
1080P120のビデオをSBC(ROCK5B)で推論している動画です。平均で360FPS程度出ているので、3倍速で再生されています。これなら高速移動体からも正確にパイロンへの距離が認識出来ます。
目次
- NPUとは?
- 高速推論を実行するまでの流れ
- Yolov5での学習
- Export
- RKNN形式への変換
- Edgeデバイスでの推論
NPUとは
NPUは、Neural Processing Unitの略称で、AI専用のプロセッサーです。NPUは大量の計算を並列処理することに特化しており、機械学習に専用設計されたチップであるため、GPUよりも効率的に処理を実行できます。NPUを使うことで、画像認識や自然言語処理などの機械学習タスクを高速に実行することができます。最近は、IntelやAMD、モバイルデバイス向けに多く組み込まれるようになってきています。
今回利用するするROCK5Bに搭載されているRockchip3588のNPUの性能は6TOPSです。来年出てくるRyzenAIのNPUは36TOPSです。エッジデバイスでLLMが普通に動く未来が近いうちにやってきそうです。
高速推論を実行するまでの流れ
今回はRockchipのRK3855に搭載されるNPUを使って高速推論を試みます。このNPUで推論するためには、モデルをRKNNというRockchip独自形式に変換しなければなりません。このため、多くの工程が必要で以下のような流れとなっております。
- 学習環境の構築、学習
- モデル変換環境の構築、変換
- エッジ推論環境の構築、推論実行
構成
今回は、ColabとEC2で作業していますが、dockerなり、localなりお好みの環境で変換作業をして下さい。
| 工程 | ソフトウェア環境 | ハードウェア環境 |
|---|---|---|
| 学習 | ultralytics yolov5(*.pt) | Google Colab GPU Runtime |
| エクスポート | airockchip yolov5(*.torchscript) | AWS EC2 t2.large Ubuntu 22.04 30GB |
| モデル変換 | rknn_toolkit2 + rknn_model_zoo(*.rknn) | AWS EC2 t2.large Ubuntu 22.04 30GB |
| エッジ推論 | rknn-cpp-Multithreading | ROCK 5B |
Yolov5での学習
インターネット上の他のチュートリアルなどを参考にyolov5でカスタムモデルの学習をするためのデータを準備して下さい。Google Colab GPUインスタンスの利用を前提とします。利用するモデルはYOLOv5nでもYOLOv5sでもOKです。極めて高速で動作するので、速度は実用上問題になりません。YOLOv5sがおすすめです。カスタムモデル学習の際に注意する点は、 実際に検知したいクラス数が1つや2つであっても、クラス数を80 にしてください。このクラス数を変えるとモデルのoutputの形が変わってしまいRKNNでの推論時にエラーが出ます(各フォーラムでもこの部分で躓いてしまっている人が多いようです)。以下のようにdataset.yamlを定義し学習を開始してください。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /content/imgs/train
val: /content/imgs/val
# number of classes
nc: 80
# Classes
names:
0: YOUR-CLASS-1
1: YOUR-CLASS-2
2: YOUR-CLASS-3
3: dummy3
4: dummy4
~~途中省略~~
78: dummy78
79: dummy79
学習を開始しましょう。
%cd /content/yolov5
!python train.py --batch 32 --epochs 100 --weights yolov5s.pt --data '/content/imgs/dataset.yaml' --project '/content/drive/MyDrive/YOUR-PROJECT-DIR' --name YOUR-PROJECT-NAME
Export
AWS EC2 t2.large Ubuntu 22.04 30GBを準備してSSHでログインします。変換にあたってPythonのバージョン指定があるので、minicondaを入れて進めていきます。
sudo apt update
sudo apt upgrade
sudo apt install -y python3 python3-dev python3-pip
sudo apt install -y libxslt1-dev zlib1g zlib1g-dev libglib2.0-0 libsm6 libg11-mesa-glx libprotobuf-dev gcc libgl1-mesa-dev
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
Python3.8の仮想環境を作ります。
conda create -n rknn-convert python=3.8
conda activate rknn-convert
NPUで処理するのに適したモデルの形のONNX形式にairockchip/yolov5を使ってエクスポートします。ultralytics公式のyolov5でonnxエクスポートするとoutputのシェイプが異なるため、NPUを使っての推論が出来ません。
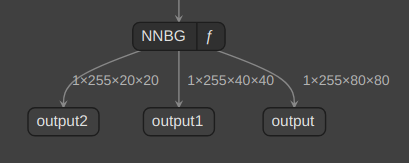
以下が普通のONNX形式の出力です。このカスタムモデルのクラス数は3なので[x1,y1,x2,y2,cls1_conf,cls2_conf,cls3_conf]が8400あります。
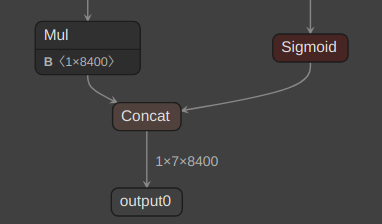
RK3588のNPUで推論するには以下のような形にする必要があります。
Google Colabで学習した結果のbest.ptファイルを./yolov5/にコピーすることを忘れないでください。
git clone https://github.com/airockchip/yolov5.git
cd yolov5
pip3 install -r requirements.txt
# 【Google Colabで学習した結果のbest.ptファイルをここにコピーする】
python export.py --rknpu rk3588 --weight best.pt -imgsz 640
cd ../
yolov5配下にbest.torchscriptが出力されます。
RKNN形式への変換
RKNNの依存関係を解決しておきます。
git clone https://github.com/rockchip-linux/rknn-toolkit2.git
pip3 install -r ./rknn-toolkit2/doc/requirements_cp38-1.5.2.txt
pip3 install ./rknn-toolkit2/packages/rknn_toolkit2-1.5.2+b642f30c-cp38-cp38-linux_x86_64.whl
ONNXからRKNNへの変換環境を作成します。
git clone https://github.com/airockchip/rknn_model_zoo.git
cp ./yolov5/best.torchscript ./rknn_model_zoo/models/CV/object_detection/yolo/RKNN_model_convert/
cd ./rknn_model_zoo/models/CV/object_detection/yolo/RKNN_model_convert/
yolo.ymlを下記のように編集します。
#support yolo[v5,v6,v7,v8], ppyoloe_plus
model_framework: pytorch
model_file_path: best.torchscript
RK_device_platform: RK3588
# RK_device_id: simulator
dataset: ../../../../../datasets/COCO/coco_subset_10.txt
quantize: True
pre_compile: online
graph:
in_0:
shape: 1,3,640,640
mean_values: 0
std_values: 255
img_type: RGB
configs:
quantized_dtype: asymmetric_quantized-8
quantized_algorithm: normal
optimization_level: 3
# force_builtin_perm: True
RKNNへの変換を実行します。
bash convert_yolo.sh
ようやくRKNN形式のモデルが./model_cvt/RK3588/best_RK3588_i8.rknnという形で出力されます。このファイルをEdgeデバイスにコピーしておいてください。
Edgeデバイスでの推論
まず推論用の依存関係を解決します。
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
conda create -n rknn-inference python=3.8
conda activate rknn-inference
git clone https://github.com/rockchip-linux/rknn-toolkit2.git
pip3 install -r ./rknn_toolkit_lite2/packages/rknn_toolkit_lite2-1.5.2-cp38-cp38-linux_aarch64.whl
マルチスレッドでNPUを限界まで使い切るためのリポジトリを準備します。
git clone https://github.com/leafqycc/rknn-cpp-Multithreading.git
./rknn-cpp-Multithreading/model/RK3588/にAWSで変換したbest._RK3588_i8.rknnをコピーしてください。
また推論させたい動画を./rknn-cpp-Multithreading/に配置してください。
buildするためのシェルを下記のように書き換えます。
set -e
# TARGET_SOC="rk3588"
GCC_COMPILER=aarch64-linux-gnu
export LD_LIBRARY_PATH=${TOOL_CHAIN}/lib64:$LD_LIBRARY_PATH
export CC=${GCC_COMPILER}-gcc
export CXX=${GCC_COMPILER}-g++
ROOT_PWD=$( cd "$( dirname $0 )" && cd -P "$( dirname "$SOURCE" )" && pwd )
# build
BUILD_DIR=${ROOT_PWD}/build/build_linux_aarch64
if [ ! -d "${BUILD_DIR}" ]; then
mkdir -p ${BUILD_DIR}
fi
cd ${BUILD_DIR}
cmake ../.. -DCMAKE_SYSTEM_NAME=Linux
make -j8
make install
cd -
# relu版本
cd install/rknn_yolov5_demo_Linux/ && ./rknn_yolov5_demo ./model/RK3588/best._RK3588_i8.rknn ../../YOUR-VIDEO.mp4
# 使用摄像头
# cd install/rknn_yolov5_demo_Linux/ && ./rknn_yolov5_demo ./model/RK3588/yolov5s-640-640.rknn 0
※webカメラを利用する場合は、最下部のコメントアウトされている部分を有効にすれば良いようです。
それでは、超高速推論を実行していきます。cv::imshowで結果を表示しているのでGUI環境が必要です。
cd ./rknn-cpp-Multithreading/
bash build-linux_RK3588.sh
SBCでの推論で瞬間的に400FPS出ています!
TIPS
スレッド数を増やす
./rknn-cpp-Multithreading/src/main.ccの以下の部分でスレッド数が定義されています。
int threadNum = 3;
この部分を3,6,9,12と増やしていけば、NPUを限界まで利用することができます。Rockchip RK3588の場合、NPUコアは3つ搭載されているので、3の倍数が効率が良いです。
モデルのサイズについて
今回の検証はsmallで行いましたが、nanoでも推論はできて、更に高速に動作しました。
消費電力
検証に利用したROCK5Bの場合、12スレッドNPU全開+CPU使用率70%程度で15Wの消費電力でした。実運用で300FPS以上が必要になることはないと思います。シングルスレッドの場合は、モデルサイズsmall/解像度640->推論時間100msとなります。このときのNPU使用率は10%、CPU利用率5%以下、消費電力はアイドルの5Wからほぼ変わらずとなりました。また、エッジデバイスであっても大きなモデルや高解像度で推論できる未来が見えます。
NPU使用率の確認方法
sudo cat /sys/kernel/debug/rknpu/loadでNPUの利用率を確認できます。
モニタリングしたい場合は、watch -n 1 sudo cat /sys/kernel/debug/rknpu/loadとすると良いでしょう。
まとめ
現状、ベンダー毎に提供されるAPIを利用したりモデルの変換の手間がありますが、低消費電力で超高速推論が可能となっています。今後、NPUが驚異的な速度で発展していくと思いますので、この記事を書きました。日本語でのNPUに関する技術情報がほとんどなかったので、この情報発信がNPU利用の気運の向上の一助になることを願っております。