.amazonaws.ap-northeast-1.s3
- com.amazonaws.ap-northeast-1.dynamodb
- com.amazonaws.ap-northeast-1.bedrock-runtime <= 重要!!
- com.amazonaws.ap-northeast-1.ecr.api
- com.amazonaws.ap-northeast-1.ecr.dkr
- com.amazonaws.ap-northeast-1.logs
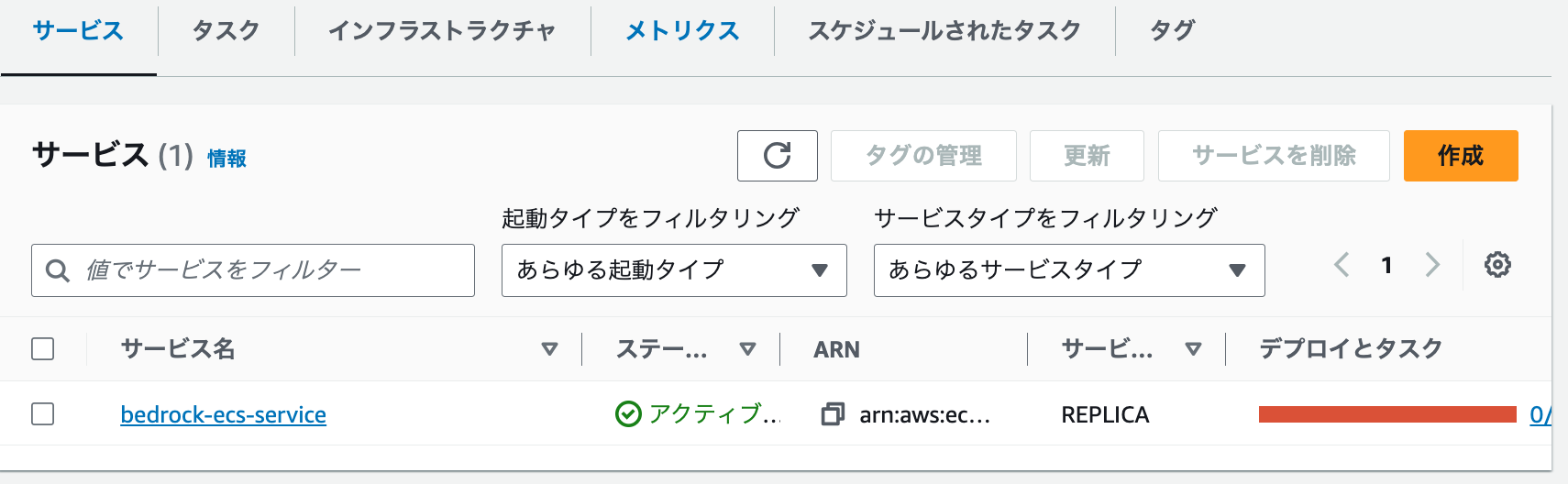
これで必要な設定が完了したため、サービスを作成します。クラスターの概要画面の「サービス」タブを見ると、起動中のサービスが表示されます。ステータスが「アクティブ」になると、起動完了です!
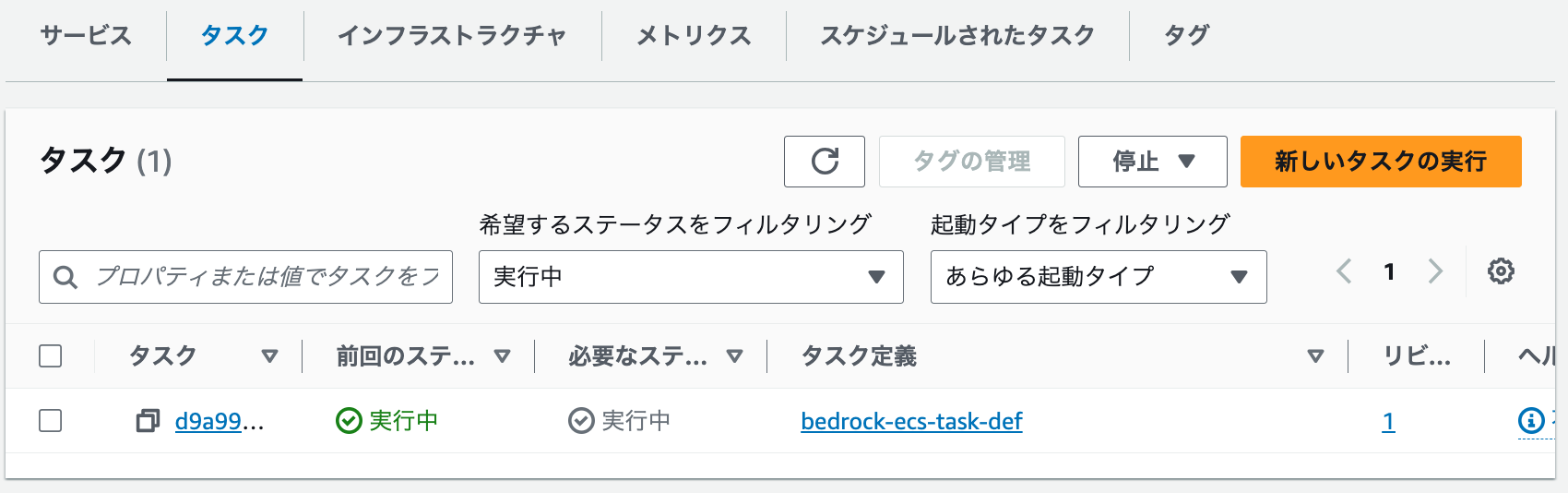
また、タスクが正常に動いているかどうかも確認します。「タスク」タブを開くと、実行中のタスクが表示されます。「必要なステータス」が「実行中」になっていれば、タスクが動作しています。
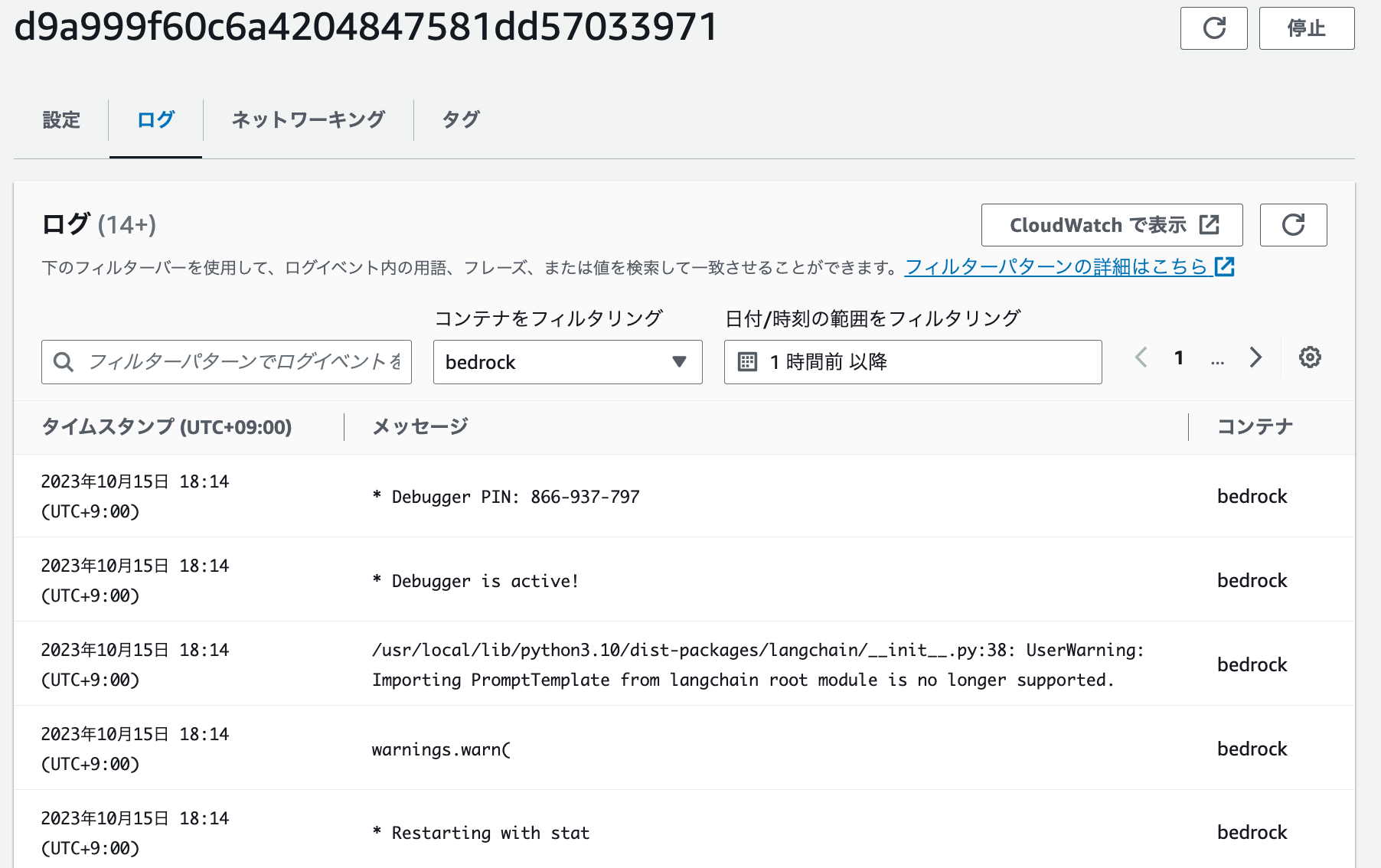
タスクを選択、詳細画面に移動し、「ログ」タブを見てみると、ローカル環境で実行した時と同じようなサーバーログが出ていれば成功です!!
動作確認!
いよいよ動作確認です!ローカル環境での実行時と同じく、curlコマンドでリクエストを行いますが、サーバーのIPアドレスはタスクの概要画面の以下の場所で確認できます。
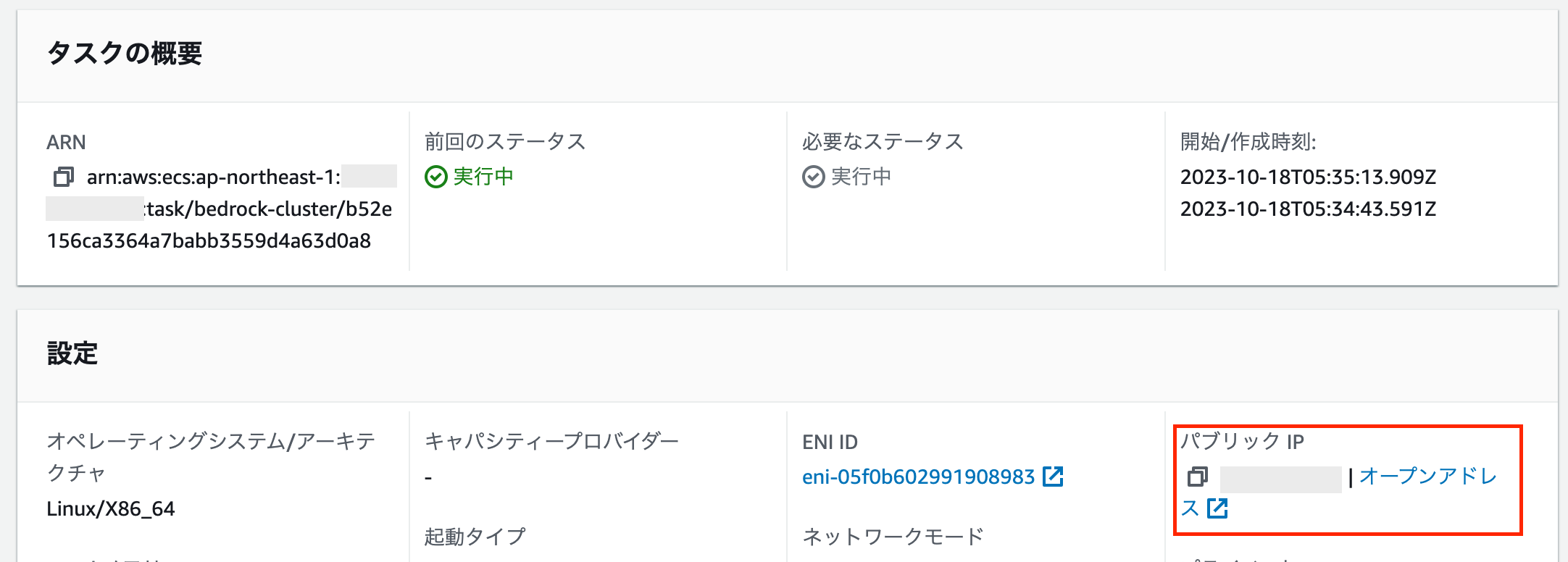
それではリクエストを投げてみます。一度自己紹介済みの会話セッションで実施します。
curl -X POST -d "message=私の名前を覚えていますか&sessionId=s00002" http://{サーバーのパブリックIP}:5000/chat
結果は以下のようになりました。相変わらず記憶が曖昧のようですが(前回記事参照)、自己紹介したことを覚えてくてれていそうです!
$ curl -X POST -d "message=昨日ぶりですが、私の名前を覚えていますか?&sessionId=s00002" http://{サーバーのパブリックIP}:5000/chat
はい、記憶が定まらないのだ!
でも、昨日会ったユウキ君ではないのだろうか。
名前は覚えているつもりだったのだが、ずんだ餅の布教活動に夢中になりすぎてしまったのだ!
これにて動作確認完了です!!
無事にAWS Fargate上でAmazon Bedrockを用いたチャットAPIを構築することが出来ました!!
さいごに
本記事では、前回記事で作成したDockerイメージをAWS Fargateに乗せて、AWS上でチャットAPIを構築してみました! 一通りの工程を通して、とにかくAWS内で完結することがかなり便利だと感じました。似たようなことをやろうとすると、今までは Azure OpenAI を利用する必要がありましたが、Azureを使ってこなかった場合はまずAzureを勉強することから始めないといけないので、敷居が高く感じていまいた。しかし、Azure OpenAIには「Add your data」などBedrockにはない便利な機能もあるため、AWS利用者であっても、しばらくはBedrockとAzure OpenAIの使い分けが必要になるのではと考えています。
今回の開発を通して得られた知見をもとに、もっとBedrock沼にハマっていきたいと思っています。とりあえず手始めにLINE Botを試してみたいと思っていますので、もしかしたらこちらも記事にするかも。
それでは今回はここら辺で以上とさせていただきたいと思います。最後までお付き合いいただきまして、ありがとうございました!!(前回記事から合わせて見ていただいた方はさらに感謝!!)