こちらは NEC デジタルテクノロジー開発研究所 Advent Calendar 2023 8日目の記事です.
本記事では,5日目の記事 FireDucks 内部で働く高速化技術: GroupByアリゴリズムの切り替え について,より踏み込んで解説します.
先日の記事では,FireDucks では高速な GroupBy 操作を実現するために,グループ数を推定し,推定したグループ数に応じて計算アルゴリズムを切り換えていると紹介しました.
本記事では,グループ数がどのように計算速度に影響するのか,GroupBy の計算アルゴリズムを踏まえて解説したいと思います.
GroupBy とは
GroupBy は表データを分析するための基本的かつ重要な操作のひとつで,主に集約関数 (sum, count, mean, min, max など) と組み合わせて使用されます.表データを特定のカラムの値に基づいていくつかのグループに分け,それぞれのグループに対して別途指定したカラムの合計や平均など集計を行います.
以下は,果物の売上データをもとに各商品ごとの総販売個数を集計する例です.それぞれの商品(りんご,ぶどう,みかん)ごとにグループ分けし,それぞれの商品に対して販売個数の総和を計算しています.
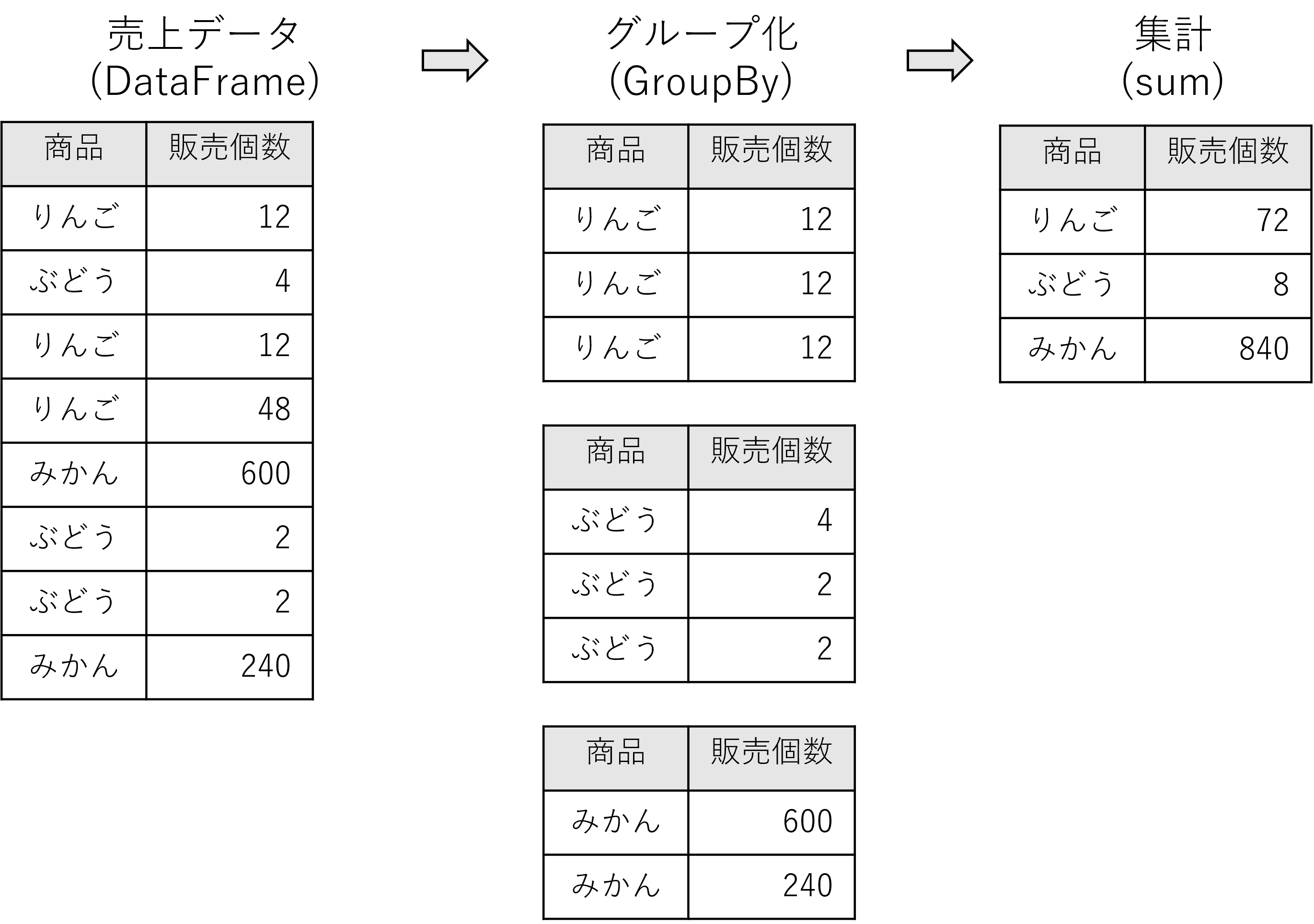
GroupBy の並列化
FireDucks の特徴の1つとして,マルチスレッドを用いた並列処理があげられます. GroupBy についても,並列化による高速化を行っています.
本記事の導入で述べていますが,FireDucks では2種類のGroupBy のアルゴリズムを使い分けています.この2種類のアルゴリズムの違いというのが,並列化方式の違いなのです.
以下に,2種類の並列化方式を説明します.
(簡単化のために,図示している動作例での並列度は2とします)
並列化方式1
まずは,1つめの並列化方式です.手順の概略は以下の通りです.
- 入力データを上から均等分割
- 各スレッドがそれぞれの分割データごとにグループ化して集計 (Local-GroupBy)
- 分割ごとの集計結果をあつめ,全体でグループ化して集計 (Global-GroupBy)
以下の図は,先の果物の売上データの総販売個数の集計を並列化した場合です.それぞれの分割データを並列に計算し,ローカルに集約することで小さくなった集計データを結合して再集計することで高速化を行っています.

しかし,このような方法だとうまく高速化されない場合があります.
以下の図は,各顧客の売上額の集計を並列化した場合です.顧客IDでグループ化をするのですが,実は顧客ID のばらつきが大きいデータ(顧客IDがばらばら)の例となっています.
顧客IDのばらつきが大きいため,それぞれの分割データを集計した結果を集めたところ,分割前とほとんど変わっていません.これでは,分割してローカルに集計した意味がなく,再度同じだけのデータ量を再集計することになってしまっています.

並列化方式2
そこで FireDucks ではデータを均等分割ではなく,値に応じて分割する方式も実装しています.
- 入力データを,グループ化対象の列(グループキー列)の値に応じて分割
- 各スレッドがそれぞれの分割データごとにグループ化して集計 (Local-GroupBy)
- 分割ごとの集計結果を集める(再集計不要)
以下の図は,先のばらつきの大きい顧客データの集計を並列化方式2で並列化した場合です.
データを上から均等分割するのではなく,顧客IDに基づいて 顧客ID が 400未満のデータと400以上のデータに分割しています.それぞれの分割データごとにグループ化して集計し,最後にローカルの集計結果をあつめて終了です.顧客ID に応じて分割しているので,それぞれのローカルの集計結果には顧客IDの重複がないので,再集計が不要です.
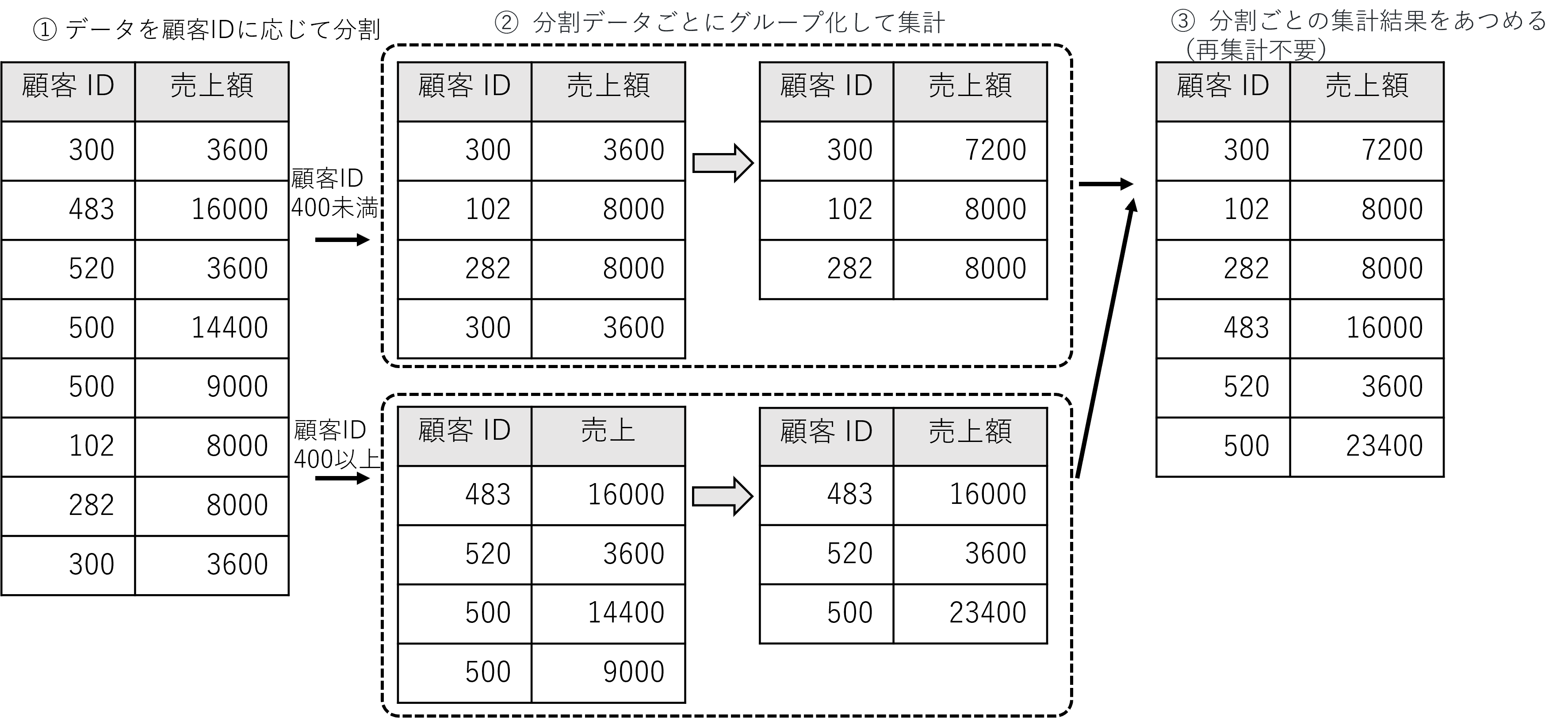
再集計が不要ということで,こちらの方式が良さそうに見えますが,実はそうとも限りません.
上の例では,しれっと 顧客IDが 400未満のデータと400以上のデータに分割としましたが,適当に決めてしまっては分割ごとのデータ量に大きなばらつきが発生してしまします.データ量にばらつきがないように分割の閾値をうまく調整してあげる必要があります.
GroupBy の2つの並列化方式の使い分け
2つの並列化方式は「データ分割の単純さ」と「再集計の有無」にトレードオフの関係にあります.
| データ分割 | 再集計 | |
|---|---|---|
| 並列化方式1 | 単純 | 必要 |
| 並列化方式2 | 閾値の決定が必要 | 不要 |
したがって,再集計のコストが大きくなりそうな場合は再集計の不要な並列化方式2を用いて,再集計のコストが小さくなりそうな場合はデータ分割が単純な並列化方式1を使うという,並列化方式の使い分けをすればよさそうです.
では,どういった場合に再集計のコストが大きくなるかというと,分割データごとのグループ化であまり集約されない場合です.つまりグループキーの値がばらばらな場合 = グループ数が大きい場合です.そこで FireDucks では,あらかじめグループ数がどの程度になりそうかを推定することで,どちらの並列化方式を用いるかを切り換えています.
- 推定グループ数が大きい場合 ⇒ 再集計が不要な並列化方式2
- 推定グループ数が小さい場合 ⇒ 再集計してもよいので,単純な分割の並列化方式1
さいごに
本記事では,FireDucks の内部で行っている GroupBy の2つの並列化方式の使い分けについて紹介しました.
FireDucks は,私を含め NEC デジタルテクノロジー開発研究所の高速化が大好きなメンバーが開発をすすめています.今後の Advent Calendar でも FireDucks の高速化に関する記事など,様々なトピックが出てくると思います.是非ご期待ください.