0. はじめに
中の人は新卒4年目、都内でデータベースを担当しています。普段の仕事ではPLSQLしか触ってません。入社前のIT経験は有りません。
そんな人の開発(やってみた)記録です。
1. 背景
もともとはOracleの勉強をするときに「ついでにOSから入れてみるか」と思い立ったのが始まり。 virtualboxで良かったんじゃないか
それから「あんなものも欲しい、こんな機能があったら良いんじゃないか」を繰り返した結果、それらしいものが出来てきたので、記録として残しておこうというものです。「やってみた」を繰り返したらどうなったか、という話です。
なおOracleDBの社外研修を除いて独学です。
システム開発練習が目的なため、一般サービスインは目標としておりません。
コードも貼ろうかと思いましたが、量的に無理です。
全体的な開発記録ですので、個別テクノロジや細かい実装内容について説明は行いません。特筆すべき目立ったテクニックも使っていないので。。。
AWS+OracleDB環境で作業しましたが、ベーシックなテクノロジが中心です。
1-1. 目標としたこと
普通なシステムをOS建てるところから画面まで自力で実装して、運用まで漕ぎ着ける練習です。業務では命令ベースでの部分的な仕事が中心なので、「一通りを自力でやる」経験が欲しかった。
当初はOracleDBのみの予定でしたが、結果として以下テクノロジを利用しました。
EC2(CentOS), Route53, NGINX, OracleDB12c(含むRMAN,StatsPack), OracleAPEX, PLSQL, python(urllibクライアント), logwatch, Git
データは東京メトロのオープンAPIを利用させてもらいました。
選んだ理由は、分次以下で継続取得できる無料データソースだったからです。
1-2. 対応できなかったこと
ある程度の本番稼働を意識していますが、予算や知識経験等々により実現出来ていない要素は色々あります。例えば以下は実装できていません。
- サーバ冗長構成
- データ暗号化
- アクセス集中対策
- 集中ジョブ管理(JP1とか、digdagとか)
- テスト自動化
- UX
- その他全般のモダンな話
2. 稼働環境
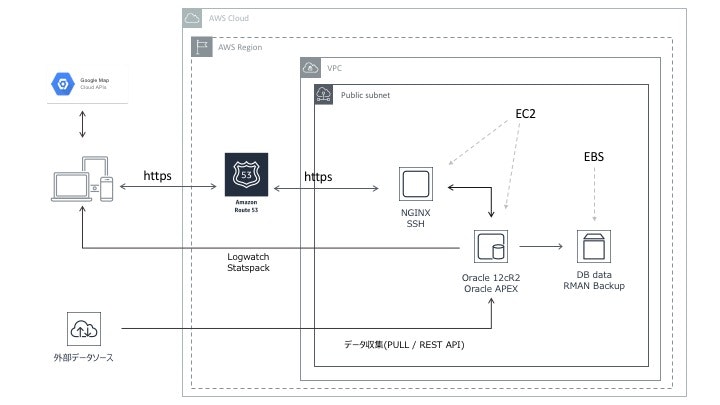
2-1. アーキテクチャ図
5年前くらいに見かけたような、オールドファッションな構成です。
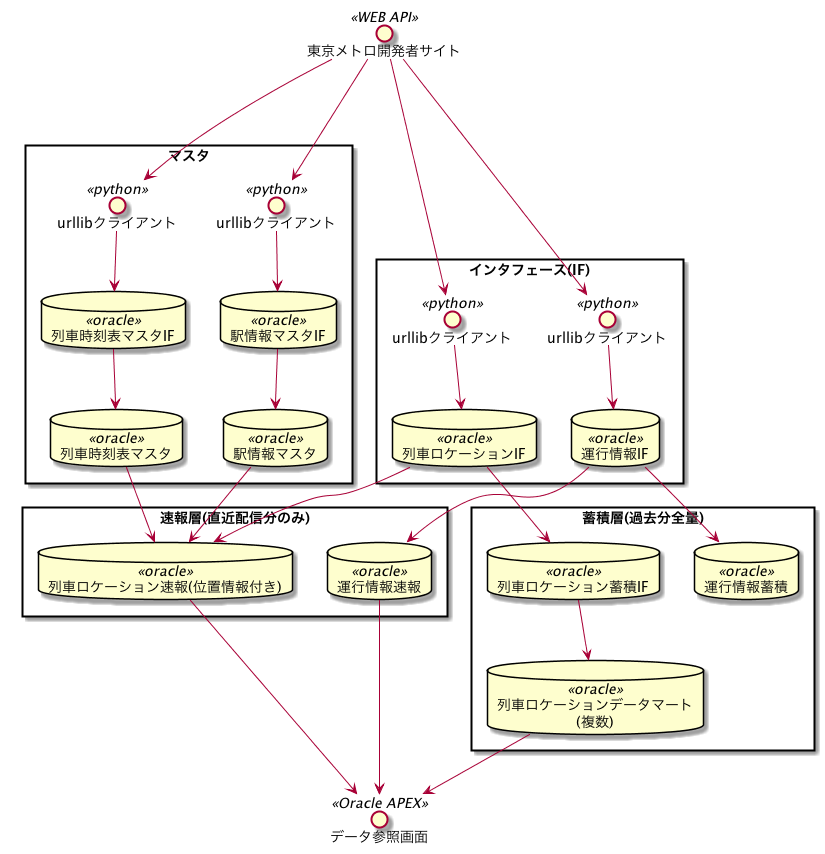
データフローは以下の感じです(相当に省略しています)
- テーブル数: 20(グローバル一時表、ビュー、管理用テーブル除く)
- プロシージャ数:19
- 画面数: 4
- ジョブフロー数: 10
- cronジョブ起動回数(一日あたり): 1457 (1回の起動で2回走る処理(30秒次処理)が有るので、実際は2700くらい)
- DBMS_SCHEDULER起動回数(一日あたり): 2 (CHAINで一気に回してます)
- 取り込みデータ量: だいたい40万レコード/日 (個々の取り込みは小粒なので、負荷としては大したことは有りません)
考えながら(=事前に設計を固めずに)製造を進めたので、今だったら作らないテーブルが幾つか有ります。
また、そもそもOracleは使わないと思います(理由は後述)
2-2. インフラ構成
2-2-1. サーバ構成
EC2を2台です。職場がRHEL系なのでCentOS。
踏み台のみElastic IPを充てています。
| 名前 | 主な用途 |
|---|---|
| 踏み台 | SSH踏み台、NGINXリバースプロキシ |
| DB(AP兼用) | Oracle12cR2、Oracle APEX、python(APIクライアント) |
2-2-2. ネットワーク
- クライアント-DB間の通信は(SSH除いて)NGINXを経由させています。DBサーバへのインバウンド通信は踏み台からを除いて、AWSのsecurity groupで禁止しています。
- NGINXへのアクセスは登録されたDNS(route53)経由のみ許可。HTTPS(SSL)通信のみ受け付けています(自己証明書ですが)。
2-2-3. システム監視
運用レポートを配信しています。
- OS: Logwatch。NGINXも対象。
- DB: StatsPack。
2-3. データ処理
PLSQLで日夜問わずデータを作り出しています。
2-3-1. In: 取り込んでいるデータについて
東京メトロのオープンAPIにて公開されているもののうち、以下を使いました。
| 種類 | 取扱区分 | 概要 | 取得間隔 |
|---|---|---|---|
| 列車運行情報 | トランザクションデータ | 遅延情報を取得するために利用 | 5分 |
| 列車ロケーション情報 | トランザクションデータ | 列車の位置情報が「oo駅とxx駅の間」の形で配信されます | 30秒 |
| 駅情報 | マスタデータ | 駅名から列車位置を緯度経度に変換するソースとして利用 | 月次 |
| 列車時刻表 | マスタデータ | ロケーション情報に駅の到着予定時刻を付与するソースとして利用 | 日次 |
2-3-2. 処理: 日中帯(5時から25時くらい)
以下の2処理を実装しています。
- リアルタイムの列車ロケーション情報取得
- 30秒おきに取得。
- IFレイヤでクレンジングを実施(正規表現でのデータ抽出が中心)。
- 速報レイヤ: 全量truncate+insertでマートまで作成。列車時刻表マスタおよび駅情報マスタと突合して、列車の だいたいの緯度経度および 概算遅延時間(公表遅延時間との比較用)を計算してます。
- 蓄積レイヤ: 蓄積用IFに貯めておく。夜間処理で蓄積用マートに反映。
- リアルタイムの運行情報取得
- 5分おきに取得。
- IFレイヤでクレンジングを実施(正規表現でのデータ抽出が中心)。
- 速報レイヤ: 全量truncate+insertでマートまで作成。特に加工は行っていません。
- 蓄積レイヤ: 蓄積用IFに貯めておく。夜間処理で蓄積用マートに反映。
2-3-3. 処理: 夜間帯(25時から5時くらい)
データマート作成と管理系の処理が走っています。
マート作成は技術よりも「何を作るか」を思いつくのに苦労しました。
-
データマート作成
- マート1: 路線ごとに「最大遅延時間、最小遅延時間、平均遅延時間、遅延時間の中央値」を過去1ヶ月分のロケーション情報に対して作成。
- マート2: 列車番号および位置ごとに、最大遅延時間、平均遅延時間、遅延レコード数、遅延レコード割合を保持。対象データは過去のロケーション情報全量。
-
管理系
- 列車時刻表マスタ更新。元データの更新日時が不確定なので、日次で一旦全量取得してDBで差分更新を行っています。
- 駅情報マスタ更新。元データの更新日時が不確定なので、月次で一旦全量取得してDBで差分更新を行っています。
- 安心と信頼のRMANでバックアップを毎日取得。ARCHIVELOGモード。
- ログテーブル(1日用)をログテーブル(過去全量)に転記してます。圧縮して容量を減らすのが目的。
2-3-4. Out:APPと画面
Oracle DBに付属しているAPEXを使ってます。DBのテーブルを手軽に画面化したい場合に向いていると思います。それ以外は意見が割れそうです。
とりあえず画面は以下を用意しました。 他は思いつかなかった
- 遅延速報
- 現在の列車位置照会
- 直近30日の遅延情報集計
- 処理ログ確認
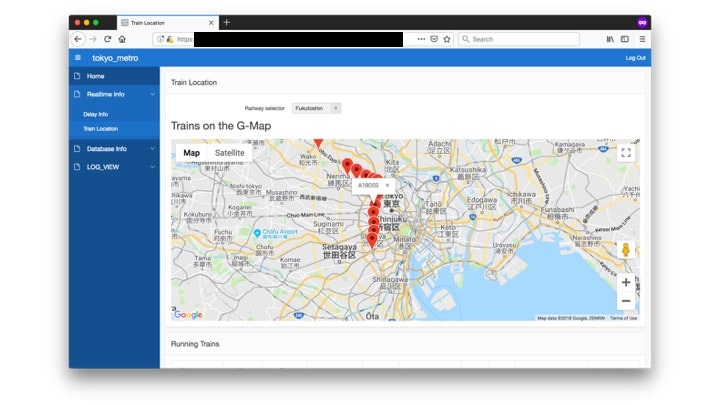
位置情報照会画面のみスクショ残します。データ処理で作り出した位置情報をGoogle Mapに映してます。
下部に見切れてますが、選択している路線の運行中列車情報が出力されています。map上に列車番号が出るようになっているので、それを元に該当する列車情報を閲覧する流れ。
(作り込むことも考えましたが、時間が掛かりそうなので見送りました)
2-3-5. ジョブ管理
cronとOracleDBのDBMS_SCHEDULERを併用しています。
| 名前 | 主な用途 |
|---|---|
| cron | 日中帯と、夜間の管理系(バックアップ、ログ解放) |
| DBMS_SCHEDULER | 夜間のデータ作成処理 |
普段ならcronに寄せますが、今回は使ったことがないDBMS_SCHEDULERも使うことにしました。
2-4. その他(プロジェクト管理系とか)
- Git(bitbucket): Gitは良いものだ。
- Jiraとconfluenceに少し手を出しました。便利ですが表示が重くて辛く、本格利用には踏み切れていません。
2-5. 製品不具合(?)を踏み抜いた話
「列車の位置情報を割り出したデータマートを作成し、Google Mapにマッピングする」機能は最優先だったのですが、作ったものの以下の事象に該当している疑惑があり、GoogleMap JavaScript APIに渡すjsonの作成に失敗することが頻繁に。。。
ORA-40478 or ORA-40459 running JSON Generation Functions (Doc ID 2354511.1)
Generating large json in 12.2 using json_object and json_arrayagg
とりあえずデータ型拡張で乗り切りましたが、やっぱりDBとAPは分離すべきでしょうか??
3. 作ってみての感想
技術的に詰まる場面は有りませんでした。むしろソースデータから「使い方を考え出す」ことが大変だった。データ活用って難しいですね。
- 間違いなく勉強になりました
-
インフラセキュリティから画面(ユーザビリティの考慮)まで意識に入るようになったことが一番大きかったと思います。普段の業務では触らないレイヤのテクノロジに触ることも大事。
本業よりも勉強になった気がします
-
インフラセキュリティから画面(ユーザビリティの考慮)まで意識に入るようになったことが一番大きかったと思います。普段の業務では触らないレイヤのテクノロジに触ることも大事。
- オールドファッション具合にモチベーションが下がる
- qiitaで盛り上がる記事を見たり勉強会でweb系な方々と話すと、やはり自分が「古い+スピード感に欠ける」ことを実感します。普段の業務では「RHEL系+Oracle」しか機会がありませんが、ここは自分で模索するしか有りません。
- 好き勝手な「こだわり」の機会
- 業務で「キレイな実装」や「最新の技術」をやらせてもらえる現場って、どれくらい有るのでしょうか。業務を通して技術力向上、が理想なんでしょうけれども、それが出来ない場合に個人開発は貴重です。(とはいえ、使い手が居ないシステムを作るのも中々の苦行でした)
- 今後のキャリアについて考えるきっかけになった
- 同じことを繰り返すよりも、自分は新しいテクノロジに手を出している方が楽しめそうです。
- 改めて作り直すとしたら(扱うデータは同じ想定で)
- 取り込みとデータ加工: Lambda + S3にします。現状の処理内容でロック管理が問題になりそうな場面は無く、またロスしても甚大な影響にはならないのでRDBを使う理由が無いように思います。単発の処理は小さいので、処理時間的にも問題無いと予想。
- 参照用マート: マート作成はLambdaだと厳しい(数十GBデータ)と思われますが、例えばAmazon EMR + S3(json or parquet)で解決できると思います(他にも色々と手段は有るはず)。マート参照もSELECT文を投げるだけならAmazon Athena等で十分ですよね。AP開発も色々オプション有ると思います。
- 画面: 上記の結果ですが、OSやDBのレイヤに気を取られてUIやUXにリソース集中出来なかったことが課題でした。技術的にも開発工数が増えるかもしれませんが、APとDBは今後は分離すると思います。RDBの出番は一意性と一貫性を保証したいマスタデータ管理くらいですかね。
- ストレージ: 常にストレージ代(EBS)が頭痛でした。これに対処できるだけでも脱RDB+サーバレスは魅力的に感じます。
virtualboxで良かったんじゃないか(3度目)
4. 今後の話
- 全部では無いですが、一定の試したかったことは出来たので追加開発は中断します。しばらくは稼働させますが、今年末あたりで停止させる予定。
- 続きとしては、過去データ全量保持しているテーブルに位置情報を突き合わせて遅延傾向の変動を出そうと思っていました。が、取れるデータのクオリティ観点から微妙なので止めます。
- 次に作りたいものが既に在って、そちらに関心が移ってますというのが実際のところ。