この記事はCompetitive Programming (1) Advent Calendar 2019 19日目のエントリーです。
今回は過去に少し使ったことのあるElasticsearch + Kibanaを用いてAtCoderの過去に提出したコードを検索することのできるサービスを作っていこうと思います。
はじめに
みなさん、競プロしてますか? もちろんしていますよね。最近はAtCoderを筆頭に競プロ人口が爆発的に増えているようで嬉しい限りです。
人が増えてくるにしたがって初心者が入門しやすくなるようなカリキュラムや様々な便利ツールなどが普及してきて徐々に競プロに対する敷居が下がっているのを感じます。
さてみなさん、競プロをしていて「過去の自分のコードを参照したい」、「他の人がこのライブラリをどのように使っているか見たい」などと思ったことはないでしょうか?自分のコードであればある程度ローカルに溜めていたりGitHubに登録していたりで検索できる場合が多いと思いますが、他の人のコードの場合、ある程度使っていそうな問題の見当をつけて開くしか手立てがないと思います。
そこで、提出された大量のコードの中から特定の変数名・クラス名で検索する機能はそこそこ需要があるのではと思い、今回提出コードの検索を行うサービスを作ってみることにしました。
何を使うか
検索をするにはどんな技術を使えばいいのでしょうか。仮に現時点で存在する提出を全てを検索対象にする場合、およそ10の7乗オーダーの数の提出が存在するらしいです。適当に前から見ていくような検索方法では1回の検索にかなりの時間がかかってしまいそうですね。僕はそこまで検索アルゴリズムに詳しくないので、大規模データの検索に広く使われているオープンソースとして有名なElasticsearchを用いることにしました。
Elasticsearch
ElasticsearchはElastic社が開発しているREST APIを用いた操作が可能な全文検索エンジンです。詳しい説明は nskydivingさんが書いているこちらの記事がわかりやすいと思います。
はじめての Elasticsearch
ElasticsearchはJavaで書かれたLuceneと呼ばれる検索エンジンを元にできており、そこにindexの作成やデータ登録などの主要な機能をREST API形式で処理できるようにラッピングしたものがElasticsearchと呼ばれています。
Kibana
また、併せて使われるサービスにKibanaがあります。ElasticsearchはJSON形式でデータを返すため、返してきたデータをわかりやすく可視化するサービスという位置付けでKibanaは使われます。検索結果を可視化する以外にもサーバやDBと連携させることによるトラフィックの可視化や異常の検知、時系列データを使った機械学習など実に幅広い用途で使うことができるそうです。
Amazon Elasticsearch Service
ElasticsearchをデプロイするためのAWSのサービスです。VPCやIPアドレスの指定など様々な方法でアクセス制限をしたりスケールが容易にできたりととても便利ですが、インスタンスは1時間ごとの課金なので遊んでいたら課金額がすごくなっていた、なんてことのないように気をつけましょう。
Flask, Heroku
実家のような安心感。だいたいちょっとしたアプリを遊びで作ってデプロイするときはこのセットを使っています。
実装フェーズ
完成品をデプロイするのはそんなに難しくない気がするのでとりあえずローカルで作っていきます。環境はMac OSを想定しています。
Elasticsearch, Kibanaを立ち上げる
Elastic社の公式ページ(このへん)とかからMac用のgzipをダウンロードしてきて、展開します。
展開されたフォルダ内には bin/elasticsearch bin/kibanaという実行ファイルがあるのでこれを叩いてあげることでローカルでサービスが立ち上がります。デフォルトのポートはElasticsearchが9200、kibanaが5601なのでそれぞれlocalhost:9200、localhost:5601にアクセスすると動作が確認できます。
今回は適当にフォルダを置いてそこからコマンドを叩きましたがデーモンなど使って常駐させることもできるのでよかったら調べてみてください。
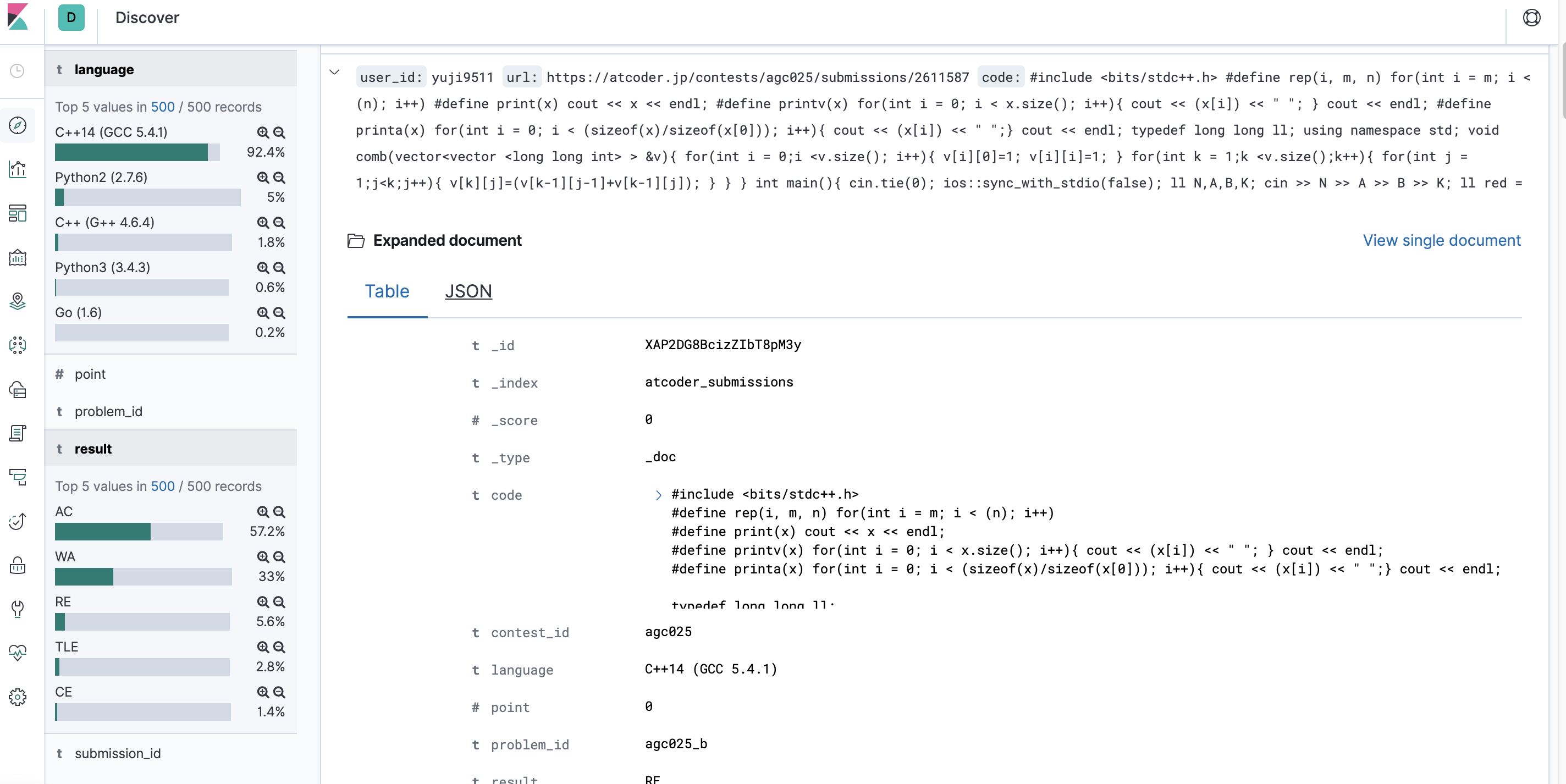
AtCoderの提出コードをスクレイピングし、elasticsearchに登録する
AtCoderの提出コードをユーザIDごとにスクレイピングしていきます。ユーザIDに紐づいている提出IDの取得はいつもお世話になっているkenkooooさんのAtCoder Problems APIを使わせていただきました。ユーザIDと提出IDを用いてページのhtmlを取得し、タグなどを適当に除去してあげることでコードの部分だけ抽出を行いました。生のコードだけ取得できるAPIもあるんですかね、あったら教えてください。
取得したコードを投入していきます。elasticsearchはkey-value形式でデータごとに柔軟にデータ構造を決定することができます。今回は提出コード一つ一つに対し、user_id, url, code, submission_id, contest_id, language, result, problem_id, pointのカラムを用意してデータを投入しました。全てAtCoder ProblemsのAPIに情報として含まれていました。ありがとうございます。
スクレイピング&提出部分のコードを載せておきます。
import os, sys
import json
import urllib.request
import requests
from html.parser import HTMLParser
from elasticsearch import Elasticsearch
from tqdm import tqdm
es = Elasticsearch()
class Parser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.title = False
self.link = False
self.data = []
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
# print(tag, attrs)
if tag == "pre":
self.data.append({})
self.title = True
self.link = True
if tag == "a" and self.link == True:
self.data[-1].update({"link": attrs["href"]})
def handle_data(self, data):
if self.title == True or self.link == True:
self.data[-1].update({"title": data})
self.title = False
self.link = False
def getSubmissionCode(url):
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as res:
body = res.read()
return body
if __name__ == "__main__":
user_name = "yuji9511"
url_api = "https://kenkoooo.com/atcoder/atcoder-api/results?user=" + user_name
# print(url_api)
res = requests.get(url_api)
data = json.loads(res.text)
# print(data)
for i, d in tqdm(enumerate(data)):
sub_id = d["id"]
contest_id = d["contest_id"]
url = "https://atcoder.jp/contests/" + str(contest_id) + "/submissions/" + str(sub_id)
res = getSubmissionCode(url)
res = str(res)
parser = Parser()
parser.feed(res)
parser.close()
code = ""
for i in parser.data:
code = i['title'].replace("\\r\\n", "\n").replace("\\t", " ")
break
body = {
"user_id": user_name,
"url": url,
"code": code,
"submission_id": str(sub_id),
"contest_id": str(contest_id),
"language": d["language"],
"result": d["result"],
"problem_id": d["problem_id"],
"point": d["point"]
}
es.index(index="atcoder_submissions", body=body)
データの投入はindex名(RDBSのテーブル名みたいなもの)と投入したいデータをbodyとして指定してあげるだけです。デフォルトのlocalhost:9200以外にelasticsearchを設置した際はes = Elasticsearch()の括弧内にurlおよびportの設定を行ってください。
検索を実行する
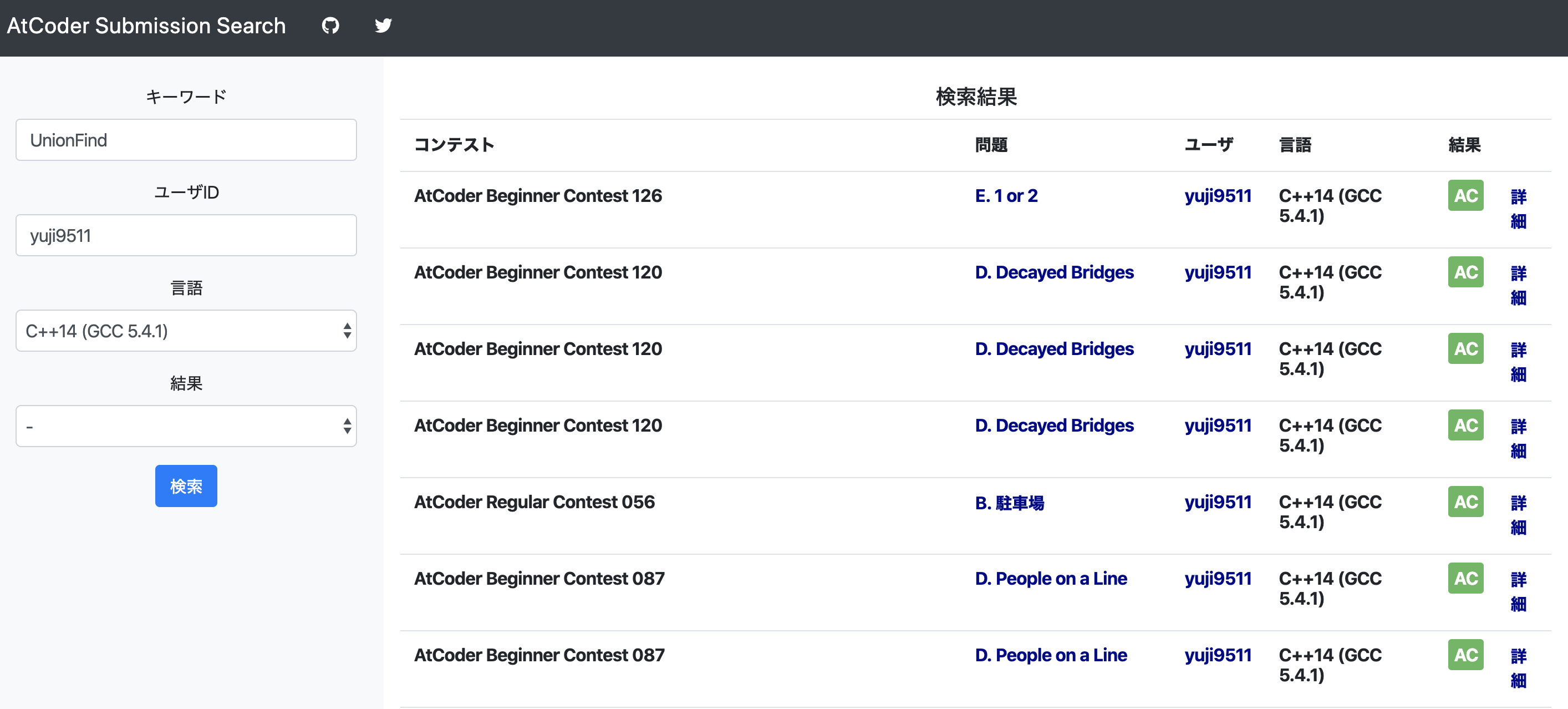
データが投入できたので検索機能を作っていきます。 検索結果がどうなるかはkibanaを使うと手軽に確認できるため、Pythonでの実装を行う前に試してみると作業がスムーズに進むと思います。
検索に用いるパラメータはキーワード、ユーザID、提出言語、結果(AC,WAとか)の4種類にしました。
それぞれのパラメータに対して指定があった際は絞り込みのAND検索を行い、指定がない際はフィルタをかけないように設定します。
elasticsearchはMySQLでいうSQL文のようなものもjson形式で記述することができ、Pythonでクエリを投げる際はdict型のオブジェクトに検索条件を指定していきます。
検索のメインの部分の実装のみピックアップしてみます。
es = Elasticsearch()
def getSearchResults(params):
keyword = params["keyword"]
user_id = params["user_id"]
language = params["language"]
result = params["result"]
print(language)
must_query = []
if keyword != "":
must_query.append(
{
"query_string": {
"query": keyword,
"fields": [
"code"
]
}
}
)
if user_id != "":
must_query.append(
{
"query_string": {
"query": user_id,
"fields": [
"user_id"
]
}
}
)
if language != "-":
must_query.append(
{
"query_string": {
"query": '"' + language + '"',
"fields": [
"language"
]
}
}
)
if result != "-":
must_query.append(
{
"query_string": {
"query": result,
"fields": [
"result"
]
}
}
)
query = {
"_source": "*",
"size": 50,
"query": {
"bool": {
"must": must_query
}
}
}
res = es.search(index=index_name, body=query)
return res
検索はelasticsearch側でつけた点数にしたがって優先順位が決定されます。完全検索のみによる検索だけではなく、表記ゆれなどによって似ていると判断されたものについても検索結果としてヒットすることがあります。もちろんこの点数の付け方に関しても細かい指定が可能です。
検索結果を表示する
Flaskで実装したのでPython側で取得した結果をhtml側に返して表示してあげます。問題名やAC/WAなどの基本的な情報に加えて該当の提出へのリンクなどを追加しました。その場でコードを見れるようにしようかなとも思ったのですが、かなりスペースとってごちゃごちゃしそうなのでやめました。
デプロイする
Flaskのアプリに関してはHerokuあたりを使ってデプロイするのが一番手っ取り早いでしょう。elasticsearchはAWSのサービスの一つであるAmazon Elasticsearch Serviceを使うのが簡単かなと思います。デプロイの手順に関しては探せばわかりやすいサイトがたくさん出てくるので割愛します。
デプロイはしようと思えばできるのですが現在はしていません。これはかなり大事なことなので覚えてほしいのですが、elasticsearchを動かすと結構なリソースを使うので結構な課金が発生します。おそらく稼働時間ごとに課金が発生するみたいで、僕が少しの間遊んでいただけでも1万円近く請求が発生していました。クラウドを使う際には課金額にくれぐれも注意しましょう。
おわりに
まだ公開していないので今のところ完全に自分しか使えないサービスになってしまっていますが、過去に実装した類似のコードを見たい時とかは結構使える気がしました。また、他の人はこんな変数名を使わない/使いがち、などといったどうでもいい情報も得ることができそうです。
また、このアプリで書いたコードはysugiyama12/atcoder-submission-searchにあります。大して中身はありませんがよかったらご覧ください。
ちなみに、Flaskを使うとどうでもいいアプリをものすごい高速に作ることができるのでオススメです。よかったらこないだ作ったAtCoderのレーティンググラフをいじれるクソアプリAtCoder RatingGraph Generatorもご覧ください。
今年も残り少ないですが年末にはコンテストが異常に集中しているので最後まで気を抜かず精進していきたいと思います!