はじめに
Maddison Project Database 2020を使って、日米の1人当たりGDPの長期時系列のグラフを実数スケールと対数スケールで描いてみることにした。
Maddison Project Database自体は、countrycode,country,year,gdppc(1人当たりGDP)、pop(人口)だけのデータなので、Excelファイルのまま処理しても大したことはないが、とりあえずプログラムにしてみた。
データ
Maddison Project Database 2020のExcelデータ( 'https://www.rug.nl/ggdc/historicaldevelopment/maddison/data/mpd2020.xlsx' )をダウンロードして、人口データが継続して得られている年からのデータを利用した(アメリカの場合1820年以降、日本の場合1885年以降)。
コード
import pandas as pd
import matplotlib.pyplot as plt
# Excelファイルの読み込み
df = pd.read_excel('https://www.rug.nl/ggdc/historicaldevelopment/maddison/data/mpd2020.xlsx', sheet_name='Full data')
def plot_gdp_per_capita(df, country_codes, start_year):
plt.figure(figsize=(10, 5))
for country_code in country_codes:
# 指定した国のデータのみをフィルタ
country_data = df[df['countrycode'] == country_code]
# 指定した年以降のデータに限定
country_data = country_data[country_data['year'] >= start_year]
# 終了年を取得
end_year = country_data['year'].max()
# グラフを描画(実数で表示)
plt.plot(country_data['year'], country_data['gdppc'], label=country_code)
plt.title(f'GDP per capita ({start_year}-{end_year})')
plt.xlabel('Year')
plt.ylabel('GDP per capita (real scale)')
plt.legend()
plt.grid(True)
plt.show()
plt.figure(figsize=(10, 5))
for country_code in country_codes:
# 指定した国のデータのみをフィルタ
country_data = df[df['countrycode'] == country_code]
# 指定した年以降のデータに限定
country_data = country_data[country_data['year'] >= start_year]
# グラフを描画(対数目盛で表示)
plt.plot(country_data['year'], country_data['gdppc'], label=country_code)
plt.yscale('log')
plt.title(f'GDP per capita ({start_year}-{end_year})')
plt.xlabel('Year')
plt.ylabel('GDP per capita (log scale)')
plt.yticks([500, 2500, 12500, 62500], ['500', '2500', '12500', '62500'])
plt.legend()
plt.grid(True)
plt.show()
# アメリカと日本の1820年以降のデータを表示
plot_gdp_per_capita(df, ['USA', 'JPN'], 1820)
出力
-
実数スケール
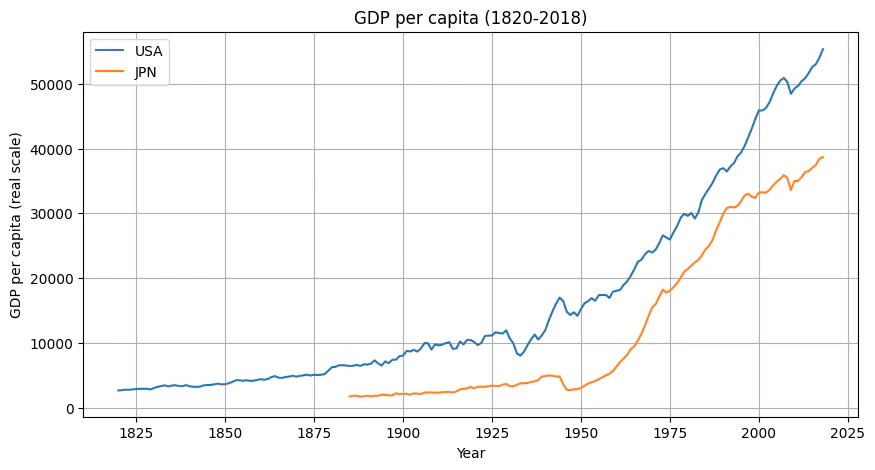
-
対数スケール
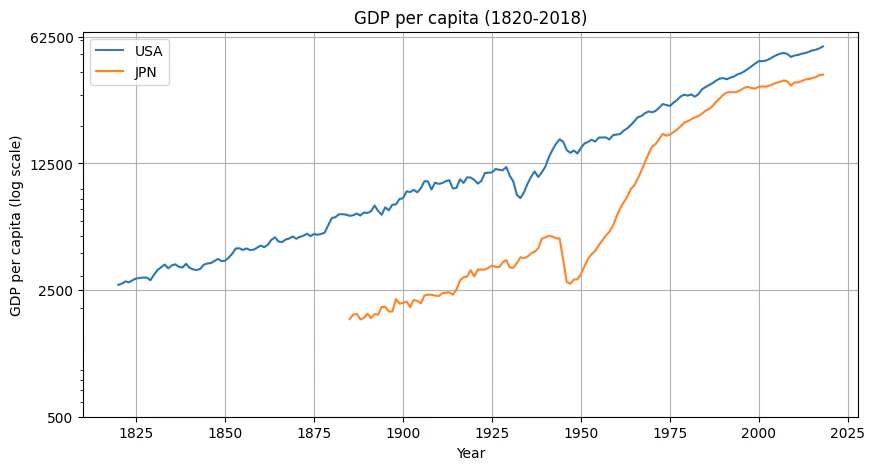
改善点
対数スケールのグラフの目盛りを自動化したかったが、自動化するとあまりいい表示にならなかったので、米国データに合わせて今回は手動入力。他の国について描く場合を想定するとよくないが、10^4だけしか表示されないのでは面白くなかったので、今回はこれで諦めた。