概要
『もっとより良いニュースアプリはできないだろうか』
そう考えてMenthasというニュースアプリを開発し、プログラマ向けニュースキュレーションサービスを作ってみた話 という記事をQiitaに書き、自分の予想を超えた反響を受けてから約3年になります。
しばらく開発の更新は留まってしまいましたが、ニュース推薦に関しての探求が終わったわけではなく、むしろ見えてきた課題のために数多くの論文を読んだりプロトタイピングを繰り返していました。
そしてつい先日、これまで解けなかった問題に対してようやく答えを自分なりに導き出すことができたため、骨格となるアルゴリズムの刷新に始まり、ついで開発もインフラからサーバサイド、フロントエンド・デザインと、全面的なリニューアルを行うことに成功しました。

新しいMenthasは以下のリンクから使用することができます。
https://menthas.com
今回はこのリニューアルに至るまでの背景と課題、その解決手法について書いてみようと思います。少々長くなりますがお付き合いいただければ幸いです。
背景
プログラマ向けニュースサービスの必要性
昨今のような情報過多の時代において、効率の良い情報収集手法を求めることに異論があるというひとはあまりいないでしょう。プログラマの情報源は、はてなブックマークやTwitterまたはRSSリーダーが未だに主流だと思います。変化といえばSlackのチャンネルがあげられるでしょうか。とはいえ以前述べたように、はてなブックマークではブックマークが稼げる一般向けのコンテンツの方が有利ですし、Twitterの場合はノイズの割合が多く、またフォローやリストの管理が面倒という問題があります。
このような現状を踏まえると、3年経った現在でもニュースサービスの必要性は未だに存在しているように思います。
Menthasの課題
ナイーブ過ぎるキュレーター選出アルゴリズム
Menthasは優秀なキュレーターを選出してWeb上からニュースを収集しカテゴリごとに選別して配信するという仕組みになっています。このキュレーターを選出するためのアイデアとして「わし育係数」という独自の仕組みを用いたことが特徴でしたが、この係数の算出方法がナイーブなためいくつかの問題が発生していました。
一番の課題として、以下の指摘からも推察できるように、単一のエントリのブックマーク順しか考慮していないためキュレーター同士の関係性を選出時に加味できていないことがあります。
TokyoIncidents: 「わしが育てた係数」にうっかり入ってしまいましたが、これはかいちょーやジャックさんや azu さんの tweet 見てブクマしてる率が高いからかと… 2015/12/10
例えばあるエントリのブクマがA-B-C-Dという順に登録されていて、別のエントリのブクマがE-A-Bという順番だった場合、わし育係数的にはA氏のScoreが最も高くなります。しかし二番目のエントリでE氏はA氏よりも早くその記事をブクマしていることを考えると、E氏もキュレーターとして優秀そうです。このようなキュレーター同士の関係性を計算に入れる必要がありました。
またこちらの指摘にもある通りScoreの算出のベースがブックマーク数なため、ブックマークが伸びやすいコンテンツをいち早くブクマするひとが基本有利になってしまうことも問題といえるでしょう。
YaSuYuKi: このアルゴリズムだと、ブックマークが伸びづらいが質が高い(技術的に高度すぎるなど)ものを取りこぼしやすそうだな 2015/12/10
結局Topしか見られていない
フィルタバブルや情報のタコツボ化といった言葉もすっかり定着して来た感があります。研究界隈でも推薦システムや情報検索において多様性が重要であるというのはよく知られており12、Googleも2013年5月に検索結果に対して同じサイトのページを表示しにくくすることで検索結果の多様性を担保する検索アルゴリズムの変更を行っています3。
このような背景もあり、MenthasではJavaScriptをメインとしたクライアントサイドの情報やサーバサイド、インフラや機械学習といった多様なカテゴリを用意することで普段目にしないようなカテゴリの情報に触れやすくしたつもりでした。
しかし以下のようなアクセス履歴が示すように、ユーザのほとんどはTopページを閲覧するだけで各カテゴリには遷移しないという結果になってしまいました。
 図1: 2015/12/01~2018/09/01までの約37万件のユーザアクセス履歴の内訳
図1: 2015/12/01~2018/09/01までの約37万件のユーザアクセス履歴の内訳
これにはサイトデザインの問題などいくつかの理由があると思いますが、そもそもニュースサイトのユーザ動向を考えると、Topページを軽くチェックして終わるというのはよくある一般的な行動のように思われます。よくよく自分の行動を思い起こしてみるとYahoo!やはてなブックマークなどでは確かにそのような動きをしていました。
上記のようなユーザ傾向を踏まえると、ニュースサイトではTopを軽くみるだけで全体のトレンドや傾向を把握できような仕組みが求められることがわかります。
要はユーザは多様な結果を求めているが自分から深堀することは稀なため、いかに利便性を失うことなく多様性を追求できる仕組みを提供できるかが鍵になる、ということです
以上のような結果を受けて、新しいMenthasは以下の2点を解決することを目標としました。
- キュレーターの選出アルゴリズムをもっと洗練させる
- Topを確認するだけでも様々なカテゴリの有用情報に触れられる
提案手法
PageRankとわし育の係数のアイデアを組み合わせる
PageRankは、Webページ間のリンク構造を利用し各ページの人気度(重要度)をグラフを使って推定する手法であり、ここで紹介するにも憚れるくらい有名かつその背後にある数理についても数多くの文献があります。
新MenthasではPageRankの考え方とわし育係数の根底にあったアイデアを統合することを目指します。わし育係数のアイデアは、いち早くブックマークしたキュレータがエライということですから、それをグラフで表現することを考えてみます。
※今回はキュレーターを見つけるためにPageRankのグラフベースのアプローチを採用しましたが、これを洗練させていく際に今森・田島さんのこちらの論文を参考にさせていただきました。Twitterのフォロー関係から情報源として優秀なアーリーアダプターを見つけるというもので、triadという三項間のフォロー関係をグラフベースのアルゴリズムに落とし込んでいるのが特徴です4。
ある文書がA-B-Cという3人のユーザに連続してブクマされていたとき、BはAに、CはAとBに単方向のリンクを張るというように、自分よりも前にブックマークしたユーザに対してリンクを張ると考えます。
例えば背景の章で述べた例をグラフで表すと以下の図のようになります。(左上の数値はブックマーク順を示す)
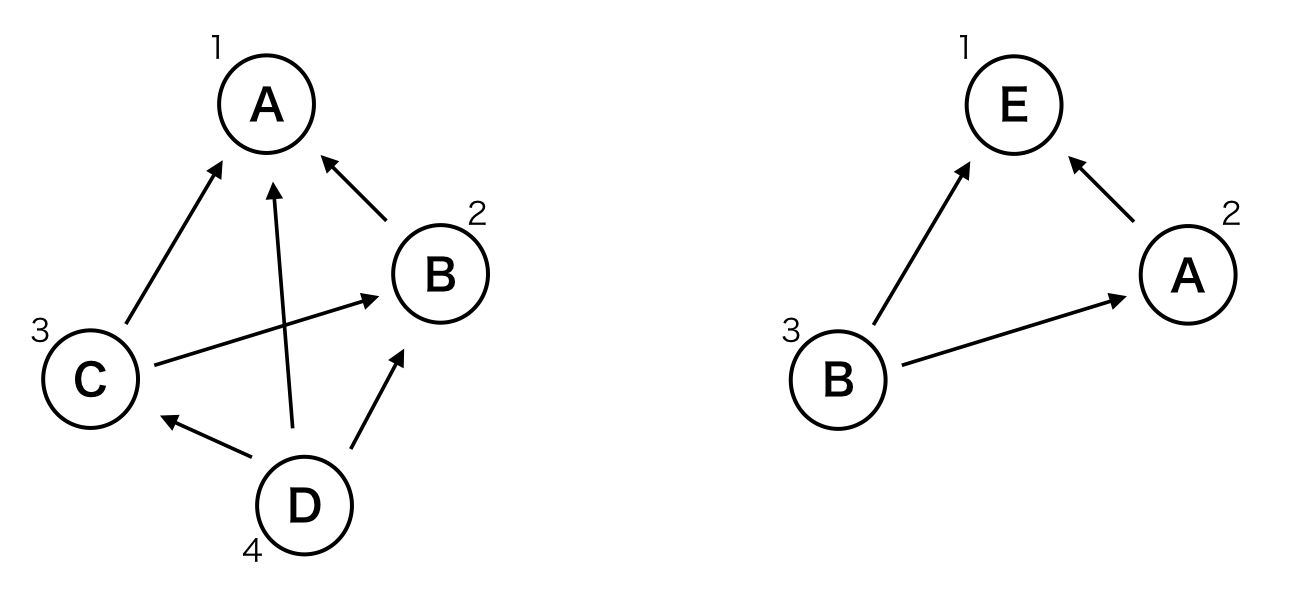
上記のグラフのPageRankを計算するとEが最もScoreが高いことになり、これは求めていた結果です。
このアプローチをMenthasで収集したニュースデータに適用してみたところ、ブックマーク情報を全てを使うのでなく、上位10件くらいだけでPageRankを算出した方が精度が良いという結果が出ました。
この理由はいくつかありそうですが、ブックマークユーザの中でもイノベーターやアーリーアダプターと呼ばれる層に対象を限定してグラフを構成し、PageRankを算出したからうまくいったのではないかと思っています。
というのもグラフベースのアプローチの場合、背後にあるリンクやネットワークの構造が結果に大きく影響を及ぼします。例えばZhangらの研究ではJavaのQAフォーラムからエキスパートを抽出するというタスクにおいて、コミュニティのネットワーク構造によって有効なアルゴリズムは異なるという報告がなされています5。
もしかするとイノベーターやアーリーアダプター層向きのコンテンツをキュレートするタイプと、マジョリティ層向きのコンテンツをキュレートするタイプの二種類のユーザが存在しているのかもしれません。
以上を踏まえて「ブックマークの中でも上位N件だけを対象にグラフを構成しPageRankを計算する手法」をα-CuratorRank(アルファキュレーターランク)と名付けてみました。
α-CuratorRankを算出してみる
Menthasで過去に収集した記事10万件(期間は2018/01/29~06/10)を対象として、まずブックマーク情報を取得しておき、次に各カテゴリごとに特徴となるタグを定義します(タグは前回同様タグクラスタリングの方法と人力による追加によって構成しています)。
そしてタグが一つでも含まれるエントリを抽出し上位10位までのユーザでグラフを構成、その後PageRankを算出し、Scoreが上位のユーザをキュレーターとします。
JavaScriptのCuratorランキング上位10人
efcl
mizchi
Hiro_Matsuno
teppeis
tuki0918
kkeisuke
grfxdsgn
yosuke_furukawa
makotot-riceball
mkt
以上のような結果になりました。なかなかうまくいっているように思います(完全に主観ですが)。他カテゴリでも同様のアプローチでキュレーターを選出します。
ニュース配信のアルゴリズム
次にTopや各カテゴリでのニュースの配信方法について説明します。
旧Menthasでは基本的にキュレーターの直近ブックマーク順でsortしていたので、同一のカテゴリや情報ソースの記事でTopが埋め尽くされることがありました。基本皆Topをみるのに、そこが単一のカテゴリで占められたり、単一のキュレーターによって占められることはよくありません。
しかし一方で基本ニュースサイトなので新しいものが上位になって欲しいという要求もあるため、多様性と新規度を両立する必要があります。
新MenthasではTopページに表示する記事の候補に対し、MMRとHackerNewsで使われている経過時間による減衰アルゴリズムを組み合わせてスコアリングを行いながら配信するニュースを決定します。
MMRを活用する
MMR(Maximal Marginal. Relevance)は、文書同士の冗長性を考慮しながら検索結果を再順序付けするための古典的な手法の一つです6。主に文書の自動要約に使われる手法ですが、検索や推薦システムに使われる場合もあります2。
数式で表すと以下のようになります。要は選ばれていない文書の中から関連度が高く、同時に既に選ばれた文書とできるだけ似ていない文書を選び出す仕組みです。

こちらのページが例も合わせてとてもわかりやすいです。
https://hazm.at/mox/machine-learning/natural-language-processing/summarization/index.html
新Menthasでは$Sim_1$の部分は後述するHackerNewsのScoreを、$Sim_2$の部分はニュース同士の類似度をJaccard係数を使って算出しています。文書の素性としてはカテゴリ名、ホスト名、その文書をブックマークしたキュレータ名を利用しました。
HackerNewsのアルゴリズム
HackerNewsは以下の記事にある通り、時間が経つにつれてScoreが減衰していく仕組みになっています。使われているアルゴリズムは次の通りです。こちらもシンプルで良いですね。
Score = (P-1) / (T+2)^G
where,
P = points of an item (and -1 is to negate submitters vote)
T = time since submission (in hours)
G = Gravity, defaults to 1.8 in news.arc

引用: https://medium.com/hacking-and-gonzo/how-hacker-news-ranking-algorithm-works-1d9b0cf2c08d
Pは対象カテゴリのキュレーターの総票数(カテゴリのタグが含まれる場合はさらに+2)、GはPの値の伸びがとても小さいので0.5を採用しています。
実際にニュースを配信するまでの流れ
- α-CuratorRankを用いて各カテゴリごとにキュレーターを選出する(人数は10~15人程度)
- キュレーターのRSSからニュースを収集してIndexingしておく
- (ユーザからのリクエストに応じて) HackerNewsのアルゴリズムで直近N件(N=50)のニュースのScoreを出す(ニュースの新規度を考慮)
- 3.のリストに対してMMRを適用しながら配信するニュースリストを作成する(リストの多様性を確保)
という動作になります。
システムと実装
システム概要図
新Menthasのシステムの概要を図にすると以下のような形になります。主にインフラ面での刷新が大きく、AWSとHeroku,mLabを組み合わせる構成となりました。

実は最近までHerokuを使ったことがなかったのですがリニューアルのついでに移行してみました。使い勝手が思っている以上に良く、Twelve-Factor Appを否が応でも意識させられるので長期的なアプリケーション開発を個人が目指すなら良い選択肢だと思います。
ただしHerokuはルートドメインをアプリに適用しようと思うとDNSのAliasレコードが必要になるため、Route53と負荷分散も兼ねてCloudFrontをセットで採用しました。CloudFrontを使う場合、AWS Certificate Managerを使うと無料でSSL証明書を発行・適用してくれるので便利です。
サーバサイドはNode.js、フロントエンドはVue.jsとVuexを使っています。
ソースコードは以下のレポジトリにあります。
https://github.com/ytanaka-/menthas
インタフェースとデザイン
ニュースにアノテーションを付ける
新MenthasではCuratorが3人以上のブクマしたニュースに関しては Highly Influential News というアノテーションを、Curateされて3時間以内の物に関しては New!というアノテーションを付けています。
地味に見えるかもしれませんが、こういったアノテーションはニュースの取捨選択に大きな影響を及ぼしていると思います。最終的には推薦も検索も人間の意思決定に委ねられるわけですから、インタフェースの観点からまだ推薦システムは洗練できる余地があるのではないかと思っています。
ちなみにニュースリーディングにおけるアノテーションの役割はこちらの論文が詳しいです。
Infinite Scrollの廃止
Infinite Scrollの問題について、こちらのNielsen Norman Groupの記事に詳しい解説があります。そこでは何か特定の情報を素早く得たいといった目的志向の検索タスクの場合、Infinite Scrollは推奨しないと主張されています。逆に暇つぶしに何かを発見するようなタスクの場合はInfinite Scrollが向いているようです。
Menthasの場合どちらかというと最新のIT系のニュースをチェックすることが目的なユーザが多く、探索的な検索欲求ははてなブックマークやTwitterの方で満たしているのではないかと考えたため、リニューアル版ではInfinite Scrollを廃止することにしました。
まとめと考察
今回はプログラマ向けのニュース推薦アプリであるMenthasの約3年ぶりのリニューアルについて解説させて頂きました。
振り返ると大学院の頃にニュース推薦もしくは情報推薦という分野に興味を持ったので、この分野に携わって5年以上ということになります。前回のリリースから約3年間、趣味の傍らでやり続けてきた研究と開発の集大成として、新Menthasのリリースを迎えられて本当に良かったと思っています。
既に2週間ほど試験的に運用しているのですが、毎日楽しく使えているのでなかなか便利なものができたと自負しています。
課題としては、カテゴリを増やしたり、キュレーター選出をTwitterなどの他のサービスに拡張したり、ニュースのカテゴリ分類をもっと洗練させるといったことが挙げられます。この辺りは今後ドックフーディングしながらさらに突き詰められたらと思っています。
さて、Eli Pariserが指摘したように人類はアルゴリズムによって確かにフィルタバブルに包まれつつあります。しかしそもそも我々の認知バイアスとしてフィルタに包まれる引力のようなものがあるとするなら(例えば確証バイアスなど)、それに抗うための仕組みもまたアルゴリズムによって提供することができるのではないでしょうか。
優秀なキュレーターを選出するアルゴリズムを使って自分の知らない領域の面白いニュースを見つけることができるように、そしてニュースの多様性のためにアルゴリズムを使ったように、うまくすればフィルタバブルを超えたものを推薦システムはみせることができます。
そんな情報推薦システムをこの先も追い求められれば良いなと思っています。
-
Neal Lathia, Stephen Hailes, Licia Capra, and Xavier Amatriain. 2010. Temporal diversity in recommender systems. In Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval (SIGIR '10). ACM, New York, NY, USA, 210-217. DOI: https://doi.org/10.1145/1835449.1835486 ↩
-
Marina Drosou and Evaggelia Pitoura. 2010. Search result diversification. SIGMOD Rec. 39, 1 (September 2010), 41-47. DOI: https://doi.org/10.1145/1860702.1860709 ↩ ↩2
-
https://searchengineland.com/google-domain-clustering-change-159997 ↩
-
Daichi Imamori and Keishi Tajima. 2016. Predicting Popularity of Twitter Accounts through the Discovery of Link-Propagating Early Adopters. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management (CIKM '16). ACM, New York, NY, USA, 639-648. DOI: https://doi.org/10.1145/2983323.2983859 ↩
-
Jun Zhang, Mark S. Ackerman, and Lada Adamic. 2007. Expertise networks in online communities: structure and algorithms. In Proceedings of the 16th international conference on World Wide Web (WWW '07). ACM, New York, NY, USA, 221-230. DOI: https://doi.org/10.1145/1242572.1242603 ↩
-
Jaime Carbonell and Jade Goldstein. 1998. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '98). ACM, New York, NY, USA, 335-336. DOI: https://doi.org/10.1145/290941.291025 ↩