はじめに
IBM Cloud Pak for Data(以下、Cloud Pak for DataまたはCP4D)をIBM Cloudのカタログからクイックにインストールする方法を試します。Cloud Pak for DataはAIやデータ分析などの様々なサービスによって拡張可能な統合的なデータプラットフォームです。これから紹介する手順の実施によりCloud Pak for DataをIBM Cloud上に構築することができます。
※2020年10月に実施した手順です。製品のバージョンアップ等により設定項目および手順の実施結果は変更される可能性があります。
IBM Cloud Pak for Dataは、企業がデータを収集、編成、分析し、組織全体にAIを組み込む方法をモダナイズする、データとAIのための完全に統合されたプラットフォームです。Red Hat OpenShift Container Platform上に構築されたIBM Cloud Pak for Dataは、市場をリードするIBM WatsonのAIテクノロジーを、データ管理のIBM Hybrid Data Management Platformや、DataOps、ガバナンス、ビジネス・アナリティクスのテクノロジーと統合します。これらの機能を組み合わせて、絶えず変化する企業のニーズに対応するAIの情報アーキテクチャーを提供します。
わずか数時間で導入でき、増え続ける数々のIBMやサード・パーティーのマイクロサービスを使用して簡単に拡張可能なIBM Cloud Pak for Dataは、あらゆるクラウド上で稼働し、企業がより簡単に分析とアプリケーションを統合して、イノベーションを加速できるようにします。IBM Cloud Pak for Dataは、総所有コストを削減し、オープン・ソース・テクノロジーに基づいてイノベーションを加速し、Amazon Web Services(AWS)、Azure、Google Cloud、IBM Cloud、プライベートクラウドなどのマルチクラウド環境を完全にサポートします。
IBM Cloud は、豊富な種類の製品を含んだカタログ付きの、フルスタックのパブリック・クラウド・プラットフォームを提供します。製品には、コンピュート、ストレージ、およびネットワークのオプション、アプリ開発用のエンドツーエンドの開発者向けのソリューション、テストとデプロイメント、セキュリティー管理サービス、従来型およびオープン・ソースのデータベース、クラウド・ネイティブ・サービスなどが含まれます。 これらすべてのサービスをカタログ内の「サービス」タブで見つけることができます。 これらのサービスのライフサイクルと運用は、IBM の責任になります。
「ソフトウェア」タブに表示されるソフトウェア製品のカタログは成長を続けており、Cloud Pak、スターター・キット、Terraform ベースのテンプレート、Helm チャートなどが含まれています。お客様のコンピュート・リソース上でのこれらのソフトウェア製品のライフサイクル管理、デプロイメント、および構成はお客様の責任になりますが、単純化されたインストール・プロセスを利用することで、すぐに稼働を開始できます。
前提
- IBM Cloud のアカウント(従量課金アカウントまたはサブスクリプション・アカウント)が必要です。
- Cloud Pak for Dataのライセンスが必要です。
- 必要条件やリソース要件はREADME(英語)の記載に従います。
Cloud Pak for Data インストール
カタログからのインストールは画面に表示された設定項目の選択だけで実施できます。
以下に実施した手順と結果を記載します。
バージョンは以下の通りです。
- Cloud Pak for Data : v3.0.1
- Red Hat OpenShift Cluster : v4.3.38
IBM CloudカタログからCloud Pak for Dataのインストール画面にアクセスする。
-
IBM Cloudのログイン画面よりログインします。
-
カタログを選択します。

-
ソフトウェアを選択します。
-
Cloud Pak for Dataを選択します。
-
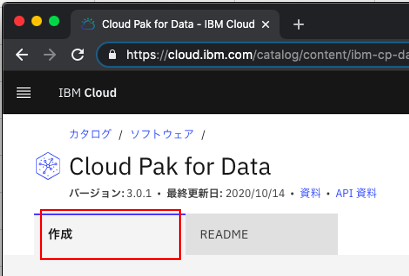
「作成」タブを選択します。
※「README」ではインストールの必要条件やリソース要件を確認できます。
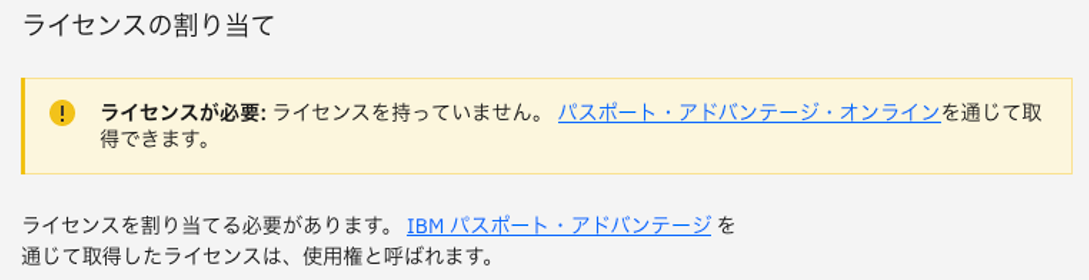
Cloud Pak for Dataのライセンス割り当てを行う。
- 表示されたライセンスを選択して「割り当て」を選択します。

- 使用可能なライセンスがある場合は上記のように表示されますが、ない場合は下記のように表示されます。割り当てが成功すると画面右側のサマリー欄にライセンスの内容が表示されます。

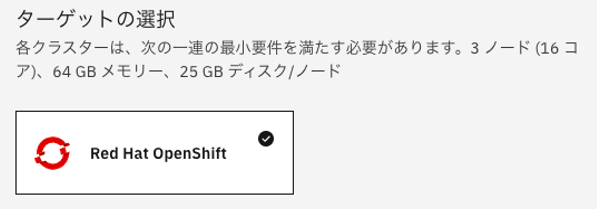
ターゲットの選択、メソッドの選択を行う。
-
ターゲットの選択を規定のままにします。
-
メソッドの選択を規定のままにします。

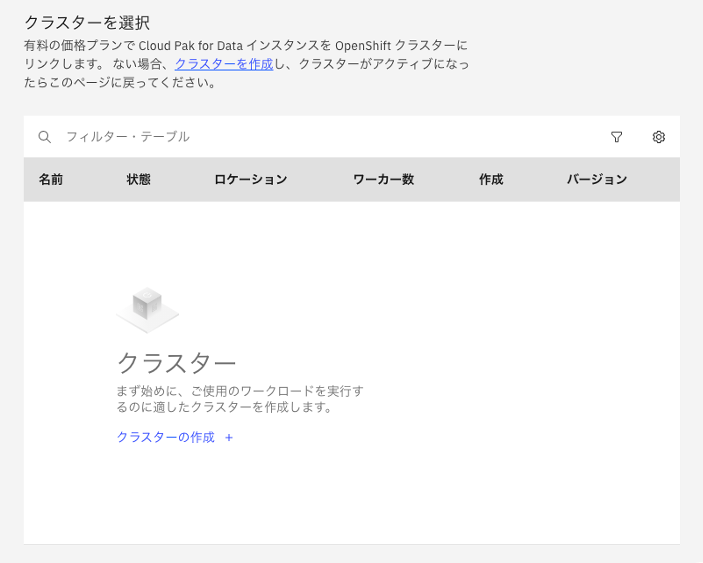
OpenShiftクラスターを作成する。
-
「クラスターを作成」または下部にある「クラスターの作成 +」を選択します。
-
Red Hat OpenShift Clusterの画面に遷移するのでここでクラスターの作成手順を実施します。
-
オーケストレーション・サービスを選択します。
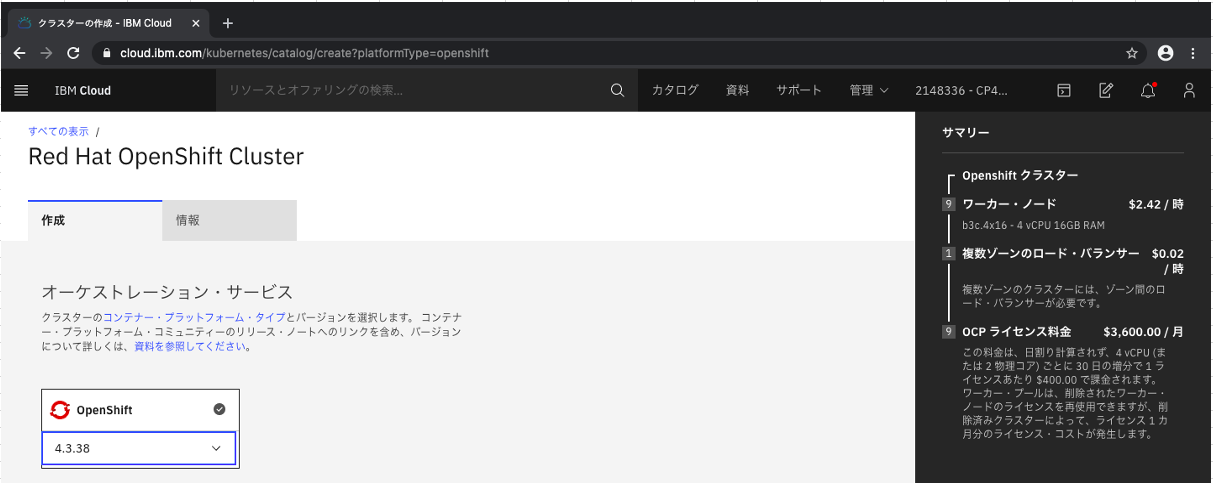
※OpenShift 4.4.27がデフォルトで選択されていますが、2020年10月30日現在では4.4.27のままだとCloud Pak for Dataの導入先のOpenShiftクラスターを選択する時に以下のエラーが表示されました。4.3.38であれば問題ないことを確認しています。

-
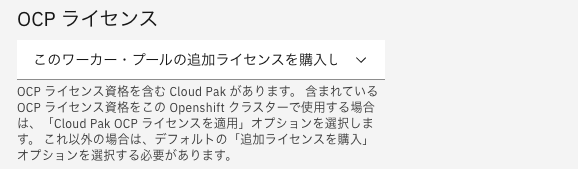
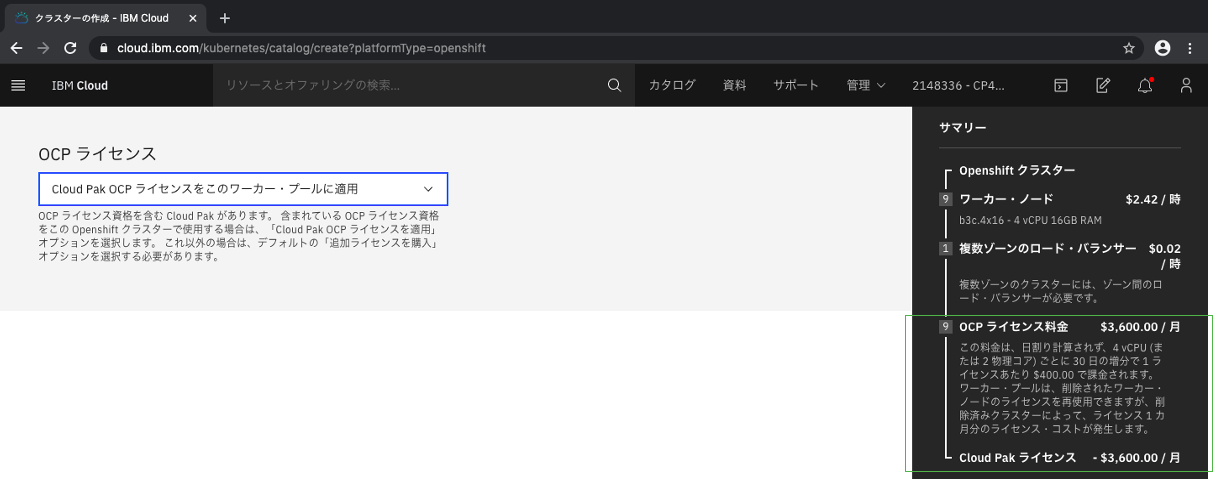
OCPライセンスを選択します。OCPライセンスが取得済みの場合は下記のように選択欄が表示され、
このワーカー・プールの追加ライセンスを購入しますかCloud Pak OCP ライセンスをこのワーカー・プールに追加を選択できます。未取得の場合は表示されません。
このワーカー・プールの追加ライセンスを購入しますを選択すると右側のサマリー欄にある見積もりからライセンス料分が差し引かれます。
-
インフラストラクチャーを選択します。
READMEの記載(”To install Cloud Pak for Data on IBM Cloud, you must have an IBM Red Hat OpenShift Version 4.3.18 or above single-zone classic cluster on IBM Cloud.”)に従って、クラシックを選択します。

-
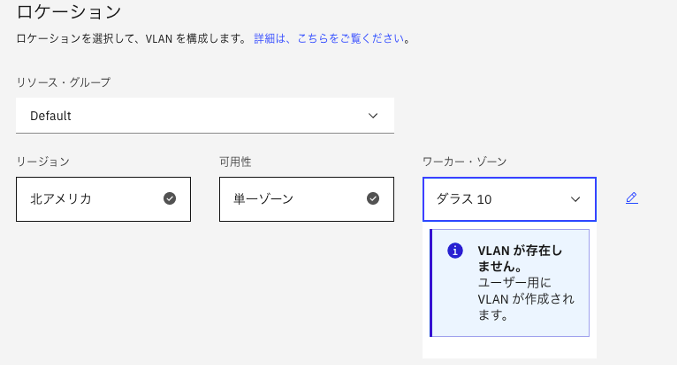
ロケーションを選択します。こちらもREADMEの記載に従い、可用性を「単一ゾーン」にします(リソース・グループは特に管理していなければ「Default」、リージョンとワーカー・ゾーンは任意)。
-
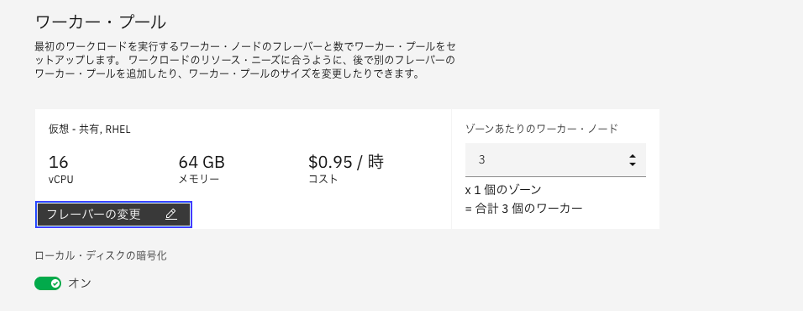
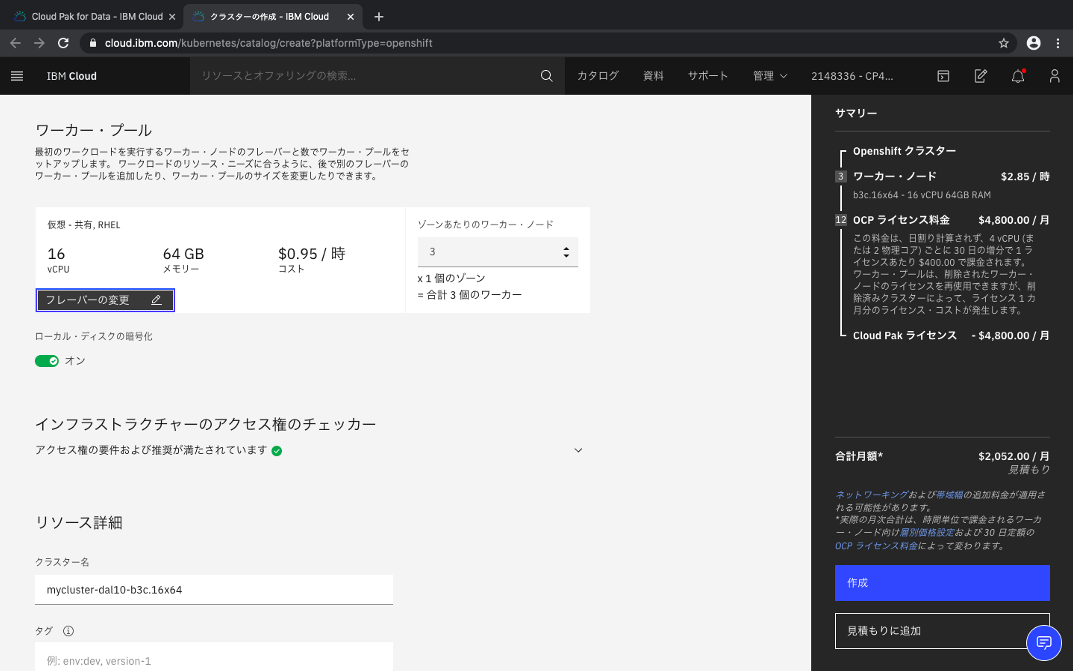
ワーカー・プールを選択します。READMEの記載を確認すると既定では3ノード(Primary Disk 25 GB SSD、Secondary Disk 100GB SSD)、Cloud Pak for Data Controlプレーンのみをインストールするには、6つのVPCが必要で、最小推奨値は、16コア、64 GB RAM、1TB永続ストレージとされています。※この最小限の推奨事項は、すべてのサービスをインストールするのに十分ではありません。インストールする予定のサービスに十分なリソースがあることを確認する必要があります。
-
リソースの詳細を入力します。クラスター名、タグは既定のままで構いません。

-
作成を選択します。
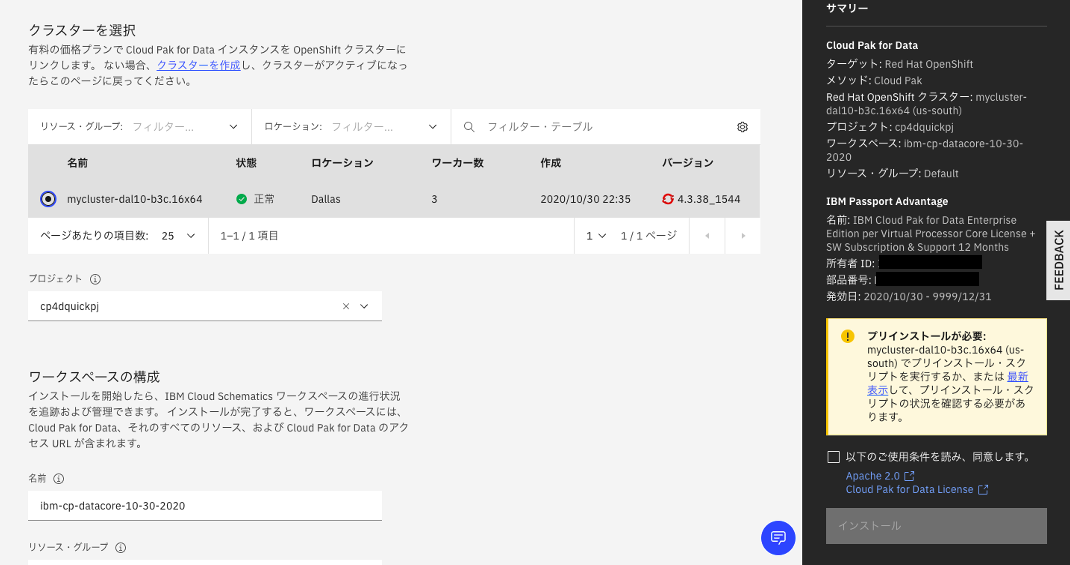
OpenShiftクラスターを選択する。
- Cloud Pak for Dataのインストール画面でOpenShiftクラスターを選択します(プロジェクトとワークスペースの名前は任意)。
プリインストール・スクリプトを実行する。
- スクリプトの実行を選択します。
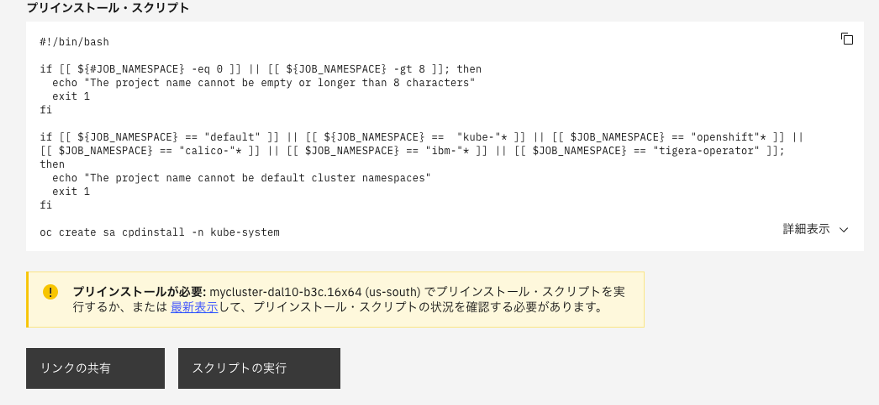
成功すると以下のように表示されます。

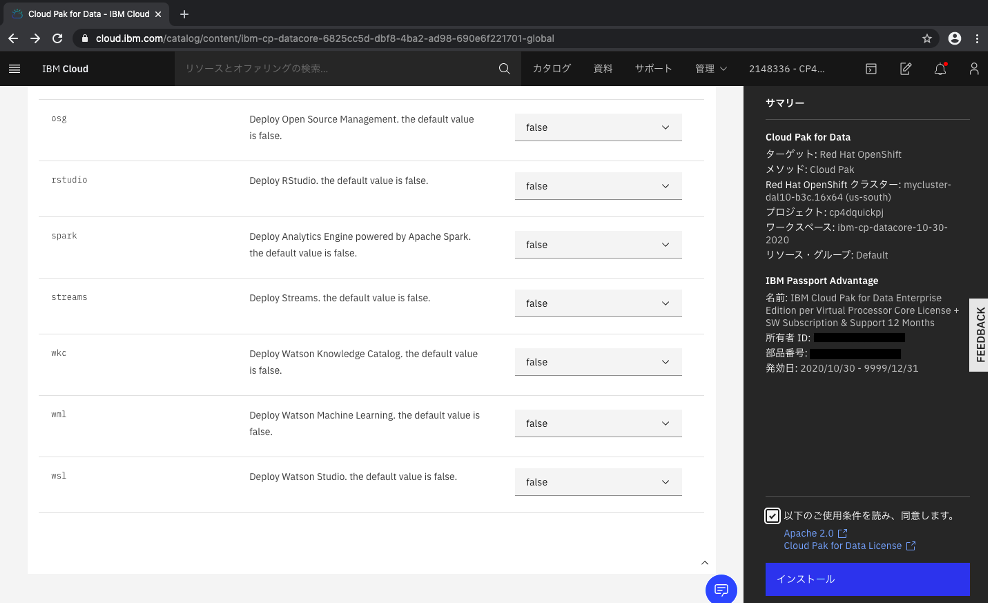
必要なサービスを選択してCloud Pak for Dataのインストールを実行する。
- デプロイメント値の設定で必要なサービスを有効化してインストールすることができます。

今回はすべてFalse(有効化しない)でインストールします。
インストールが完了すると以下の画面が表示されます。
Cloud Pak for Data へのアクセス
- ワークスペースからオファリング・ダッシュボードを選択します。
Cloud Pak for Dataのログイン画面が開きます。

- Cloud Pak for Dataのログイン画面でユーザー名・パスワードを入力します(初期値はユーザー名:admin、パスワード:password)。

Cloud Pak for Dataのホーム画面が開きます。

これでIBM CloudのカタログからクイックにプレーンなCloud Pak for Dataを利用できる環境が整いました。
今後、拡張サービスの導入の試行を行い各サービスで出来ることやユースケースについて別の記事で整理していければと思います。